1.KoBERT 란?
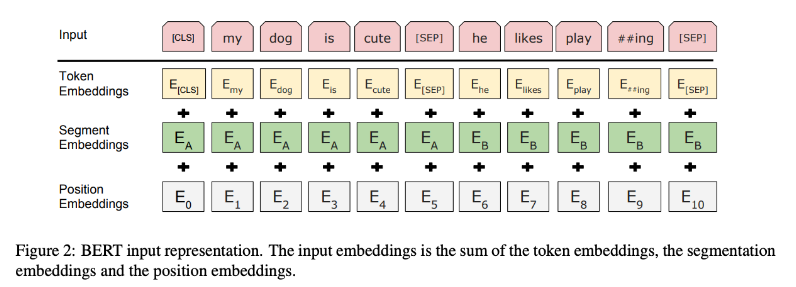
1)BERT란?
KoBERT을 말하기에 앞서, BERT 모델을 우선 소개하고자한다. NLP 분야에서 2019년에 한 학술지에 엄청난 성능을 지닌 모델이 나왔으며 그게 바로 BERT이다. BERT는 Bidirectional Encoder Representations from Transformer 의 약자로 텍스트를 양방향(앞뒤)로 확인하여 자연어를 처리하는 모델이다. 기존의 자연어 처리 모델은 단방향 우리가 글을 읽는 순서인 왼쪽에서 오른쪽으로 갔지만 BERT는 이 순서를 양방향으로 보기 때문에 다른 모델에 비해 매우 높은 정확도를 나타낸다.
또 오픈 소스이기 때문에 누구나 사용할 수 있다는게 장점이다.
BERT는 transformer를 12~24개의 layer로 쌓아놓은 것이다. 그럼 또 transformer가 무엇인지를 알아야 하는데, 기존의 seq2seq 구조인 encoder-decoder 구조를 따르면서도 "Attention is all you need" 논문의 이름처럼 Attention만으로 구현한 모델이다.이 모델은 RNN을 사용하지 않고 encoder-decoder 구조를 설계하였음에도 RNN보다 우수한 성능을 보여준다.
간단히 예시를 들어서 말하면 '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤했기 때문이다' 라는 말이 있을 때 그것이라는 것이 동물인지 길인지 구분할 때 입력 문장 내의 단어들끼리의 유사도를 구함으로써 그것이 동물과 연관되었을 확률이 높은 것을 찾아낼 수 있다.

BERT는 총 3개의 embeding 층이 사용된다. Embedding은 텍스트 데이터를 다루는 애플리케이션에서 중요하게 다뤄지는 핵심 기능들인 Semantic Serach(의미 기반 검색),추천,cluster을 비롯해서 LLM에게 방대한 사전 지식을 주입하여 이를 바탕으로 원하는 결과물을 만들어내도록 한다. Embedding은 텍스트를 실수 벡터 형태로 표현한 결과물이다.
AI모델은 기본적으로 하나의 함수이기 때문에, 기본적으로 숫자 형태의 input만 받을 수 있고, oytput 을 출력할 수 있기 때문에 텍스트를 AI모델이 이해할 수 있는 숫자의 형태로 변형해 주어한다.
또, Embedding을 해야하는 이유는 텍스트의 길이가 일반적으로 매우 길고 , 길이의 가변성 또한 매우 크다는 것이다.AI 모델의 내부 구조상 이렇게 길이가 길고 가변적인 입력값을 다루는데 특화되어 있지 않아서 숫자만으로 구성된 고정된 길이의 입력값인 embedding으로 기존텍스트를 변환하여 AI 모델에게 전달해주어야 한다.
BERT는 Token Embedding, Position Embedding, Token Tupe Embedding으로 이루어져있다.
2)KoBERT란?
KoBERT라는 것은 한국어의 경우 다른 나라의 언어보다 훨씬 더 복잡해서 SKT-brain에서 BERT의 한국어 버전을 만들었다. KoBERT 는 BERT모델에서 한국어 데이터를 추가로 학습시킨 모델로 한국어 위키에서 500만개 문장과 5400만개 단어를 학습시킨 모델이다.
자세한 정보는 https://github.com/SKTBrain/KoBERT 에서 얻을 수 있다. 가면 예시 code도 있어서 활용해볼 수 있다.
((여기까진 분명히 문제가 없었다..ㅠ))
3)KoBERT 예시 실습
환경은 colab에서 진행했다. 환경 변수등이나 data도 불러오기 편해서 이 쪽을 선택했다.
근데 KoBERT 를 사용하려고 하는 과정 중 자꾸 에러가 떴다...ㅠ
우선적으로 github에 있는 예시를 통해 insight 나 코드를 분석을 얻어보려 했는데 왠걸

onnxruntime 에러가 떠서 library문젠가 싶어서 다운을 해보려고 했는데 1.8.0 버전은 pip에 없었다.. 혹시 해결방법 아시는분은 댓글 한번만 알려주시면 감사하겠슴돠....
그래서 나는 huggingface 안에 있는 KoBERT 를 활용해서 진행했다. 그 바람에 코드를 좀 수정해야하는 부분이 있어서 애를 먹었지만 어쩌피 공부도 겸사겸사하는거니깐!!
2.Train 데이터 찾기 및 데이터 전처리
1)데이터 찾기
감성 대화가 labeling 이 된 데이터를 찾다가 AI Hub 에서 감성 대화 말뭉치를 다운로드했다.
https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=86
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
aihub.or.kr

=>데이터 불러오기
import pandas as pd
train = pd.read_excel("C:\\Users\\User\\Desktop\\emotion\\감성대화말뭉치(최종데이터)_Training.xlsx")
valid = pd.read_excel("C:\\Users\\User\\Desktop\\emotion\\감성대화말뭉치(최종데이터)_Validation.xlsx")
엑셀파일로 되있었고, train파일과 valid 파일이 따로 나뉘어져 있어서 따로 train_valid_split 은 안해도 되는 상황이었다.
2)데이터 전처리
=>라벨 인코딩
감성 대화 말뭉치 파일에는 레이블이 기쁨, 분노, 상처, 슬픔, 불안, 당황의 6가지 감성이 있는데 학습에 사용하기 위해 이 레이블들을 숫자로 바꿨다.
# 레이블을 숫자로 매핑하는 딕셔너리
label_mapping = {"기쁨": 0,"분노": 1,"상처": 2,"슬픔": 3,"불안": 4,"당황": 5}
#label encoding
labeld_tr = train
labeld_tr ['emotion'] = train['감정_대분류'].map(label_mapping)
labeld_va = valid
labeld_va['emotion'] = valid['감정_대분류'].map(label_mapping)
=>사람 대화만 활용하기
print(train.columns)
print(valid.columns)
column 을 봤을 때 챗봇의 채팅을 저장한 상황이라서 사람문장만 활용해야해서 사람이 친 채팅 중 2문장만 학습에 사용하기 위해서 통합하여 데이터를 추가해주고 레이블과 통합 채팅 2가지를 제외한 모든 데이터는 삭제했다.
또 전처리가 완료 되면 tsv 형태로 출력하기로 했다.
#사람이 말한 문장만 뽑기
def combine(col1, col2):
result = col1.replace("\n", " ")+" "+col2.replace("\n", " ")
return result
#빈칸 날리기
def cutBlank(em):
result = em.replace(" ", "")
return result
# 레이블을 숫자로 매핑하는 딕셔너리
label_mapping = {"기쁨": 0,"분노": 1,"상처": 2,"슬픔": 3,"불안": 4,"당황": 5}
#빈칸 있어서 날림
train['감정_대분류'] = train.apply(lambda x: cutBlank(x['감정_대분류']), axis=1)
#label encoding
labeld_tr = train
labeld_tr ['emotion'] = train['감정_대분류'].map(label_mapping)
labeld_va = valid
labeld_va['emotion'] = valid['감정_대분류'].map(label_mapping)
labeld_tr['sentences'] = labeld_tr.apply(lambda x: combine(x['사람문장1'], x['사람문장2']), axis=1)
labeld_va['sentences'] = labeld_va.apply(lambda x: combine(x['사람문장1'], x['사람문장2']), axis=1)
labeld_tr.drop(['연령', '성별', '상황키워드', '신체질환','감정_소분류','시스템문장1', '시스템문장2', '사람문장3', '시스템문장3'], axis=1, inplace=True)
labeld_va.drop(['연령', '성별', '상황키워드', '신체질환','감정_소분류','시스템문장1', '시스템문장2', '사람문장3', '시스템문장3'], axis=1, inplace=True)
labeld_tr.to_csv('labeld_train.tsv', sep='\t')
labeld_va.to_csv('labeld_valid.tsv', sep='\t')
여기 까지 진행되면 labeld_train.tsv 파일과 labeld_valid.tsv 파일을 저장할 수 있다.
근데 labeld_train.tsv 파일을 추가적으로 확인해보니 완벽하게 처리가 되지 않았었다. 따라서 emotion과 sentences 만 남기기 위해 추가 전처리 과정을 거쳐야 했다.
import pandas as pd
from gluonnlp.data import TSVDataset
# TSV 파일을 불러오기
file_path = '/content/drive/My Drive/lg/labeld_train.tsv'
data = pd.read_csv(file_path, delimiter='\t')
# 필요한 열을 선택
selected_columns = data[['emotion', 'sentences']]
# 필요한 열만을 포함하는 데이터프레임을 TSV 파일로 저장
selected_file_path_train = '/content/drive/My Drive/lg/selected_labeld_train.tsv'
selected_columns.to_csv(selected_file_path_train, sep='\t', index=False, header=False)
selected_file_path_valid = '/content/drive/My Drive/lg/selected_labeld_valid.tsv'
selected_columns.to_csv(selected_file_path, sep='\t', index=False, header=False)
# 선택된 열을 포함하는 데이터셋을 생성
dataset_train = TSVDataset(selected_file_path_train)
dataset_train = TSVDataset(selected_file_path_valid)

내가 생각하는대로 완성!!
3.Train - code 리뷰
우선적으로 code 는 KoBERT 공식 github 에서 제공하는 colab 을 주로 활용해서 코드를 만들었다.
환경은 아까 말했다시피 colab에서 진행했다. local 에서 진행하려고 하는데 gluonnlp install 에 어려움을 겪어서 추후에 찾아보도록 하겠다.
1)설치해야하는 library
!pip install gluonnlp pandas tqdm
!pip install mxnet
!pip install sentencepiece
!pip install transformers
!pip install torch
!pip install 'git+https://github.com/SKTBrain/KoBERT.git#egg=kobert_tokenizer&subdirectory=kobert_hf'
!pip install numpy==1.23library 에 대한 설명은 생략하고 numpy 은 왜 1.23 을 다운받았냐면 gluonnlp 라이브러리에 호환이 1.23 버전에서 가능해서 버전을 다운그레이드 했다.
2)import 라이브러리
import torch
from torch import nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import gluonnlp as nlp
import numpy as np
from tqdm import tqdm
import torch.nn.functional as F
from kobert_tokenizer import KoBERTTokenizer
from transformers import BertModel
from transformers import AdamW
from transformers.optimization import get_cosine_schedule_with_warmup
라이브러리에 대한 자세한 설명은 생략하겠다.
3)GPU 사용을 위해서 장치 선택
# GPU든 CPU든 사용 가능한 장치를 선택
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using {} device".format(device))GPU든 CPU든 사용가능한 장치를 선택하는 코드이다.
colab pro환경에서 진행하고 있어서 cpu 는 사용할일이 크게 없다.
4)KoBERT 모델 불러오기
# KoBERT 모델을 불러오기
bertmodel = BertModel.from_pretrained('skt/kobert-base-v1')
# BERT 모델을 위한 tokenizer를 불러오기
tokenizer = KoBERTTokenizer.from_pretrained('skt/kobert-base-v1')pretrained 된 모델을 불러와서 추가학습할 예정이다.
5)BERTDataset 에 맞게 처리하는 클래스
# 데이터셋을 불러오고 처리하는 클래스를 정의
class BERTDataset(Dataset):
def __init__(self, dataset, tokenizer, max_len):
self.tokenizer = tokenizer
self.max_len = max_len
self.sentences = [i[1] for i in dataset]
self.labels = [np.int32(i[0]) for i in dataset]
def __getitem__(self, i):
sentence = self.sentences[i]
label = self.labels[i]
encoding = self.tokenizer.encode_plus(
sentence,
add_special_tokens=True,
max_length=self.max_len,
padding='max_length',
truncation=True,
return_tensors='pt'
)
return {
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
def __len__(self):
return len(self.labels)
기본코드는 github에 있지만 github 코드에서 내가 필요한 부분에 맞게 수정했다.
BERTDataset 은 BERT 모델을 사용하여 텍스트 데이터셋을 처리하기 위해서 만들었다. 이 클래스는 3가지 매개변수를 받는데.
dataset:처리할 데이터셋으로 텍스트와 해당레이블로 구성된 튜플의 리스트로 가정한다.
tokenizer:BERT모델에 사용할 tokenizer
max_len: 문장의 최대 길이을 받아온다.
dataset 에는 sentences 와 label을 받아오는데 , 위의 출력값을 통해 emotion 랑sentences 이 순으로 지정되있기 때문에 sentences는 i[1] , labels는 i[0] 으로 불러왔다.
getitem 에서는 주어진 인덱스에 해당하는 데이터를 반환해 문장을 토큰화하고 BERT 입력 형식에 맞게 변환한다.
또 변환된 입력을 dictionary 형태로 반환하는데, 이 딕셔너리는 'input_ids'(토큰화된 입력), 'attention_mask'(어텐션 마스크), 'labels'(레이블)을 포함한다.
len은 데이터셋의 총길이를 반환한다. 데이터셋의 문장수를 반환한다.
6)데이터 불러오기
# 파라미터를 설정
#max_len:입력 시퀀스의 최대길이. BERT 모델에 입력될때 시퀀스의 값으로 제한
#batch_size:한번에 모델 입력되는 데이터 샘플 수
#num_epochs:전체 데이터셋 학습하는 에폭의 수
#learning_rate: 학습률
max_len = 128
batch_size = 32
num_epochs = 10
learning_rate = 5e-5
# 데이터 파일 경로를 설정
selected_file_path_train = '/content/drive/My Drive/lg/selected_labeld_train.tsv'
selected_file_path_valid = '/content/drive/My Drive/lg/selected_labeld_valid.tsv'
# 데이터셋 로드
dataset_train = nlp.data.TSVDataset(selected_file_path_train)
dataset_test = nlp.data.TSVDataset(selected_file_path_valid)
# 데이터셋을 BERT 형식으로 변환
data_train = BERTDataset(dataset_train, tokenizer, max_len)
data_valid = BERTDataset(dataset_test, tokenizer, max_len)
# 데이터로더를 생성
train_dataloader = DataLoader(data_train, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(data_valid, batch_size=batch_size, shuffle=False)
for batch in train_dataloader:
print(batch)
break # 첫 번째 배치만 확인하기 위해 반복문 종료
데이터를불러오고, 데이터셋을 위에서 정의한 BERTDataset에 맞게 변환했다. 파라미터는 github에서 제공하는 기본 파라미터를 사용했다.
7)BERT 분류기 모델 정의
# BERT 분류기 모델을 정의
class BERTClassifier(nn.Module):
def __init__(self, bert, hidden_size=768, num_classes=6, dr_rate=None):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dr_rate = dr_rate
self.classifier = nn.Linear(hidden_size, num_classes)
if dr_rate:
self.dropout = nn.Dropout(p=dr_rate)
def forward(self, input_ids, attention_mask):
output = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = output['pooler_output']
if self.dr_rate:
pooled_output = self.dropout(pooled_output)
return self.classifier(pooled_output)
# BERT 분류기 모델을 생성
model = BERTClassifier(bertmodel).to(device)
BERTClassifier 클래스는 BERT 모델을 분류기로 학습시키기 위한 과정으로 맞춰나갔다.
__init__ 메서드에서는 네 가지 매개변수를 받는다.
bert: BERT 모델. pretrained_model.
hidden_size: BERT 모델의 hidden layer.
num_classes: 분류할 클래스의 수. 우리는 감정이 6가지로 나눴으므로 6이다.
dr_rate: 드롭아웃 비율.
드롭아웃은 모델이 과적합하지 않도록 학습 중에 무작위로 일부 뉴런을 비활성화하는 기술이다.
기본값은 None으로, 드롭아웃을 사용하지 않음을 의미.
forward 메서드는 모델 순전파를 의미한다.
입력으로 주어진 input_ids와 attention_mask를 사용하여 BERT 모델에 전달하면 BERT 모델의 출력에서 pooler_output을 가져온다. 이는 BERT 모델의 첫 번째 풀링 레이어에서 나온 출력이다.
만약 dr_rate가 주어졌다면 드롭아웃을 적용하고,드롭아웃을 적용한 후, 선형 레이어를 통해 최종 분류를 수행한다.
BERTClassifier의 인스턴스를 생성할 때는 미리 학습된 BERT 모델을 매개변수로 전달한다. 이 모델은 이미 사전에 학습된 상태로, 텍스트 피쳐를 추출하는 역할을 한다.
모델은 주어진 문장을 입력으로 받아 해당 문장의 클래스를 예측하는 데 사용된다.
8)optimizer 와 loss function 정의
# 옵티마이저와 손실 함수를 정의합니다.
optimizer = optim.AdamW(model.parameters(), lr=learning_rate)
loss_fn = nn.CrossEntropyLoss()Optimizer로 AdamW를 선택했고 다중 분류를 위한 loss function으로 CrossEntropyloss 를 선택했다.
Optimizer는 딥러닝 학습시 최대한 틀리지 않은 방향으로 학습해야 한다.
얼마나 틀리는지 loss 를 알게 하는 함수는 loss function이다. loss function의 최솟값을 찾는 것을 학습 목표로 한다. 최소값을 찾아가는 것을 최적화 =Optimization. 이를 수행하는 알고리즘이 Optimizer이다.
CrossEntropy 는 분류에서 대표적으로 사용하는 loss function이다.

Cross-Entropy loss의 정의는 위와 같다. nn.CrossEntropyLoss()는 내부적으로 softmax 함수가 포함되어있다.
9)모델 학습 및 저장
# 모델을 학습
for epoch in range(num_epochs):
model.train()
total_loss = 0
for batch in tqdm(train_dataloader, desc="Epoch {}".format(epoch + 1)):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
# 에폭마다 손실을 출력
avg_loss = total_loss / len(train_dataloader)
print("Epoch {} Loss: {:.4f}".format(epoch + 1, avg_loss))
# 모델을 저장
torch.save(model.state_dict(), 'model_state_dict.pt')
모델을 학습하는 과정이다.
num_epochs는 10번으로 위에 설정해놨다.
학습데이터셋을 mini-batch로 나누어서 반복한다. tqdm은 반복문의 진행상황을 시각적으로 보여주는 함수이다.
input_ids, attention_mask, labels는 미니배치의 입력 데이터, 어텐션 마스크, 레이블이고
optimizer.zero_grad(): 옵티마이저의 그라디언트를 초기화한다.
outputs = model(input_ids, attention_mask): 모델에 입력을 전달하여 출력을 계산한다.
loss = loss_fn(outputs, labels): 출력과 실제 레이블 간의 손실을 계산한다.
loss.backward(): 역전파를 수행하여 그라디언트를 계산한다.
optimizer.step(): 옵티마이저를 사용하여 파라미터를 업데이트한다.
에폭 내에서의 총 손실을 계산하고 출력한다.
학습이 완료된 모델을 저장할 수 있다.
10)전체 sourcecode
import torch
from torch import nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import gluonnlp as nlp
import numpy as np
from tqdm import tqdm
import torch.nn.functional as F
from kobert_tokenizer import KoBERTTokenizer
from transformers import BertModel
from transformers import AdamW
from transformers.optimization import get_cosine_schedule_with_warmup
# GPU든 CPU든 사용 가능한 장치를 선택
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using {} device".format(device))
# KoBERT 모델
bertmodel = BertModel.from_pretrained('skt/kobert-base-v1')
# 데이터 파일 경로를 설정
selected_file_path_train = '/content/drive/My Drive/lg/selected_labeld_train.tsv'
selected_file_path_valid = '/content/drive/My Drive/lg/selected_labeld_valid.tsv'
# 데이터셋을 불러오고 처리하는 클래스를 정의
class BERTDataset(Dataset):
def __init__(self, dataset, tokenizer, max_len):
self.tokenizer = tokenizer
self.max_len = max_len
self.sentences = [i[1] for i in dataset]
self.labels = [np.int32(i[0]) for i in dataset]
def __getitem__(self, i):
sentence = self.sentences[i]
label = self.labels[i]
encoding = self.tokenizer.encode_plus(
sentence,
add_special_tokens=True,
max_length=self.max_len,
padding='max_length',
truncation=True,
return_tensors='pt'
)
return {
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
def __len__(self):
return len(self.labels)
# 파라미터를 설정
max_len = 128
batch_size = 32
num_epochs = 10
learning_rate = 5e-5
# BERT 모델을 위한 토크나이저를 불러오기
tokenizer = KoBERTTokenizer.from_pretrained('skt/kobert-base-v1')
# 데이터셋을 로드
dataset_train = nlp.data.TSVDataset(selected_file_path_train)
dataset_test = nlp.data.TSVDataset(selected_file_path_valid)
# 데이터셋을 BERT 형식으로 변환
data_train = BERTDataset(dataset_train, tokenizer, max_len)
data_valid = BERTDataset(dataset_test, tokenizer, max_len)
# 데이터로더를 생성
train_dataloader = DataLoader(data_train, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(data_valid, batch_size=batch_size, shuffle=False)
# BERT 분류기 모델을 정의
class BERTClassifier(nn.Module):
def __init__(self, bert, hidden_size=768, num_classes=6, dr_rate=None):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dr_rate = dr_rate
self.classifier = nn.Linear(hidden_size, num_classes)
if dr_rate:
self.dropout = nn.Dropout(p=dr_rate)
def forward(self, input_ids, attention_mask):
output = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = output['pooler_output']
if self.dr_rate:
pooled_output = self.dropout(pooled_output)
return self.classifier(pooled_output)
# BERT 분류기 모델을 생성
model = BERTClassifier(bertmodel).to(device)
# 옵티마이저와 손실 함수를 정의
optimizer = optim.AdamW(model.parameters(), lr=learning_rate)
loss_fn = nn.CrossEntropyLoss()
# 모델을 학습
for epoch in range(num_epochs):
model.train()
total_loss = 0
for batch in tqdm(train_dataloader, desc="Epoch {}".format(epoch + 1)):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
# 에폭마다 손실을 출력
avg_loss = total_loss / len(train_dataloader)
print("Epoch {} Loss: {:.4f}".format(epoch + 1, avg_loss))
# 모델을 저장
torch.save(model.state_dict(), 'model_state_dict.pt')생각보다 학습하는 과정에 시간이 많이 소요된거같다. (2시간 정도 소요)
loss 도 안정적으로 떨어지는것을 확인할 수 있었다.

3.모델 검증
# 모델을 불러오기
model = BERTClassifier(bertmodel).to(device)
model.load_state_dict(torch.load('/content/drive/MyDrive/lg/model_state_dict.pt'))
model.eval()
# 검증 데이터셋에 대한 예측을 수행
predictions = []
true_labels = []
for batch in tqdm(test_dataloader, desc="Evaluating"):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels']
with torch.no_grad():
outputs = model(input_ids, attention_mask)
predictions.extend(torch.argmax(outputs, axis=1).cpu().numpy())
true_labels.extend(labels.numpy())
# 예측값과 실제 레이블을 비교하여 평가 지표를 계산.
from sklearn.metrics import accuracy_score, classification_report
accuracy = accuracy_score(true_labels, predictions)
report = classification_report(true_labels, predictions)
print("Accuracy:", accuracy)
print("Classification Report:\n", report)모델을 다시 불러와서 평가지표를 확인했다.

총 정확도는 76 % 정도 였다.
각 분류별 정확도를 확인해봤을 때 상처에 대한 감정의 정확도가 많이 낮음을 확인할 수 있었다.
'project > 개인공부' 카테고리의 다른 글
| VLAN 과 VXLAN이란? (0) | 2024.09.10 |
|---|---|
| 2022년도 Melon가사 분석을 통한 감정분류 (0) | 2024.04.01 |
| 생성형 AI 란 무엇인가? (0) | 2024.02.11 |
| GIT 사용법 (2) | 2024.01.26 |
| 기본정렬 알고리즘 (Sorting 기법 정리(Bubble,Selection,Quick,Heap,Insertion,Merge)) (1) | 2024.01.02 |



