1.Docker설치
docker를 설치하면 좋은점
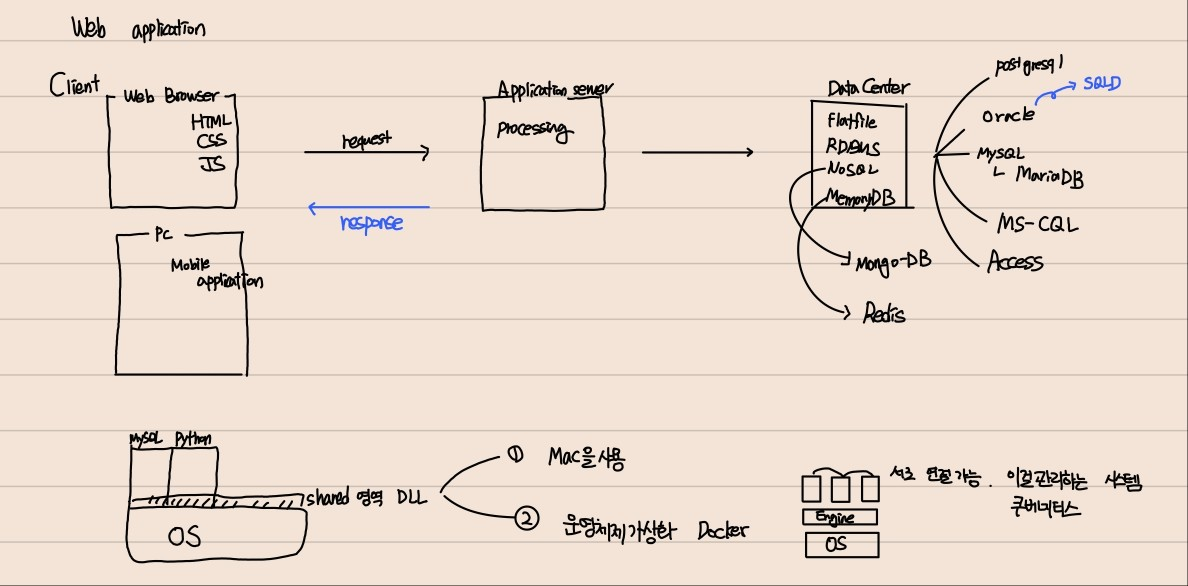
그림에서 보다시피 Windows 환경에서 shared영역이 존재하다보니 충돌이 일어날 가능성이 존재.
따라서 Docker를 활용하거나 Mac OS을 사용.
2.mysql 도커에 설치
1)mysql 컨테이너 실행
docker run --name mysql -dit -e MYSQL_ROOT_PASSWORD=**** -e MYSQL_DATABASE=**** -e MYSQL_USER=**** -e MYSQL_PASSWORD=****-p 3306:3306 mysql --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --default-authentication-plugin=mysql_native_password
docker run:컨테이너 생성
-dit(demon=background) : background 일은 하는데 내 눈에는 안보이는것
forground 내눈에 보이는걸 수행
-e:환경변수
2)접속도구를 설치하고 접속
=>dbeaver(데이타베이스 접속도구) 설치
https://dbeaver.io/downloads
Hosting migration | DBeaver Community
Hosting migration Due to a very high traffic we can’t keep DBeaver downloads on the single host anymore. Since today (Nov 4 2020) all binaries are located in the CDN cloud (download.dbeaver.com). For most users it will improve download performance. Howev
dbeaver.io
3.windows function
관계형 데이터베이스에서 group by를 사용할 때 주의할 점
tStaff 테이블을 depart별로 depart와 salary의 평균을 조회- group by는 그룹화 한 항목 별로 하나만 출력할 수 잇는데 salary는 2개 이상이 될수도 있어서 어떤 것을 출력할지몰라서 에러인데 mysql의 fork인 maria_db에서는 이 문법을 허용
select depart,avg(salary)
from tStaff
group by depart; --는 가능
select depart,salary
from tStaff
group by depart; --오류
=>그룹 별 집계나 비집계 함수를 사용할 수 있는 함수
1)사용 형식
SELECT <윈도우함수이름> (매개변수) OVER(
[PARTITION BY 그룹화 항목 나열]
ORDER BY 정렬할 항목
출력할 칼럼이름 나열
FROM 테이블 이름
WHERE 조건;
=>partition은 선택인데 그룹을 만드는 것
=>partition이 없으면 전체 데이터를 가지고 수행
2)순위 관련 함수
=>ROW NUMBER: 중첩되지 않은 일련번호
=>DENSE RANK:중복된 순위에 동일한 순위를 할당하고 다음 순위를 건너뛰지 않고 리턴
=>RANK:중복된 순위에 동일한 순위를 할당하고 다음 순위를 건너뛰고 리턴
=>NTITLE:등분
=>실습
#usertbl 테이블에서 나이가 많은 순서대로 name과 birthyear 조회
#중복된 순위는 허용하지 않고 조회
SELECT ROW_NUMBER() OVER(ORDER BY birthyear DESC)'나이가 적은 순서',name,birthyear
from usertbl;
#나이를 3등분
SELECT NTILE(3) OVER(ORDER BY birthyear DESC)'나이가 적은 순서',name,birthyear
from usertbl;
#addr 별로 그룹화해서 순위를 조회
SELECT ROW_NUMBER() OVER(PARTITION BY addr ORDER BY birhyear DESC)'나이가적은순서',addr,name,birthyear from usertbl;
=>groupby 와 partition by의 차이점은 group by는 그룹 당 하나의 데이터를 출력하지만 partition by 행단위로 전부 출력
#usertbl 테이블에서 addr별로 그룹화해서 birthyear가 큰 순서대로 name과 birthyear 조회
#중복된 순위는 허용하되 다음 순위는 건너 뛰도록 조회
select RANK() OVER(
PARTITION BY addr ORDER BY birthyear DESC)
'순위',name,birthyear,addr
FROM usertbl;
트랜잭션(Transaction)이란?
한 번에 이루어져야 하는 작업의 논리적인 단위
All or nothing 다되거나 아예 안되거나
A라는 애가 iterm을 하나 가지고 있음. 내 현재 잔액은 3000
B는 아이템 없고 7000
A가 B에게 iterm을 3000원에 판매하고 싶음 여기서는 실제로 4가지 동작이 이루어짐 transaction 1개
1번 동작 A item이 false update*1 가 되고2번 B는 true update*1 3번A잔액 +3000 4번B는 -3000
CRUD에서 CUD 는 하나씩 수행됨 R은 동시에 해도됨
1~4번 동작이 한꺼번에 수행되도록 만들어줘야함. 하고 나서 commit-> 하나의 트랜잭션으로 사용해야함
rollback은 동작 아예 시작전으로 돌아가주세요
commit은 동작을 끝내주세요
은행은 매 동작마다 commit을 할 수 없음 따라서 savepoint를 해놓음=> 전부다 rollback 할 이유가 없음
데이터베이스 3개로 나눌떈
DDL,DML,DCL로 나뉨
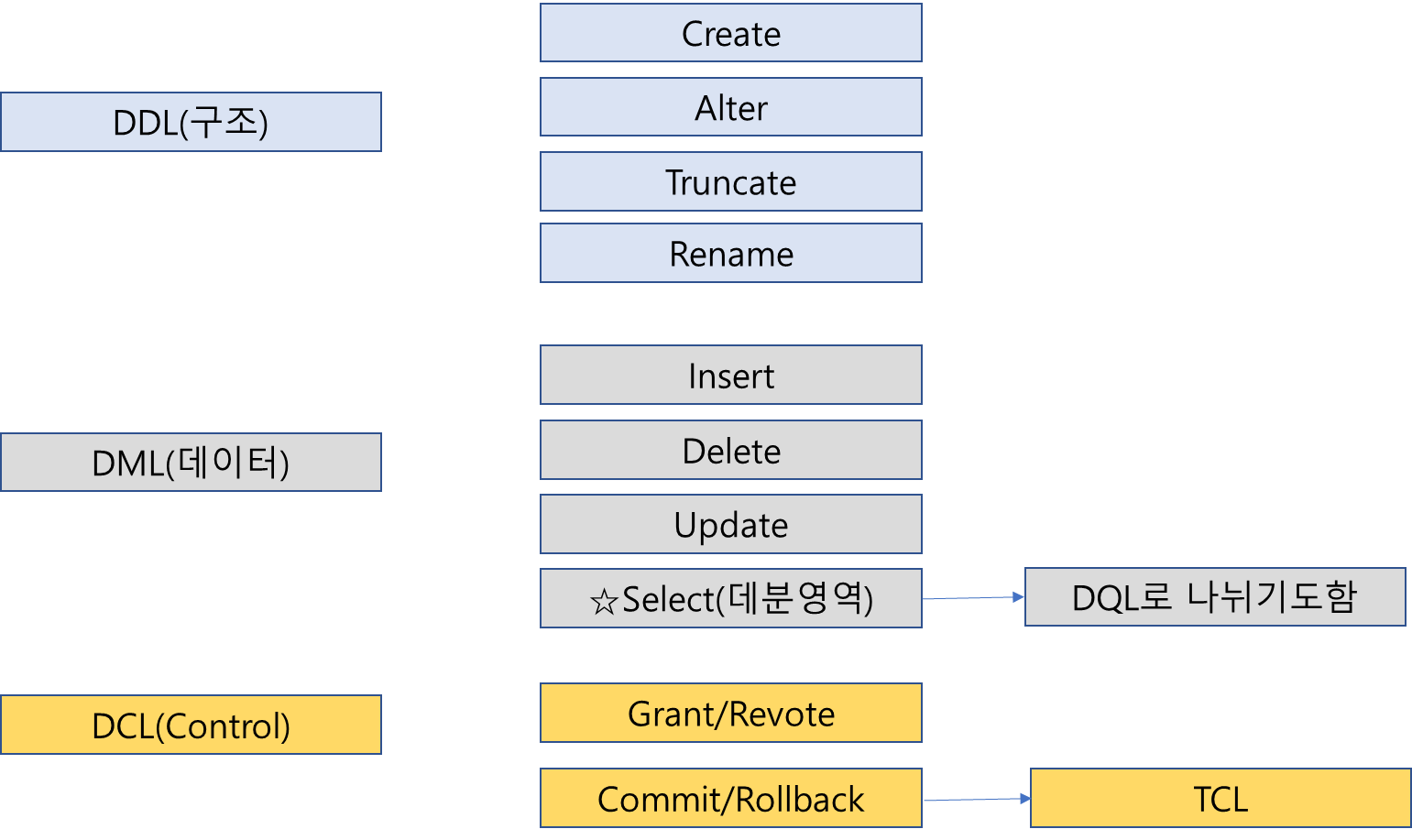
Auto commit: sql문이 성공할때마다 자동 commit
Manual commit:sql문 성공하고 나서 수동 commit
DDL,DCL은 auto commit => 이 두언어는 관리자나 운영자의 언어로 바로바로 적용이 되어야 하기 떄문
정상종료도 auto commit 비정상종료는 Rollback
Transaction의 생성은 여러분이 commit이나 rollback된 후 DML을 수행(Select은 제외)
3)분석함수
=>CUME_DIST():누적합
=>LEAD(컬럼,인덱스):다음행
=>LAG(컬럼,인덱스):이전행
=>FIRST_VALUE(컬럼):첫 행
=>LAST_VALUE(컬럼):마지막 행
=>PERCENT_RANK():백분울 순위
실행순서
5 SELECT
1 FROM
2 WHERE
3 GROUP BY
4 HAVING
6 ORDER BY
데이터베이스 모델링
1)종속
=>다른 데이터의 영향을 받는 것
중복 최소화 - 어쩔수 없이 해야할 경우가 있음 ex.) 백업파일
종속 최소화 == 느슨한 구성
=>함수적 종속(FD)
하나의 속성이 다른 하나의 속성의 값을 결정하는 것
ex.)주민등록번호 - >이름
주민등록번호가 이름을 함수적으로 종속했다
주민등록번호 부분을 결정자
=> 부분함수 종속(기본키에서만 적용)
두개 이상의 속성으로 만들어진 기본키에서 한개의 속성으로 구별할 수 있는 경우
학번+수강과목코드을 하면 절대 중복되지 않음 이걸 기본키로 만들어.
기본키가 2개이상의 키로 만들어졌을때 하나의 키로만 사람을 구분할 수 있는 경우(학번만 봐도 구분가능)
=>이행적 함수 종속
A->B
=>A->C
B->C
정규화
테이블을 쪼개서 데이터를 삽입, 갱신, 삭제 하는 경우를 좀 더 자유롭게 해줌.BUT 읽기 속도가 느림
반정규화,역정규화
정규화한 테이블에서 JOIN할때 속도가 느림. 읽을때는 테이블을 쪼개지 않고 하나의 테이블로 이용해서 읽은게 더 좋음
'Study > Database' 카테고리의 다른 글
| Docker를 이용해서 Oracle 설치 (0) | 2024.02.15 |
|---|---|
| NoSQL (0) | 2024.01.23 |
| SQL(3)-뷰, 인덱스, 스토어드 프로시저, 트리거 (0) | 2024.01.15 |
| SQL(2)-데이터 형식 및 조인 종류 (0) | 2024.01.12 |
| 파이썬과 MySQL 연동하기 (0) | 2024.01.11 |



