이미지 세그멘테이션(image segmentation)은 이미지의 모든 픽셀이 어떤 카테고리에 속하는지 분류하는 것을 말합니다.
이미지 전체에 대해 단일 카테고리를 예측하는 이미지 분류(image classifcation)과는 달리, 이미지 세그멘테이션은 픽셀 단위의 분류를 수행하므로 일반적으로 더 어려운 문제로 인식되고 있습니다.
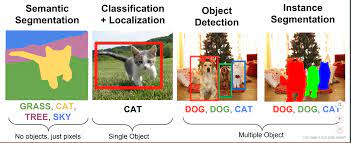
위 그림에서 segmentation은 이미지 내에 존재하는 객체들을 의미 있는 단위로 분할해내는 것이고, instance segmentation은 같은 카테고리에 속하는 서로 다른 객체까지 더 분할하여 semantic segmentaion 범위를 확장해나갔습니다.
이번에 본 논문은 U-NET:Convolution Networks for Biomedical Image Segmentaion으로 앞으로 제가 할 프로젝트 관련해서 사용될 모델이라 분석해봤습니다.
U-Net은 이미지 세그멘테이션을 목적으로 제안된 End-to-End 방식의 Full-Convolutional Network 기반 모델입니다.
1.Full-Convolutional Network이란?
Full-Connected Network 은 합성곱 신경망이라고도 불립니다. 기본의 CNN(Convolutional Neural Network)은 입력 이미지를 각기 다른 레이어로 전달하여 점진적으로 특징을 추출한 후,마지막에 Softmax layer로 클래스 확률을 출력하는 구조를 가지고 있습니다. 반면에 Fully Convolutional Network은 입력이미지를 픽셀 단위로 분류하는 이미지 분할 작업에 특화된 구조입니다. FCN은 일반적인 CNN의 특징 추출 부분을 유지하면서 마지막 레이어를 완전 합성곱 레이어로 변경하여 원본이미지의 공간적인 정보를 보존할 수 있도록 합니다. 이를 통해 각 픽셀에 대한 클래스 레이어를 예측하게 됩니다. FCN은 입력 이미지의 크기에 따라 유연하게 대응이 가능하며 , 특정 객체나 물체의 경게를 정확하게 분할할 수 있는 장점을 가지고 있습니다.
2.U-Net 이란?
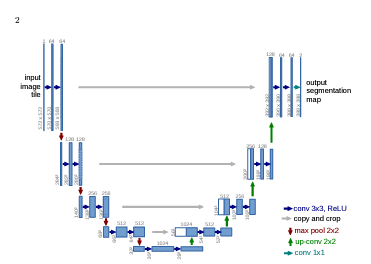
U-Net은 네트워크 구성의 형태로 인해 U-Net이라는 이름이 붙여졌습니다. U-Net은 이미지의 전반적인 컨텍스트 정보를 얻기 위한 네트워크와 정확한 Localization을 위한 네트워크가 대칭 형태로 구성되어 있습니다.
deep convolutional network은 visual recognition task에 강점을 가지고 있었습니다. 이러한 network의 task은 특히 이미지로 부터 하나의 클래스를 예측하는 거였으나, 다른 visual task에서는 localization 을 포함한 출력이 필요했습니다. 기존에는 이러한 문제를 해결하기 위해서 sliding-window 방법을 적용하여 local region을 제공하여 각 픽셀의 라벨을 예측했습니다.이 방법에는 두가지 단점이 있는데 각 patch 별로 개별적으로 수행하며 overlapping 되어 느리다는 점입니다. 또 localization accuracy와 context 간의 trade-off 관계가 있단느 것입니다. patch가 클수록 max-pooling layer 가 더 필요한데 이는 localization accuracy를 감소시키고 작은 patch는 network가 조금의 context만 보게 할 것입니다.
U-Net은 효과적인 segmentation을 위해 새로운 architecture를 제안합니다. 데이터의 차원을 축소했다가 다시 확장하는 방식으로 auto encoder와도 유사한 점이 있습니다.
U-Net의 핵심개념
모델은 크게 contracting path(left side), expansive path(right side)으로 구성되어 있습니다. Contracting Path은 입력 이미지의 Context 포착을 목적으로 구성되어 있어 일반적인 CNN layer을 적용합니다. Contracting path에서는 down-sampling이 발생하는데 pooling 하기 전의 feature map 을 upsampling할때 결합하여 high -resolution 한 출력을 만들 수 있습니다. 이는 localization에 크게 도움이 됩니다. 또한 upsampling 사이에 많은 feature channel을 사용하는데 이는 contracting path 에서 얻은 context information을 higher resolution layer에 전파할 수 있게 합니다.
Contracting Path
U-Net 구조 중 왼쪽에 존재하는 down sampling 과정을 의미합니다. 다시말하자면 일반적인 cnn layer 기법을 사용하는데 이 과정을 통해 image context 추출할 수 있습니다. 논문에서는 padding 과정 없이 3X3 filter 를 두차례 반복하며 ReLU를 활성화 시켰습니다.그리고 2x2 max pooling(stride:2)을 적용해 down sampling을 하였습니다. 각 down sampling에서는 2배의 feature channel수를 사용했습니다.
Extending Path
Extending Path 에서는 Contracting Path의 최종 특징 맵으로부터 보다 높은 해상도의 Segmentation 결과를 얻기 위해 몇 차례의 Up-sampling을 진행합니다. 따라서 context 로 부터 localize하는 역할을 수행합니다. 구체적으로 2x2 filter(up-convolution)을 사용하며 feature channel을 반으로 줄입니다. 그리고 얻어진 결과에 contracting path 에서 얻은 feature map 의 border 부분을 crop하며 concat합니다. 이후에 3x3 filter 두번과 ReLU를 적용하고 마지막으로 1x1 filter을 적용하여 분류 클래스에 매핑합니다.추가적으로 cnn연산에서 padding이 없기 때문에 입력 사이즈가 출력 사이즈보다 큽니다. 이러한 과정을 통해 segmentation이 내재하는 localization과 Context 사이의 트레이드 오프를 해결할 수 있습니다. 주목해야할 점은 최종 출력인 Segmentation map의 크기는 Input Image크기보다 작다는 것입니다. Convolution연산에서 패딩을 사용하지 않았기 때문입니다.
Overlap-Title Input

Fully convolutional network 구조의 특성상 입력 이미지의 크기에 제약이 없습니다. 따라서U-Net에서는 크기가 큰 이미지의 경우 이미지 전체를 사용하는 대신 큰 입력 이미지에 대해 overlap-title 전략을 활용합니다. 이는 파랑색 박스 크기의 패치 단위로 잘라서 입력으로 사용되며 실제 segmentation되는 부분은 노란색 부분입니다. 타일이 이동하면서 segmentation 할 때 이전 입력의 일부분도 포함되기 때문에 overlap-tile입니다. 이렇게 하면 가장자리에 대해 여백이 남는 것을 볼 수 있습니다. 이를 보정하여 왼쪽 그림처럼 mirroring하였습니다.
Touching cells separation
논문에서 세포 분할 작업에서 주요한 과제 중 하나는 동일한 클래스의 접촉 개체를 분리하는 것입니다.닿아있는 세포 사이의 경계 부분을 분리하기 위해 사전에 학습된 가중치 맵을 사용합니다.

a는 raw image 이고 b는 실제 세분화로 오버레이된 사진입니다.다른 색상은 HeLa 셀의 다른 인스턴스를 나타냅니다. c와 d와 같이 각 세포 사이의 경계를 포착해야하는데, 이를 위해 학습 데이터에서 각 픽셀별 클래스 분포가 다른 점을 고려하여 사전에 Ground -Truth 에 대한 weight map을 구해 학습에 반영하였습니다.

이 외에도 elastic deformation등의 augmentation기법을 통해 성능을 높였습니다.
코드
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
import random
import math
from sklearn.utils import shuffle
from sklearn.metrics import confusion_matrix
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.nn import init
from torch.utils.data import DataLoader,Dataset
from torch.autograd import Variable
from albumentations.augmentations import transforms
from albumentations.pytorch import ToTensor, ToTensorV2
from albumentations.core.composition import Compose, OneOf
from PIL import Image
# 사용자 정의
import preprocess
import utils
import models
import evaluation as ev
위는 사용한 패키지들입니다.
# custom dataset
class Dataset(Dataset):
def __init__(self, data_path, mode =None, transform=None):
self.data_path = data_path
self.transform = transform
self.mode = mode
"""tiff 파일 읽기"""
self.inputs = utils.read_tiff(self.data_path+'train-input.tif')
self.labels = utils.read_tiff(self.data_path+'train-labels.tif')
"""train/val 분리"""
idx = utils.set_index(len(self.inputs), 0.7, self.mode)
self.inputs = self.inputs[idx]
self.labels = self.labels[idx]
def __len__(self):
return len(self.inputs)
def __getitem__(self, index):
inputs = self.inputs[index]
labels = self.labels[index]
inputs = inputs/255
labels = labels/255
"""gray image channel 추가"""
if labels.ndim == 2:
labels = np.expand_dims(labels, -1)
if inputs.ndim == 2:
inputs = np.expand_dims(inputs, -1)
"""augmentation 적용"""
if self.transform is not None:
augmented = self.transform(image = inputs, mask = labels)
inputs, labels = augmented['image'],augmented["mask"]
inputs = torch.from_numpy(inputs).permute(2,0,1)
labels = torch.from_numpy(labels).permute(2,0,1)
return inputs, labelscuston dataset을 생성합니다. 30장 중 22장은 학습, 8장은 검증용으로 사용합니다.
def make_transform(mode):
if mode == 'train':
train_transform = Compose([
transforms.Resize(height = 512, width = 512),
OneOf([transforms.MotionBlur(),
transforms.OpticalDistortion(),
transforms.GaussNoise(p = 0.5),
transforms.RandomContrast()]),
transforms.ElasticTransform(),
OneOf([transforms.HorizontalFlip(),
transforms.RandomRotate90(),
transforms.VerticalFlip()]), # oneof에 p 부여 가능,
transforms.Normalize((0.5), (0.5))
])
return train_transform
else:
test_transform = Compose([
transforms.Resize(height = 512, width = 512),
transforms.Normalize((0.5), (0.5))
])
return test_transform데이터셋에서 image augmentation을 한 함수입니다. 검증에는 augmentation을 수행하지 않고 기본적인 사이즈와 normalization만 수행합니다. noise,blur,회전 등을 사용하고 특히 elastic deformation이 성능향상에 큰 역할을 했습니다.
class DoubleConv(nn.Module):
"""반복되는 conv - BN - ReLU 구조 모듈화"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=False):
super().__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels , in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits위 코드는 U-Net 모델을 구현한 코드입니다. 우선 doubleconv는 반복되는 conv-bn-relu 구조를 블럭화한 것입니다. down은 축소 부분 up은 확장부분입니다. 다만 확장을 할 때 기존 down 부분의 축소된 feature map을 더해주는 것을 볼 수 있습니다. 이는 Unet의 forward의 self.up() 부분에서 들어가는 인자를 보면 확인할 수 있습니다. 학습을 할 때는 메모리 문제로 위의 channel 차원보다 작게 진행했습니다.
"""가중치 초기화"""
def weights_init(init_type='xavier'):
def init_fun(m):
classname = m.__class__.__name__
if (classname.find('Conv') == 0 or classname.find('Linear') == 0) and hasattr(m, 'weight'):
if init_type == 'normal':
init.normal_(m.weight.data, 0.0, 0.02)
elif init_type == 'xavier':
init.xavier_normal_(m.weight.data, gain=math.sqrt(2))
elif init_type == 'kaiming':
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
init.orthogonal(m.weight.data, gain=math.sqrt(2))
elif init_type == 'default':
pass
else:
assert 0, "Unsupported initialization: {}".format(init_type)
if hasattr(m, 'bias') and m.bias is not None:
init.constant_(m.bias.data, 0.0)
elif (classname.find('Norm') == 0):
if hasattr(m, 'weight') and m.weight is not None:
init.constant_(m.weight.data, 1.0)
if hasattr(m, 'bias') and m.bias is not None:
init.constant_(m.bias.data, 0.0)
return init_fun학습 하기 전 사용되는 network 가중치 초기화를 준비합니다. 여기는 논문과 같이 normal distribution을 적용했습니다.
# 파라미터 설정
batch_size = 5
epochs = 200
learning_rate = 0.001
# augmentation
train_transform = preprocess.make_transform('train')
test_transform = preprocess.make_transform('test')
# data load
train = preprocess.Dataset(data_path, 'train', transform=train_transform)
val = preprocess.Dataset(data_path, 'val', transform = test_transform)
train_loader = DataLoader(train, batch_size = batch_size,shuffle=True)
val_loader = DataLoader(val, batch_size = batch_size,shuffle=False)
device = 'cuda:1'
model = models.UNet(1, 1).to(device)
""" optimizer: RMSprop 및 Adam """
optimizer = optim.RMSprop(model.parameters(), lr=learning_rate, weight_decay=1e-8, momentum=0.9)
#optimizer = optim.Adam(model.parameters(), lr=learning_rate,weight_decay=1e-8)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min' if model.n_classes > 1 else 'max', patience=30, factor= 0.1)
criterion = nn.BCEWithLogitsLoss()
"""가중치 초기값 적용"""
init_weights = preprocess.weights_init('kaming')
model.apply(init_weights)사용할 하이퍼 파라미터를 정의하고 기존에 정의한 augmentation, dataset, loader, model을 불러옵니다. 논문에서는 batch size가 작기 때문에 momentum에 큰 값을 주어 이전 데이터도 반영하게 하였습니다.
loss는 pixel-wise softmax와 cross entropy loss를 결합하여 계산했습니다. 추가적으로 가중치 초기값으로는 he초기값을 사용합니다.
def train_model(model,train_loader, epochs,device,optimizer, scheduler, criterion, model_path,val_loader=None):
score_dict = {}
for epoch in range(epochs):
model.train()
train_loss = 0
for i, (images, masks) in enumerate(train_loader):
imgs = images
true_masks = masks
imgs = imgs.to(device=device, dtype=torch.float32)
mask_type = torch.float32 if model.n_classes == 1 else torch.long
true_masks = true_masks.to(device=device, dtype=mask_type)
masks_pred = model(imgs)
loss = criterion(masks_pred, true_masks)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_value_(model.parameters(), 0.1)
optimizer.step()
"""검증셋 있을 경우만 사용"""
if val_loader != None:
model.eval()
val_loss = 0
for j, (images, masks) in enumerate(val_loader):
imgs = images
true_masks = masks
imgs = imgs.to(device=device, dtype=torch.float32)
mask_type = torch.float32 if model.n_classes == 1 else torch.long
true_masks = true_masks.to(device=device, dtype=mask_type)
masks_pred = model(imgs)
loss = criterion(masks_pred, true_masks)
val_loss += loss.item()
else:
val_loss = 0
j = 0
#if val_loader == None:
#schedule_standard = train_loss/(i+1)
#else:
#schedule_standard = val_loss/(j+1)
"""Scheduler update"""
schedule_standard = train_loss/(i+1)
scheduler.step(schedule_standard)
print("epoch: {}/{} | trn loss: {:.4f} | val loss: {:.4f}".format(
epochs, epoch+1, train_loss /(i+1), val_loss /(j+1)))
score_dict[epoch] = {'train':train_loss/(i+1), 'val':val_loss/(j+1)}
"""Model save"""
checkpoint = {'loss':train_loss/(i+1),
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict()}
torch.save(checkpoint, model_path+'{}_epoch.pth'.format(epoch))
return model, score_dict학습을 하면서 누적되는 에폭 단위의 score를 저장하고 모델을 저장합니다. 그리고 gradient가 너무 커져 학습에 방해가 되는 것을 막기 위해 추가로 gradient clipping을 적용합니다.
def eval_model(model, loader,device):
model.eval()
with torch.no_grad():
mask_type = torch.float32 if model.n_classes == 1 else torch.long
total_loss = 0
iou_score = 0
preds = []
preds_thres = []
labels = []
for j, (images, masks) in enumerate(loader):
imgs, true_masks = images, masks
imgs = imgs.to(device=device, dtype=torch.float32)
true_masks = true_masks.to(device=device, dtype=mask_type)
masks_pred = model(imgs)
if model.n_classes > 1:
tot += F.cross_entropy(mask_pred, true_masks).item()
else:
criterion = nn.BCEWithLogitsLoss()
pred = masks_pred
loss = criterion(masks_pred, true_masks)
pred2 = torch.sigmoid(masks_pred)
pred2 = (pred > 0.5).float()
pred = pred.cpu().numpy()
pred2 = pred2.cpu().numpy()
true_masks = true_masks.cpu().numpy()
preds.append(pred)
preds_thres.append(pred2)
labels.append(true_masks)
total_loss += loss.item()
"""IOU Score"""
iou_score += compute_iou(pred2, true_masks)
return np.vstack(preds), np.vstack(preds_thres), np.vstack(labels), (total_loss/(j+1), iou_score/(j+1))평가는 학습할 때와 마찬가지의 loss로 확인합니다. 추가로 논문에서 사용한 Intersection Over Union을 계산하여 성능을 확인합니다. 평가에서 augmentation을 적용하지 않습니다.
오늘은 image segmentation에 강점이 잇는 U-Net에 대해 공부했습니다.
[참조]https://blog.naver.com/winddori2002/222111458214
[바람돌이/딥러닝] UNet 이론 및 코드 리뷰
안녕하세요. 오늘은 Image Segmentation에 강점을 가지고 있는 U-Net에 대한 이론과 pytorch로 구현한 ...
blog.naver.com
https://arxiv.org/pdf/1505.04597.pdf)%e5%92%8c%5bTiramisu%5d(https://arxiv.org/abs/1611.09326.pdf
논문출처