1. Subword Tokenizer
1)개요
=>기계에게 아무리 많은 단어를 학습시켜도 세상의 모든 단어를 학습시킬 수 없는데 이유는 신조어 등의 등장
=>자연어 처리에서는 없는 단어가 등장하는 경우 OOV(Out Of Vocabulary)로 처리
OOV 가 발생하면 문제를 푸는 것이 까다로워지는 상황이 발생
=>Subword Tokenizer 는 기존 단어를 더 작은 단위의 의미있는 여러 서브 워드로 분할하는 것
하나의 단어를 여러 서브 워드로 분리해서 단어를 인코딩 및 Embedding 하겠다는 의도를 가진 작없이 Subword Tokenizer
2)BPE(Byte Per Encoding)
=>압축 알고리즘이었는데 자연어 처리에서 사용
=>자주 등장하는(2번 이상) 글자 또는 단어의 모임을 다른 글자 나 단어로 치환해 나가는 알고리즘
자주 등장하는 글자 또는 단어를 새로운 단어로 추가해 나가는 형태로 자연어 처리에서는 사용
=>구현을 할 때는 단어 와 등장 횟수로 이루어진 Dictionary를 만들어서 수행
low:5 lower:2 newest:6 widest:3
단어집: low, lower, newest, widest - 이 상태에서 lowest 단어가 등장하면 OOV
- 각 단어를 글자 단위로 분리
l o w:5 l o w e r: 2 n e w e s t: 6 w i d e s t:3
현재 단어집: l o w e r n w s t i d
- e 와 s 가 연속된 것이 9번
l o w:5 l o w e r: 2 n e w es t: 6 w i d es t:3
현재 단어집: l o w e r n w s t i d es
- es 와 t 가 연속된 것이 9번
low e r: 2 n e w est: 6 w i d est:3
현재 단어집: l o w e r n w s t i d es est
- 이런 식으로 진행을 하면
현재 단어집: l o w e r n w s t i d es est lo low
3)wordpiece model
=>BPE 알고리즘은 빈도 수 기반의 서브워드 토크나이저 알고리즘
=>구글의 BERT 에 사용되어서 유명해진 알고리즘으로 단어를 분할하고 우도(likelihood)를 가장 높이는 쌍을 병합해나가는 방식
=>확률 분포에 기반한 방식
4)Unigram Language Model Tokenizer
=>서브 워드들을 제거해나가면서 문장의 우도에 얼마나 영향을 주는지를 파악하는 방식으로 단어를 추가
5)SentencePiece
=>구글이 만든 서브 워드 토크나이저 라이브러리
=>BPE 알고리즘 과 Unigram Languate Model Tokenizer를 사용해서 단어를 생성
=>설치: pip install sentencepiece
=>공백을 기준으로 동작 - 한글의 경우는 형태소 분석기 와 이 라이브러리의 결과를 합치면 기존의 단어 사전보다 더 좋은 단어 사전을 만들 수 있습니다.
#웹의 텍스트 문서를 다운로드 받아서 파일로 저장
urllib.request.urlretrieve(
"https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt",
filename="ratings.txt")
naver_df = pd.read_table('ratings.txt')
naver_df.head()
naver_df = naver_df.dropna(how='any')
naver_df.info()
#단어 사전 생성
spm.SentencePieceTrainer.Train('--input=naver_review.txt --model_prefix=naver --vocab_size=5000 --model_type=bpe --max_sentence_length=9999')
#naver.model 이라는 파일 과 naver.vocab 파일이 생성되는데 naver.vocab 파일에 단어 사전이 만들어 집니다.
#단어 사전 읽어오기
vocab_list = pd.read_csv('naver.vocab', sep="\t", header=None, quoting=csv.QUOTE_NONE)
vocab_list.head()
2.Encoder & Decoder
=>입력 데이터를 이용해서 새로운 출력을 만들어 내는 것
=>비지도 학습: Decoder 는 기존의 방식 과 다르게 정답이 없는 상태에서 새로운 출력을 만들어 내는 것
1)마르코프 체인
=>확률을 기반으로 하는 방법
=>마르코프 성질이란 과거 상태를 무시하고 현재의 상태만을 기반으로 다음 상태를 선택하는 것
=>마르코프 성질을 이용하면 기본 문장을 기반으로 문장을 자동으로 생성할 수 있고 문장을 요약할 수 있음
=>기계 학습을 통해서 기계적으로 문장을 생성하고 Okt에 자동으로 등록하는 트위터 봇에 사용
=>문장을 만드는 과정
- 기존 문장을 단어 단위로 분할
- 단어의 전후 연결을 디셔너리에 등록
- 디셔너리를 이용해서 임의 문장을 생성
=>의미를 전혀 고려하지 않기 때문에 조금 이상한 문장이 만들어지기도 합니다.
개도 닷새가 되면 주인을 안다
기르던 개에게 다리가 물렸다
닭 쫒던 개 지붕 쳐다 보듯 한다
똥 묻은 개가 겨 묻은 개 나무란다.
- 형태소 분석 수행
개 도 닷새 가 되면 주인 을 안다
기르던 개 에게 다리 가 물렸다
닭 쫒던 개 지붕 쳐다 보듯 한다
똥 묻은 개 가 겨 묻은 개 나무란다.
- 개 가를 입력한 후 되면을 입력하면
개가 되면 주인을 안다 문장을 생성
2)Seq2Seq 모델

=>Sequence를 입력하면 Sequence 를 출력하는 RNN 모델
Seq2Seq -> Attention(중요 부문만 집중) -> Transformer(RNN을 제거하고 Attention만 사용) -> Bert & GPT
=>RNN(순환 신경망)을 사용하는 모델은 순차적으로 데이터를 입력하기 때문에 학습속도가 느리다는 단점이 있는데 Transformer 를 사용하면 RNN을 제거했기 떄문에 병렬화가 가능해서 속도를 개선했고 이로 인해서 GPT 나 BERT 와 같은 LLM이 등장
=>Seq2Seq 모델은 크게 보면 인코더 와 디코더로 구성이 되어있는데 인코더에서 입력된 값을 맥락 벡터로 인코딩을 한 후 디코더에게 전달하고 맥락벡터와 디코더 입력값을 받아서 순차적으로 결과를 출력
=>언어 번역기나 챗봇 같은 경우 seq2seq 모델로 만들 수 있는 대표적인 콘텐츠인데 훈련을 하기 위해서는 이미 번역된 데이터 그리고 챗봇의 경우도 질의와 응답으로 된 데이터가 미리 제공되어야 합니다/
입력과 출력 데이터의 길이는 동일하지 않아도 됩니다.
=>입력된 데이터를 숫자로 임베딩(단어를 수치화하는데 벡터로 수치화를 하고 수치화 할 때 단어 사이의 거리를 기반으로 수치화)를 해서 가장 유사한 질의를 찾아서 응답을 제공하는 방식
=>이 방식의 모델을 만들 때는 Encoder 와 Decoder를 별개로 만들어야 합니다
3)BLEU Score
=>기계 번역의 성능이 얼마나 뛰어난가를 측정하기 위한 방법 중의 하나
=>n-gram기반
=>언어 번역에서는 단어의 개수를 이용한 정확도(예측한 것 중에서 정확하게 예측한 것의 비율)를 가지고 평가를 하게 되면 짧은 문장으로 번역하는것이 유리합니다.
=>짧은 텍스트에 벌점을 부과하고 중복도 제거해서 점수를 매김
=>순서를 보정한 방식도 등장
4)한글 말 뭉치 제공
=>KoBert 나 korpora
5)Seq2Seq 모델을 만들 때 데이터 준비
=>question: 인코더에 입력할 데이터 셋(질문)
=>answer: 답변
답변을 메모리에 옮겨 올 때 <START> 와 같은 토큰을 삽입해야 하고 뒤에 <END> 와 같은 토큰을 삽입해서 사용
=>주가 예측에 사용하는 seq2seq 모델은 출력의 길이가 고정이라서 몇 개를 출력해야 할지 알지만 자연어처리에서 sequence 를 출력하는 경우 출력의 길이가 매번 다르기 때문에 어디서 끝나야 할지를 알려줘야합니다.
6)Attention

=>기존의 모델은 출력 단어를 예측할 때 매시점에서의 인코더의 전체 입력 문장을 다시 참고 하는데 전체 입력 문장을 전부 다 동일한 비율으로 참고하는 것이 아니라 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 조금 더 집중해서 보게되는 모델
=>질문이 주어지면 질문에 대해서 모든 키와 유사도를 구하고 이 유사도를 바탕으로 키와 매핑되어 있는 각각의 값을 반영해서 유사도가 반영된 값을 모두 더해서 리턴
문장이 길어졌을 떄 어느 정도 집중해야 할지를 단어에 반영햇허 중요한 단어에 더 집중해서 문장을 번역
단어의 가중치 문제로는 Counter 기반 이랑 Td-idf 가 있음 Seq2seq 는 하나의 문장을 ' 단어 단어 단어'라고 봤을때 다 똑같은 가중치를 가지게 됨. 하지만 Attention은 '나는 무엇을 해야해'에서 무엇을이 중요 단어라 가중치를 가지고 있어야 한다고 판단해야함. 또 단어들간의 유사도를 찾아서 seq2seq 보다 정확해짐. seq2seq 는 Counter 기반 , attention은 Td-idf 에 관련이 있음
최근에 와서 머신러닝이나 딥러닝에서 가장 크게 대두되는 문제는 실시간 학습 및 서비스가 가능한가가 중요함. 서비스를 하고 있으면서 어떻게 활용할 껀가. 예전의 머신러닝은 한번 학습 하고 다시 학습해야함. 하지만 딥러닝은 다시 fit 만 하면 기존에 있는 데이터에 추가적으로 새로 들어온 데이터만 학습이 가능해서 유명해짐.
7)Transformer
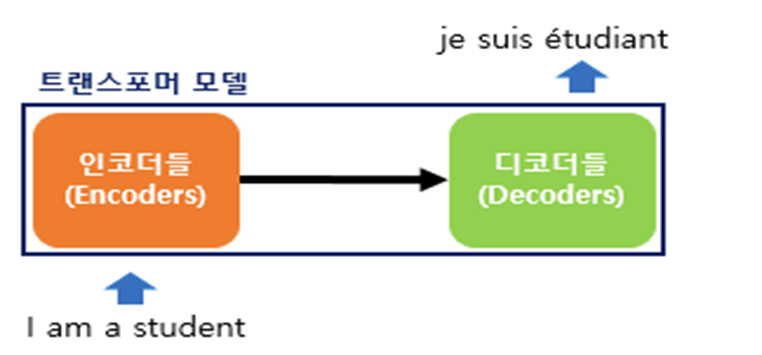
RNN 의 치명적인 단점) 연쇄적으로 학습 해야되다 보니 병렬학습이 불가능함. GOOGLE이 Attention만 쓰자 => Transformer 이것만 활용하면 병렬학습이 가능함.
=>RNN의 치명적 단점인 훈련속도가 느리다라는 것을 보완하기 위해서 Seq2Seq 모델을 만들 떄 RNN을 전부 제거하고 Attention 만으로 만든 모델
=>이 방식을 이용하면 훈련을 병렬로 수행할 수 있어서 훈련속도가 빨라지게 되고 이로 인해서 거대 언어 모델 (BERT,GPT)등이 등장
=>BERT 같은 경우는 구글에서 훈련된 모델을 제공하는데 한글 처리는 정확도가 높지 않아서 KoBERT 와 같은 한국어 처리 모델을 이용합니다
이 때 자신이 가지고 있는 데이터를 추가해서 자신의 업무에 조금 더 특화된 모델을 만들어서 사용할 수 있는데 이를 Fine Tuning이라고 합니다