웹 크롤링이란?
'URL을 탐색해 반복적으로 링크를 가져오는 과정'입니다.웹 크롤링은 단어 자체에서 보다시피 웹페이지를 찾아다니며 정보를 수집합니다. 대표적인 웹 크롤링으로는 검색엔진의 웹 크롤러가 하는 일을 예로 들 수 있습니다.웹 크롤러는 URL을 수집하고 웹 페이지를 복사하여, 수집한 웹 페이지에 index을 부여해 사용자에게 더 신속하게 정보를 제공합니다.
웹 스크래핑이란?
'우리가 정한 웹 페이지에서 데이터를 추출하는 것'입니다. 우리가 특정 주제의 뉴스만을 가져오거나, 인기검색어 정보를 가져오는 것, 어떤 상품의 가격을 모니터링하는 것 모두 웹 스크래핑입니다. 웹 스크래핑을 웹 데이터 추출, 웹 하베스팅이라고도 부릅니다.
웹 크롤링과 웹 스크래핑은 모두 정보를 추출해온다는 데서는 공통점을 지니니만, '타겟 웹 페이지의 유무'와 '중복제거의 실행 여부'에서 차이가 납니다.
웹 크롤링은 특정 웹 페이지를 목표로 하지 않습니다. 일단 탐색부터 하고, 정보를 가져오죠.'선탐색 후추출'입니다. 웹 스크래핑할 때는 목표로 하는 특정 웹페이지가 있습니다. 우리가 원하는 정보를 어디서 가져올지 타겟이 분명하고, 그 타겟에서 정보를 가져오죠.'선결정 후추출'입니다.
pip install beautifulsoup4 lxml requests
Robots.txt와 사용자 에이전트
Robots.txt는 웹 사이트 및 웹페이지를 수집하는 로봇들의 무단 접근을 방지하기 위해 만들어진 국제 권고안입니다.일부 스팸 봇이나 악성목적을 지닌 가짜 클라이언트 로봇은 웹 사이트에 진짜 클라이언트처럼 접근합니다. 그리고 무단으로 웹 사이트 정보를 긁어가거나, 웹 서버에 부하를 주는걸 통제하기 위해 마련된 것이 Robots.txt입니다.
가끔 웹 서버에 요청을 거부 당하는 일이 있습니다.우리를 무단 봇으로 짐작하고 웹 서버에서 접근을 막는것입니다. 그럼 우리는 브라우저에게 봇이 아니라 사람이라는 것을 알려주기 위해 사용자 에이전트(user agent)정보입니다.
사용자 에이전트는 사용자를 대표하는 컴퓨터 프로그램으로써 웹 맥락에서는 브라우저, 웹 페이즤를 수집하는 봇, 다운로드 관리자,웹에 접근하는 다른 앱 모두 사용자 에이전트 입니다. 웹 서버에 요청할 떄 사용자 에이전트 HTTP 헤더에 나의 브라우저 정보를 전달하면 웹 서버가 나를 진짜 사용자로 인식할 수 있게 됩니다.
웹 스크래핑의 원칙
1.서버에 과도한 부하를 주지 않는다. 2.가져온 정보를 사용할 때 저작권과 데이터베이스권에 위배되지 않는지 주의한다.
기본코드 프레임
import requests
2 from bs4 import BeautifulSoup
3
4 url = "www.kingbk.tistory.com"
5 res = requests.get(url)
6 res.raise_for_status() # 정상 200
7 soup = BeautifulSoup(res.text, "lxml")4번줄인 url 변수에 문자열 객체로 만들어 변수 url에 할당하고, 웹 서버에 GET 요청을 보내고 웹서버가 응답한 내용을 res에 할당하고 에러가 발생하면 에러를 변환합니다. 만약 403에러가 뜬다면 웹 서버측에서 우리의 접근을 거부한 것이므로, user agent 헤더를 설정하려면
headers = {"User-Agent": "[WhatIsMyBrowser에 나타난 나의 유저 정보]"}
res = requests.get(url, headers=headers)1.WhatIsMyBrowser에 들어가서 나의 사용자 에이전트 정보를 확인합니다.
2.웹 스크래핑 시 headers 정보를 딕셔너리 형태로 만들어 변수에 할당합니다.
3.웹 서버에 요청시 이 header정보를 함께 보냅니다.
데이터를 엑셀로 저장하는 기본 코드로 알아보겠습니다.
import csv
#엑셀 파일로 저장하기
filename = "고양이 장난감.csv"
f = open(filename, "w", encoding="utf-8", newline="")
writer = csv.writer(f)
#컬럼 속성명 만들기
columns_title = ["컬럼명1", "컬럼명2"]
writer.writerow(columns_title)
#반복문으로 엑셀 및 터미널 창 출력(i=1)
for 변수 in 변수s:
tb = 변수.get("a")
print(f"말하고싶은거")
data = [str(i), tb]
writer.writerow(data)
i += 1
위의 방식도 참고하고 제 스스로 한번 해보고 싶어서 Melon TOP 100 스크래핑하기!! 로 가보겠습니다.
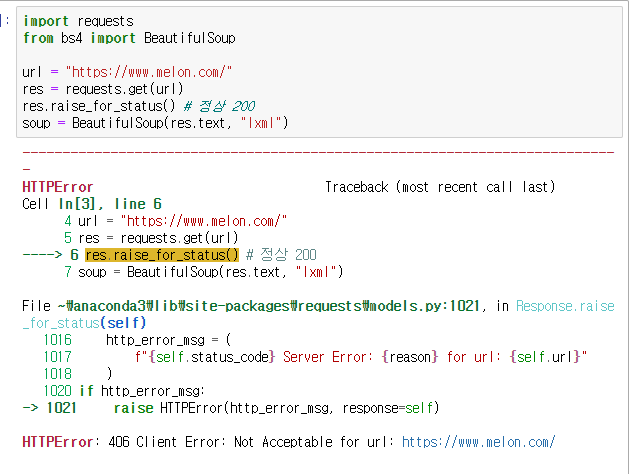
역시나 406이 떴으니까 user-agent를 얻어올께용!!


response 200이 떴으니까 이제 멜론 홈페이지에 있는 TOP100을 한번 뽑아볼께요~
원하는 데이터를 불러오는 데는 여러가지 방법이 존재합니다.
1번 .select(): select는 CSS selector로 tag객체를 찾아 반환합니다. CSS에서 HTML을 tagging 하는 방법을 활용한 method
2번 find(),findall():find는 HTML 문서에서 가장 처음으로 나오는 태그 1개를 반환하고, find_all()은 우리가 지정한 모든 태그를 찾아줍니다.
여러방법이 있으나 지금은 select()함수를 사용해서 확인해볼께요

12번줄에 .text을 뒤에 붙인 이유는 안붙이니까 가독성이 너무 떨어지더라구요.!! text 붙여서 1등 가수인 르세라핌을 Ctrl-F로 찾은 다음에 <span class="checkEllipsis" style="display:none"> 을 보고 가수명은 .select("span.checkEllipsis")를 통해 뽑았습니다. 마찬가지로 노래제목도 똑같이 찾아서 해봤어용
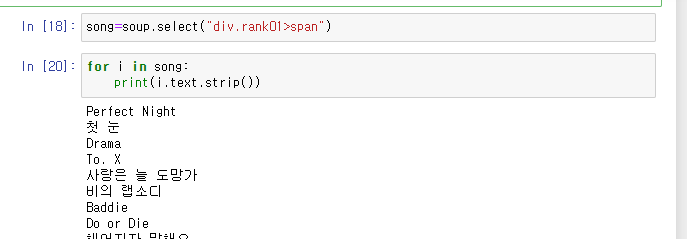
이제 노래 제목과 가수명을 다 찾았으니까 이걸 csv파일로 저장해야겠죠??
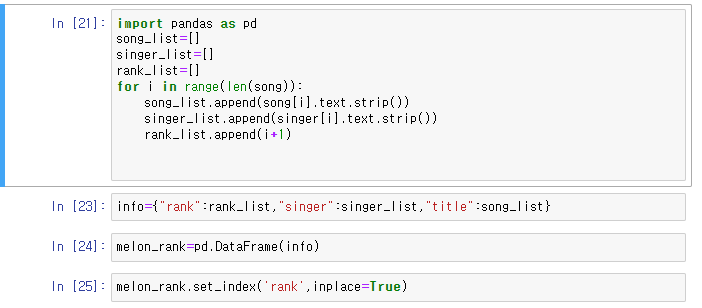
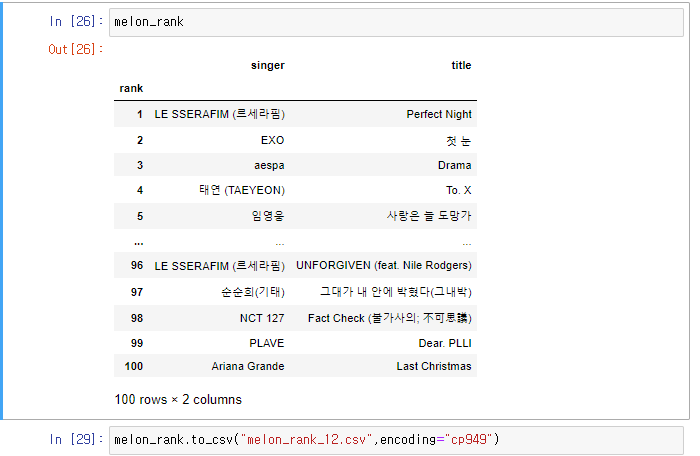

다음과 같이 멜론에 있는 12월 top100을 뽑아봤습니다!!!

'project > 개인공부' 카테고리의 다른 글
| KoBERT를 활용한 감정분류 모델 (0) | 2024.04.14 |
|---|---|
| 2022년도 Melon가사 분석을 통한 감정분류 (0) | 2024.04.01 |
| 생성형 AI 란 무엇인가? (0) | 2024.02.11 |
| GIT 사용법 (1) | 2024.01.26 |
| 기본정렬 알고리즘 (Sorting 기법 정리(Bubble,Selection,Quick,Heap,Insertion,Merge)) (1) | 2024.01.02 |



