**데이터 전처리
1. 중복 데이터 처리
-> 하나의 데이터 셋에서 동일한 관측값이 2개 이상 중복되는 경우 분석 결과를 왜곡할 수 있음
1)duplicated()
-> 데이터의 중복 여부를 bool의 Series로 리턴
2) drop_duplicates()
-> 매개변수를 대입하지 않으면 모든 컬럼의 값이 일치하는 경우 제거
-> subset 옵션으로 컬럼의 이름이나 컬럼 이름의 list를 대입하면 설정된 컬럼의 값이 일치하는 경우 제거하고 첫번째 데이터를 유지
keep 옵션을 이용하면 마지막 데이터를 유지시킬 수 있음
-> inplace 옵션이 존재
pandas의 DataFrame은 원본을 복제를 해서 수정하고 리턴을 하는데 원본에 직접 작업하고자 할 때 사용하는 옵션
2. 함수 적용
1) apply
-> Series나 DataFrame에 사용할 수 있는 함수로 Series의 경우는 각 요소에 적용해서 그 결과를 Series로 리턴하고 DataFrame은 기본적으로 열 단위로 대입해서 결과를 DataFrame으로 리턴하는데 axis = 1을 설정하면 행 단위로 적용
2) pipe
-> 하나의 값을 가지고 작업하는 함수를 대입하면 동일한 구조의 데이터를 리턴
모든 요소에 함수를 적용해서 그결과를 가지고 데이터를 다시 생성해서 리턴
-> 집계를 하는 함수를 대입하면 열 단위로 함수를 적용해서 Series를 리턴
-> Series를 리턴하는 함수를 호출해서 집계를 하면 하나의 값을 리턴
-> pipe 실습
3. 컬럼 재구성
1) 컬럼의 순서를 변경
-> DataFrame객체[재구성할 열 이름의 list]
2) 날짜 컬럼을 분할
4.필터링
-> 조건에 맞는 데이터만 추출
5. 데이터 결합
-> 데이터가 분할된 경우 합치는 기능
-> 데이터를 합치는 기능은 join처럼 키를 가지고 옆으로 합치는 것 과 동일한 컬럼을 가진 경우 세로로 합칠 수 있습니다.
1) concat
-> 구성 형태와 속성이 균일한 경우 행 또는 열 방향으로 이어붙이는 함수
-> 별다른 옵션이 없으면 Series와 Series는 옆으로 합쳐서 DataFrame을 만들어주고 DataFrame끼리는 상하로 합쳐서 하나의 DataFrame을 만들어 줍니다.
한쪽에만 존재하는 컬럼도 합쳐지는데 값은 NaN
-> axis = 1을 설정해서 합치면 옆으로 합치게 됩니다.
이 경우에는 join 옵션을 사용할 수 있는데 기본은 outer이고 inner를 설정할 수 있습니다.
2) append
-> 인덱스와 상관없이 컬럼 이름만 가지고 상하로 결합
-> 최신 버전에서는 API 변경됨
3) combine_first
-> 2개의 데이터 프레임을 상하로 세로 방향으로 합치는데 동일한 인덱스가 존재하면 앞의 데이터를 적용합니다.
뒤의 데이터는 합쳐지지 않습니다.
4) merge
-> 2개의 데이터프레임을 합치는 메서드인데 JOIN과 유사한 방식으로 합침
-> 데이터프레임만 설정하면 동일한 이름의 컬럼을 가지고 JOIN을 수행
-> key라는 옵션에 조인을 위한 컬럼 설정 가능
-> join을 위한 컬럼의 이름이 다른 경우에는 left_on 과 right_on 옵션에 직접 컬럼이름을 설정할 수 있습니다.
-> how 옵션에 inner, leftm right, outer를 설정해서 outer join을 수행
-> suffixes 옵션에 튜플로 2개의 문자열을 설정하면 동일한 이름의 컬럼이 있는 경우 _이름 을 추가해줍니다. 생략하면 _x, _y 가 붙음
-> 기본적으로 key를 기준으로 정렬을 수행하는데 정렬을 하지 않고자 하면 sort옵션에 False를 설정해주면 됩니다.
5) join
-> merge와 유사
-> 기본적으로 행 인덱스를 키로 사용
-> 키 설정이 가능하고 how 옵션도 존재
=>merge는 pandas 의 함수 이지만 join은 DataFrame의 메서
#내부조인
print(pd.merge(price,valuation))#Full outer join
print(pd.merge(price,valuation,how='outer',on='id'))#join 하는 컬럼의 이름이 다를 때
print(pd.merge(price,valuation,how='right',left_on='stock_name',right_on='name'))#조인은 기본적으로 index을 가지고 JOIN을 수행
#price.set_index('id')
#price.index=price["id"]
valuation.index=valuation['id'] # 3개중 하나 사용
#동일한 컬럼 제거
price.drop(['id'],axis=1,inplace=True)
valuation.drop(['id'],axis=1,inplace=True)
print(price.join(valuation))
6.그룹 연산
1) 그룹화
=>어떤 기준에 따라 그룹 별로 나누어서 관찰하는 것
=>groupbu함수를 이용하는데 컬럼이름이나 컬럼이름의 list을 대입해서 그룹화
=>그룹화 한 후 get_group(그룹이름)을 이용하면 개별 그룹의 데이터를 가져오는 것이 가능
=>그룹화 한 데이터는 iteration(for 사용)이 가능함 이를 확인하는 방법은 print(dir([]))을 활용해서 __iter__가 있는지 확인
그룹화도 사용이 가능하지만 2개의 데이터를 튜플로 리턴하는데 하나는 그룹의 이름이고 다른 하나는 그룹의 데이터
=>titanic 데이터를 class 별로 그룹화
import seaborn as sns
titanic = sns.load_dataset('titanic')
#일부만 관찰
df=titanic[['age','sex','class','fare','survived']]
print(df.head())grouped=df.groupby(['class'])
for key,group in grouped:
print(key,len(group)) #뭐로 구성되있고 각각의 개수를 파악할 수 있음=>2개의 항목을 그룹화
#2개의 열로 그룹화-key가 2개 항목의 튜플로 만들어집니다
grouped=df.groupby(['class','sex'])
for key,group in grouped:
print(key)
2)집계함수
★일반적으로 Null을 제외하고 계산합니다.
=>count(누락값(Null)을 제외), size(누락 값을 포함), mean,std,min,max,quantile(q=0.25|0.5|0.75),sum,var,sem,describe,first,last,nth
'''
grouped=df.groupby(['class'])
std_all=grouped.std()
print(std_all) #이렇게 하면 성별들이 아직 포함되어있음
'''
df=titanic[['class','age']]
grouped=df.groupby(['class'])
std_all=grouped.std()
print(std_all)
=>사용자 정의 함수를 적용하고자 할때는 agg 함수를 호출해서 함수를 넘겨주면 됩니다.만약 내가 원하는 집계함수가 없다면 만들어서 사용하면 됩니다.
reduce:데이터의 묶음을 받아서 결과를 하나로 만들어주는 함수를 이용해서 집계를 수행
def min_max(x):
return x.max()-x.min()
#사용자 정의 함수를 이용한 집계
result=grouped.agg(min_max)
print(result)
=>사용자 정의 함수를 적용해서 데이터를 변환하고자 하는 경우는 transform 함수를 호출해서 함수를 넘겨주면 됩니다.
map: 하나의 데이터를 받아서 하나의 데이터를 리턴하는 함수를 생성해서 데이터의 묶음에 적용하면 하나 하나의 데이터를 함수에 대입해서 호출한 후 그 결과를 묶어서 데이터의 묶음을 리턴하는 함수
#age열의 값을 z-score로 변환
#Z-score(표준점수):(값-평균)/표준편차
def z_score(x):
return (x-x.mean())/(x.std())
age_zscore=grouped.transform(z_score)
print(age_zscore)
3)멀티 인덱스
=>인덱스가 1 level 이 아닌 여러 level로 구성되는 것
=>그룹화를 할 때 하나의 컬럼이 아니라 여러 컬럼으로 하는 경우 멀티 인덱스가 만들어짐
df=titanic[['class','sex','age']]
grouped=df.groupby(['class','sex'])
for key in grouped:
print(key)
4)pivot_table
=>멀티 인덱스는 한 방향에 인덱스가 여러 개 적용되는 것. 주로 날짜 데이터에만 사용 년- 월 - 일
=>피벗 테이블은 양 방향에 인덱스를 적용하는 것 ex.)confusion matrix
df=titanic[['class','sex','age']]
result=pd.pivot_table(df,index='class', columns='sex',values='age',aggfunc='sum')
print(result)
7.데이터 구조화
=>stacked 와 unstacked
stacked: 가로방향으로 넓게 펼쳐진 데이터를 세로 방향으로 길게 만드는 작업 -컬럼을 인덱스로 활용
unstacked:세로 방향으로 깊게 펼쳐진 데이터를 가로 방향으로 넓게 만드는 작업-인덱스를 다시 컬럼으로 활용
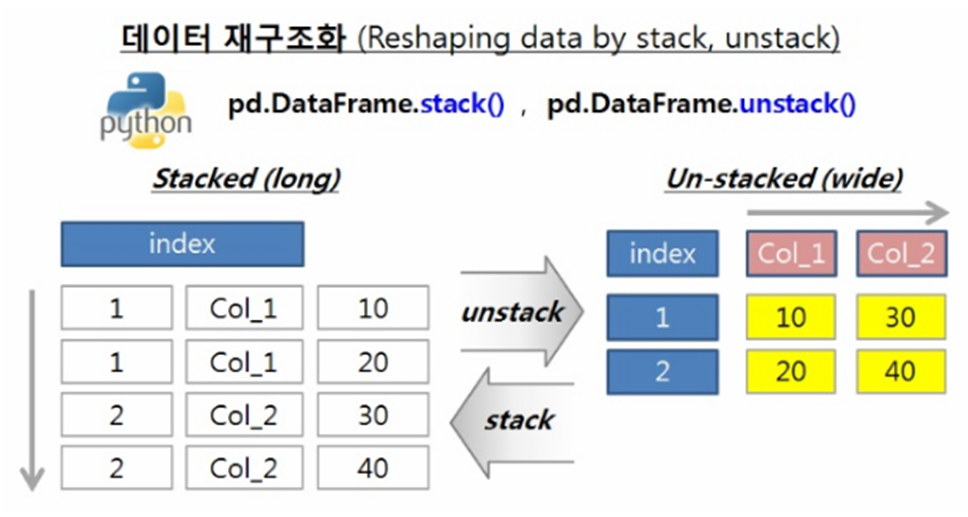
-stakced 작업을 할 떄는 NaN 데이터를 어떻게 처리할 것인지를 결정
1)stack()
=>stacked 작업을 수행해주는 함수
mul_index=pd.MultiIndex.from_tuples([('cust_1','2015'),('cust_1','2016'),('cust_2','2015'),('cust_2','2016')])
data=pd.DataFrame(data=np.arange(16).reshape(4,4),index=mul_index,columns=['prd_1','prd_2','prd_3','prd_4'],dtype="int")
print(data)
stacked=data.stack()
print(stacked)
2)unstack()
=>unstacked 작업을 수행해주는 함수
멀티 인덱스인 경우 어떤 인덱스를 컬럼으로 만들지 level이라는 속성에 숫자로 설정해주어야합니다.
#첫 레벨의 인덱스가 컬럼이 됩니다
unstacked=stacked.unstack(level=0)
print(unstacked)
8.숫자 데이터의 전처리
1)단위 환산
=>개요:하나의 데이터셋에서 서로 다른 측정 단위를 사용하게 되면 전체 데이터의 일관성 측면에서 문제가 발생할 수 있기 떄문에 이런 경우에는 측정 단위를 동일하게 맞출 필요가 있음
-especially, 미국 데이터 사용할 때는 이런 부분에 주의해야 합니다.
#mpg 데이터는 자동차에 대한 정보를 가진 데이터입니다
#mpg 열이 연비인데 미국에서는 갤런당 마일을 사용하는데 우리나라는 리터당 킬로미터를 사용
#이런경우는 단위 변환을 해주는 것이 데이터를 읽는데 편리합니다
#1마일은 1.609394km 이고 1갤런은 3.78541리터
mpg=pd.read_csv('data/auto-mpg.csv',header=None)
mpg.columns=['mpg','cylinders','displacement','horsepower',
'weight','acceleration','model year','origin','name']
print(mpg.head())
#갤런당 마일을 리터당 킬로미터로 변환할 수 있는 상수를 구하기
mpg_to_kpi=1.60934 / 3.78541
mpg['kpl']=mpg['mpg']*mpg_to_kpi
print(mpg.head())=>mpg 데이터에서 갤런당 마일을 가지고 계산을 수행해서 리터당 킬로미터를 계산해서 구하기
2)자료형 변환
=>컬럼의 자료형은 dtypes 속성이나 info() 을 이용해서 가능
=>엑셀 파일이나 csv를 읽다보면 숫자 데이터여야 하는데 문자열로 읽어오는 경우가 있음
엑셀 파일에서 천 단위 구분 기호가 있는 경우가 있는데 이런 경우에는 thousand 옵션에 ,을 설정해서 읽어오면 됩니다.
또는 숫자로 인식할 수 없는 데이터가 포함된 경우가 있어서 이런 경우에는 숫자로 인식할 수 없는 데이터를 숫자 변환하거나 제거한 후 숫자로 변경을 해야 합니다.
=>자료형을 변경하는 메서드는 astype(변경할 자료형)
=>horsepower 열을 float으로 변경
#mpg['horsepower']=mpg['horsepower'].astype('float')
#? 가 있어서 형 변환 실패
#데이터 확인
#unique하게 되면 중복된 데이터를 제거하고 모든 데이터를 추출
print(mpg['horsepower'].unique())
#? data를 NaN으로 치환
mpg['horsepower'].replace('?',np.nan,inplace=True)
#NaN제거
mpg.dropna(subset=['horsepower'],inplace=True)
#실수 자료형으로 변경
mpg['horsepower']=mpg['horsepower'].astype('float')
print(mpg.dtypes)
=>자료형을 범주형으로 변경하고자 하면 category로 자료형을 설정하면 됩니다
origin은 국가를 의미하는 범주형인데, 숫자 자료형으로 되어 있음
이런 경우는 Category 나 STring 으로 변경해주는 것이 좋습니다
'Study > Data전처리 및 통계' 카테고리의 다른 글
| Pandas(7)-Outlier,Encoder,자연어처리 (0) | 2024.02.19 |
|---|---|
| Pandas(6)-Scaler 및 Normalization (0) | 2024.02.16 |
| Pandas(4) (0) | 2024.02.14 |
| Pandas(3) (0) | 2024.02.13 |
| Pandas(2) (1) | 2024.02.08 |



