1.DataFrame의 이름 변경
1)rename()
=>인덱스 나 컬럼의 이름을 변경하고자 할 때 사용
=>index 옵션에 dict 형태로 (기존 인덱스:새로운 인덱스,...) 설정하면 인덱스가 변경
index의 변경은 메서드를 이용하지 않고 index 옵션에 list 나 Series 형태로 설정해도 가능
=>columns 옵션에 딕셔너리 형태로(기존 컬럼이름:새로운 컬럼이름) 설정하면 컬럼 이름 변경
=>inplace 옵션이 있는데 이 옵션의 기본값은 False 인데 False 가 설정되면 복제본을 만들어서 리턴하고 True 를 설정하면 원본이 변경
=>rename 함수는 첫번째 매개변수로 변환 함수를 대입하고 두번째 옵션에 axis에 index 나 columns를 설정해서 변환 함수를 이용해서 변경하는 것도 가능
| item.rename(columns={"code":"코드","manufacture":"원산지","name":"이름","price":"가격"}) |
#numpy와 pandas의 대다수의 메서드는 원본을 변경하지 않고 수정해서 리턴 #pandas의 DataFrame에서는 inplace 옵션이 있는 경우 잉 옵션에 True를 설정하면 #원본을 수정 columns={"code":"코드","manufacture":"원산지","name":"이름","price":"가격"} item.rename(columns=columns) print(item) |
왼쪽의 경우에만 column 명이 바뀌어서 보임
2)인덱스 재구성
=>인덱스
-행을 구별하기 위한 이름
-데이터를 생성할 때 의미있는 이름을 인덱스로 설정하는 것을 권장
-인덱스로 설정할 때 관계형 데이터베이스에서의 기본키 처럼 데이터를 구별할 수 있는 값을 설정하는 것을 권장
=>인덱스를 별도로 설정하지 않으면 일련번호 형태의 숫자로 부여
=>데이터 프레임을 생성할때 index 옵션을 이용해서 지정이 가능
=>reindex 속성을 이용해서 index을 재배치하거나 추가헉거나 삭제하는 것이 가능
=>set_index(열이름이나 열이름 나열)을 이용해서 컬럼을 인덱스로 사용하는 것이 가능한데 컬럼에서는 제거됨
=>reset_index()을 호출하면 기본 인덱스가 제거되고 0부터 시작되는 일련번호로 다시 부여
피벗의 형태를 만들거나 할때 많이 이용
=>index 속성을 이용해서 직접 지정하는 것도 가능
item.set_index('code')
2.데이터편집
1)drop 메서드
=>행이나 열을 삭제하고자 하는 경우에 사용하는 메서드로 인덱스나 컬럼이름을 하나 또는 list 형태로 대입하면 되는데
axis 옵션에 0을 설정하면 행이 제거되고 1을 설정하면 열을 제거
=>inplace 옵션이 존재
=>칼람을 제거할 때 del DataFrame이름['컬럼이름']으로도 제거는 가능한데 비추천
#2행 삭제
print(item.drop([1],axis=0))
#code 열 삭제
print(item.drop(['code'],axis=1))
2) 데이터 수정 및 추가
=>컬럼이름이나 인덱스는 유일무이합니다.
=>DataFrame은 dict 처럼 동작
=>컬럼 수정 및 추가
DataFrame[컬럼이름]=데이터
데이터를 대입할 때 하나의 값도 가능하고 Vector 데이터(list,ndarray,Series,dict) 가능
하나의 값을 설정하면 모든 행의 값이 동일한 값으로 대입되고 dict 을 이용하면 dict의 key와index가 일치하는 경우에 값을 대입합니다
컬럼이름이 존재하지 않으면 추가가되고 컬럼 이름이 존재하면 수정
=>행을 수정 및 추가
DataFrame.loc[인덱스이름] = 데이터
인덱스이름이 존재하지 않으면 추가가 되고 인덱스 이름이 존재하면 수정
3.연산
1)전치 연산
=>행과 열을 스위치하는 연산
=>T라는 속성을 이용할 수 있고 transpose() 라는 메서드를 이요할 수 있습니다.
=>데이터를 읽어왔을 때 방향이 맞지 않는 경우 사용
2)산술 연산
=>numpy와 동일한 방식으로 연산을 수행
=>numpy는 위치를 가지고 연산을 수행하지만 Series 나 DataFrame은 인덱스를 기반으로 연산을 수행하고 한쪽에만 존재하는 인덱스의 경우는 NaN으로 결과를 설정합니다.
=>산술 연산자를 사용해도 되고 add, sub,div,mul 메서드를 이용해도 되는데 메서드를 이용하면 fill_value 옵션에 한쪽에만 존재하는 인덱스에 기본값을 설정할 수 있습니다.
3)기본통계함수
=>count,min,max,sum,mean(평균),median(중앙값),mode(최빈값)
=>var(분산),std(표준편차),kurt(첨도),skew(왜도),sem(평균의 표준 오차)
=>argmin,argmax,idxmin,idxmax
=>quantile(4분위수)
=>describe(기술 통계 정보 요약)
=>cumsum, cummin, cummax, cumprod:누적합,누적최소,누적최대,누적곱
=>diff(산술적인 차이)
=>pct-change(이전 데이터 와의 백분율)
=>unique():Series 에서만 사용가능한데 동일한 값을 제외한 데이터 의 배열을 리턴하는데 skipna 옵션을 이용해서NaN을 제거가능
4)상관 관계 파악
=>상관관계: 2개의 데이터의 동일한 또는 반대되는 방향으로 증감하는 경향을 갖는 관계
상관관계가 높다는 것은 동일한 경향 또는 완전히 반대되는 경향을 갖는 경우
=>cov():공분산 - 거리의 제곱
print(mpg[['mpg','cylinders','displacement']].cov())=>corr():상관 계수 - 공분산과 데이터의 스케일을 맞추지 않고 모든 값이 동일한 스케일을 갖도록 값을 수정합니다.
-1~ 1 이 되도록 수정
print(mpg[['mpg','cylinders','displacement']].corr())절대값 1에 가까워지면 상관 관계 가 높다고 하고 0에 가까워지면 상관 관계가 없다고 합니다
상관계수가 데이터의 관계를 표현하는 전부는 아닙니다.
5)정렬
=>인덱스나 컬럼 이름에 따른 정렬
sort_index()메서드를 이용하는데 기본은 인덱스가 기준이고 오름차순이 기본인데 내림차순을 하고자 할 때는 ascending 옵션에 False를 설정하면 됩니다.
axis 옵션에 1을 설정하면 컬럼이름을 기준으로 정렬을 수행합니다.
=>컬럼의 값을 기준으로 정렬
sort_values(by=열_이름 또는 열 이름의 list, ascending=bool 또는 bool의 list)
6)순위
=>rank 함수를 이용
=>기본적으로 오름차순으로 순위를 설정
=>ascending을 False로 설정하면 내림차순
=>axis 을 이용해서 행이나 열 단위로 설정
=>동일한 점수가 있는 경우 기본적으로 순위의 평균을 리턴하는데 method 옵션에 max,min,first 를 설정해서 동일한 점수를 처리하는 것이 가능
=>순위는 컬럼 단위로 연산을 수행합니다
컬럼의 개수가 2개이면 순위도 2개 리턴됩니다
print(mpg.sort_values(by=['mpg','displacement'],ascending=[True,True]))
3.데이터 시각화 필요성
1)앤스콤 데이터
=>이 데이터는 4개의 데이터 그룹으로 구성되어 있는데 4개의 그룹의 데이터가 존재
=>엔스콤 데이터의 각 데이터 세트의 기술 통계랑이 거의 유사
이 데이터들의 특성이 비슷할 것이라고 판단 -> 오판

2)자주 사용되는 시각화 라이브러리
=>matplotlib:가장 기본이 되는 라이브러리
=>seaborn
=>plotnine
=>plot.ly
=>pyecharts
=>folium:지도 시각화
3)matplotlib
=>시각화(그래프,이미지)에 가장 많이 이용하는 라이브러리
=>파이썬의 대다수 시각화 기능이 이 라이브러리에 의존
=>기본 라이브러리는 아니라서 설치를 해야합니다.
=>실습
#엑셀파일 읽어오기
#header=0 첫행이 컬럼이름
df=pd.read_excel('data (2)/data/시도_별_이동자수.xlsx',header=0)
#print(df)
#엑셀에서 셀 병합이 있으면 첫번째를 제외하고는 Nan으로 처리
df=df.ffill() #NaN데이터를 앞의 데이터로 채우기
print(df)#전출지별이 서울특별시이고 전입지별이 서울특별시가 아닌 데이터만 추출
#조건 생성
filter = (df['전출지별']=='서울특별시') & (df['전입지별']!='서울특별시')
df_seoul=df[filter]
#전출비별 컬럼을 제거
df_seoul.drop(['전출지별'],axis=1,inplace=True)
#전입지별 이라는 컬럼 이름을 전입지로 변경
df_seoul.rename({'전입지별':'전입지'},axis=1,inplace=True)
#전입지를 인덱스로 설정
df_seoul.set_index('전입지',inplace=True)
#print(df_seoul)
#인덱스가 전라남도인 데이터만 추출
sr_one=df_seoul.loc['전라남도']
print(sr_one)
#sr_one 데이터를 가지고 라인 그래프 그리지
import matplotlib.pyplot as plt
#첫번째가 X축에 적용될 데이터
#두번째가 Y축에 적용될 데이터
plt.plot(sr_one.index,sr_one.values)
plt.show()
=>matplotlib을 사용했을 떄의 문제점
- 한글이나 음수는 제대로 출력되지 않음
#sr_one 데이터를 가지고 라인 그래프 그리지
import matplotlib.pyplot as plt
#운영체제 별 폰트 설정
from matplotlib import font_manager, rc
import platform
if platform.system() =='DarWin':
rc('font',family='AppleGothic')
elif platform.system() =='Windows':
font_name=font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font',family=font_name)
plt.figure(figsize=(14,5)) #크기 조정
#x축 눈금 라벨 회전
plt.xticks(size=10,rotation='vertical')
plt.title('서울->전라남도') # 일반적인 경우 matplotlib은 한글을지원하지않음
#첫번째가 X축에 적용될 데이터
#두번째가 Y축에 적용될 데이터
#라인그래프 출력
plt.plot(sr_one.index,sr_one.values,marker='o',markersize=10)
plt.xlabel('기간',size=20)
plt.ylabel('이동 인구수',size=20)
#범례
plt.legend(labels=['서울=>전라남도'],loc='best',fontsize=15)
plt.show()
위와 같이 해놓으면 matplotlib에서도 한글이 출력됩니다.
=>크기 비교를 위한 그래프:막대 그래프
#sr_one 데이터를 가지고 라인 그래프 그리지
import matplotlib.pyplot as plt
#운영체제 별 폰트 설정
from matplotlib import font_manager, rc
import platform
if platform.system() =='DarWin':
rc('font',family='AppleGothic')
elif platform.system() =='Windows':
font_name=font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font',family=font_name)
plt.figure(figsize=(14,5)) #크기 조정
#x축 눈금 라벨 회전
plt.xticks(size=10,rotation='vertical')
plt.title('서울->전라남도') # 일반적인 경우 matplotlib은 한글을지원하지않음
#첫번째가 X축에 적용될 데이터
#두번째가 Y축에 적용될 데이터
#라인그래프 출력
plt.bar(sr_one.index,sr_one.values)
plt.xlabel('기간',size=20)
plt.ylabel('이동 인구수',size=20)
#범례
plt.legend(labels=['서울=>전라남도'],loc='best',fontsize=15)
plt.show()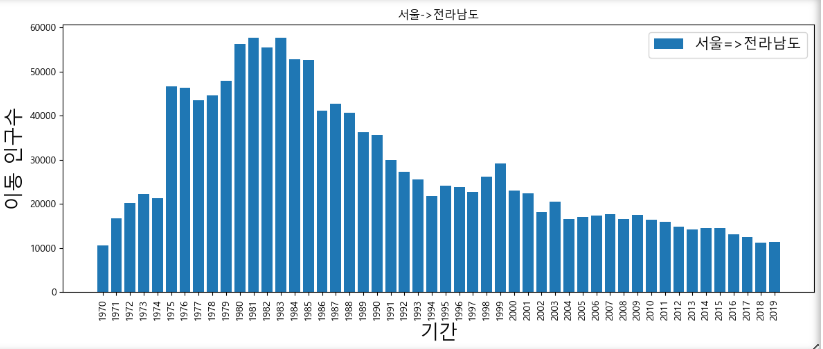
=>빈도수를 위한 그래프:막대그래프 나 히스토그램(hist)
#선호 과일 컬럼의 빈도수 추출
data=fruits['선호과일'].value_counts(sort=False)
print(data)
#막대그래프로 빈도수 추출
#plt.bar(range(0,len(data),1),data)
#plt.xticks(range(0,len(data),1),data.index)
#히스토그램 그리기
plt.hist(fruits['선호과일'])
plt.show()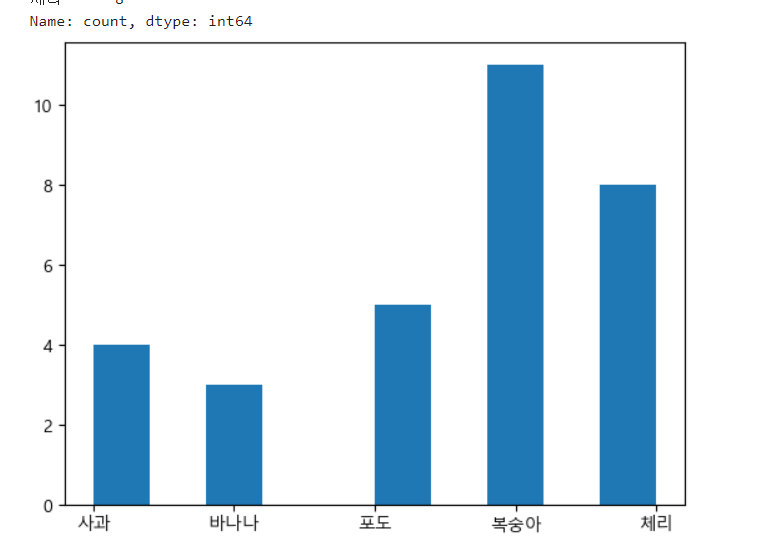
막대 그래프로 빈도수 출력하기 위해서는 직접 빈도수를 구해서 그려야 하지만, 히스토그램은 hist 메서드가 직접 빈도수를 구해서 그려줍니다.
.=>데이터의 분포나 상관관계를 파악하기 위해서 그래프 산포도(scatter)
xc와 ㅛ 옵션에 데이터를 설정하면 그릴수 있는데 s옵션에서 사이즈를 설정해서 크리고 다른 데이터를 반양하는 것이 가능합니다.
mpg=pd.read_csv("data (2)/data/noheader_auto-mpg.csv",header=None)
mpg.columns=['mpg','cylinders','displacement','horsepower','weight','acceleration','model year','origin','name']
size=mpg['cylinders']/mpg['cylinders'].max()*200
plt.scatter(x=mpg['weight'],y=mpg['mpg'],s=size,c='coral',alpha=0.5)
plt.show()
=>r기여도를 나타내는 파이그래프 pie
=>데이터의 범위를 표현하기 위한 박스 플롯 boxplot
=>데이터의 크기를 영역으로 나타내는 그래프 fill_between
하다보면 matplotlib보다 tableau가 훨씬 시각적으로 도움이 됨. 하지만 tableau에서는 파일 처리를 하지 못하기 때문에 python에서 파일 처리를 하고 tableau에서 사용하는게 좀 더 맞아보임
4)seaborn
=>matplotlib을 기반으로 다양한 색상 테마와 통계용 차트의 기능을 추가한 패키지로 numpy와 pandas의 자료구조를 지원
=>도큐먼트:https://seaborn.pydata.org/
seaborn: statistical data visualization — seaborn 0.13.2 documentation
seaborn: statistical data visualization
seaborn.pydata.org
=>샘플 데이터를 내장하고 있는데 load-dataset 으로 불러오기
import seaborn as sns
tips=sns.load_dataset('tips')
print(tips.head())=>산점도와 회귀식을 출력
regplot() 이나 Implot()을 이용
산점도와 회귀선을 같이 출력
회귀선을 출력하지 않고자 하면 fit_reg 옵션 설정을 수정하면 됩니다
data에 데이터프레임을 설정하고 x와 y 에 칼럼이름을 설정합니다
#산점도와 회귀선을 출력
plt.figure(figsize=(8,6)) #캔버스 크기 설정
sns.regplot(x="total_bill",y="tip",data=tips)
plt.show()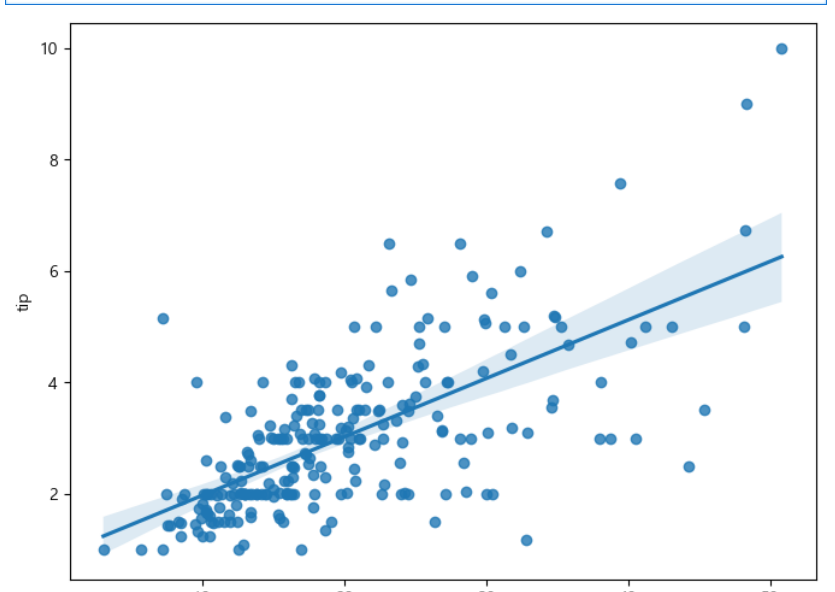
선이 자동으로 그려지는 것을 볼 수 있습니다
#산점도와 회귀선을 출력
plt.figure(figsize=(8,6)) #캔버스 크기 설정
#hue에 카테고리를 선택하면 카테고리 별로 분류해서 설정합니
sns.lmplot(x="total_bill",y="tip",hue='smoker',data=tips)
plt.show()
=>heatmap:기간별 추세를 알아보고자 할때 사용
가로와 세로 모두 기간을 설정하고 색상을 이용해서 크기를 설정
라인 그래프는 일반적으로 가로 방향에만 기간을 설정
heatmap을 출력할 때는 범례나 레이블을 출력을 해줘야 값의 변화를 파악하기 쉽습니다
#index를 month 로 column에 year를 passenger의 합계를 구하는 피벗을 생성
data=flights.pivot(index="month",columns="year",values="passengers")
print(data)
sns.heatmap(data)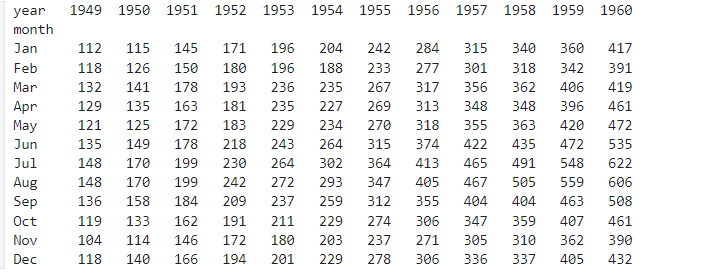

=>데이터 분포를 출력해주는 다양한 그래프
boxplot:4분위수와 IQR(3/4-1/4)*1.5 배 되는 데이터의 위치 및 그 이외의 데이터 분포를 확인
데이터의 밀집 형태를 판단할 수 없음
violinplot:4분위수 대신에 두꼐를 이용해서 데이터의 밀집 형태를 판단할 수 있습니다.
stripplot:두께가 아니라 점으로 데이터의 밀집 형태를 표시(점이 겹침)
swarmplot: 두께가 아니라 점으로 데이터의 밀집 형태를 표시(점이 겹치지 않음)
boxplot 과 swarmplot을 같이 출력하면 데이터의 밀집 형태도 확인이 가능
tips=sns.load_dataset('tips')
sns.boxplot(x='day',y='total_bill',data=tips)
plt.show()
violinplot
tips=sns.load_dataset('tips')
#바이올린 플롯-데이터의 밀집 형태를 두꼐로 표시
sns.violinplot(x='day',y='total_bill',data=tips)
plt.show()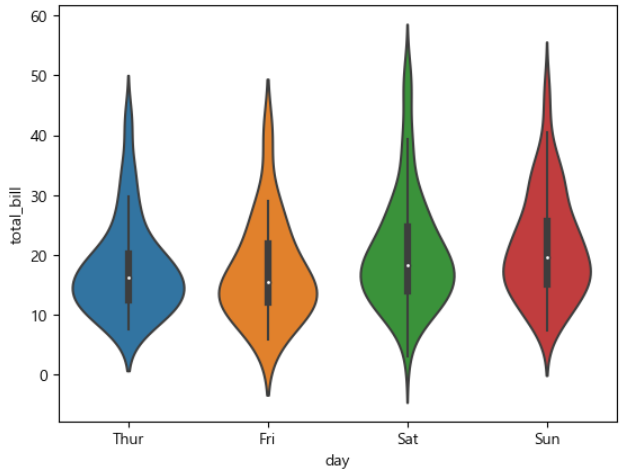
sns.stripplot(x="day",y="total_bill",hue="smoker",data=tips)
plt.show()

두께가 아니라 점으로 데이터의 밀집 형태를 표현하는데 점이 겹쳐 보일 수가있습니다.
sns.swarmplot(x="day",y="total_bill",hue="smoker",data=tips)
plt.show()
-pairplot:데이터 프레임의 컬럼이 숫자로만 된 경우 2개씩 조합해서 모든 경우의 조합의 산포도를 출력
예전 API 에서는 데이터프레임의 문자로 된 컬럼이 있으면 제외하고 만들어주었는데 변경된 API 에서는 문자로된 컬럼이 있으면 에러를 발생시킴
파이썬이나 R은 Open Source 진영의 라이브러리를 많이 사용하기 때문에 시간이 지나서 라이브러리를 다운로드 하면 이전 API 가 제대로 동작하지 않을 수 있습니다.
sns.pairplot(tips)

5)plotnine
=>R의 ggplot 2 에 기반해서 그래프를 그려주는 라이브러리
=>기본 패키지가 아니라서 설치를 해야합니다.
=>https://plotnine.readthedocs.io/en/stable
=>파이썬은 매개변수를 설정할 때 , 로 구분해서 설정하는데 R은 +로 결합이 가능
6)plotly
=>인터렉티브 한 그래프를 그려주는 라이브러리
=>https://plotly/com/python/
=>D3.js 라이브러리를 활용(자바스크립트를 이용해서 차트를 html 에 표현하는 라이브러리)
웹 상에서 동적인 차트가 필요한 경우 사용할 수 있습니다.
=>설치:chart_studion 라이브러리도 함께 설치
7)folium
=>지도를 그려주는 라이브러리
=>자바스크립트 기반으로 interactive 하게 그래프를 그림
=>기본 라이브러리가 아니라서 설치가 필요
=>Map 함수를 이용해서 지도 객체를 생성하는데 locations 옵션에 중앙점의 위도와 경도를 설저하고 zoom_start 옵션에 초기 확대 축소 배율을 설정
=>Chrome 브라우저를 사용하는 Jupyter NoteBook에서는 바로 출력이 가능한데 그 이외의 경우는 html로 저장해서 확인을 해야합니다.
=>단계 구분도를 만들 수 있는데 이 경우 각 지역의 좌표가 필요합니다.
우리나라 지역의 좌표는 https://github.com/southkorea/southkorea-maps 에서 서 다운로드
GitHub - southkorea/southkorea-maps: South Korea administrative divisions in ESRI Shapefile, GeoJSON and TopoJSON formats.
South Korea administrative divisions in ESRI Shapefile, GeoJSON and TopoJSON formats. - southkorea/southkorea-maps
github.com
import folium
m=folium.Map(location=[37.572656, 126.973300],zoom_start=15)
m
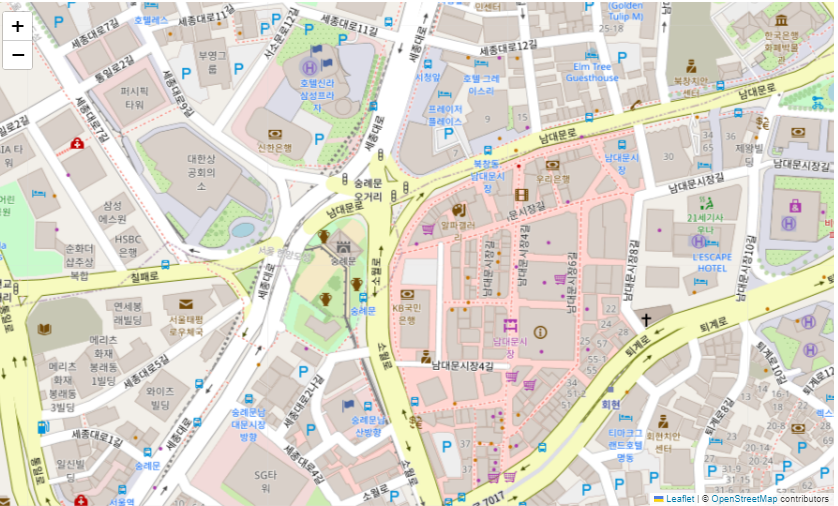
크롬에서 주피터 환경에서는 바로 가능하지만 크롬이 아닌 경우, m이 아닌 m.save('map.html')로 저장해서 사용해야합니다.
=>지도 위에 마커를 표시
folium.Marker(location=[위도,경도],popup="보여지는 문자열",icon=이미지모양).add_to(맵객체)import folium
m=folium.Map(location=[37.572656, 126.973300],zoom_start=15)
folium.Marker(location=[37.572656, 126.973304],popup="KB 국민카드",icon=folium.Icon(icon="cloud")).add_to(m)
m
'Study > Data전처리 및 통계' 카테고리의 다른 글
| Pandas(6)-Scaler 및 Normalization (0) | 2024.02.16 |
|---|---|
| Pandas(5) (0) | 2024.02.15 |
| Pandas(3) (0) | 2024.02.13 |
| Pandas(2) (1) | 2024.02.08 |
| Pandas(1) (0) | 2024.02.07 |



