**Pandas 를 이용한 데이터 수집
1.클립보드의 내용을 읽어오기
=>pd.read_clipboard()
2.자주 사용하는 dataset
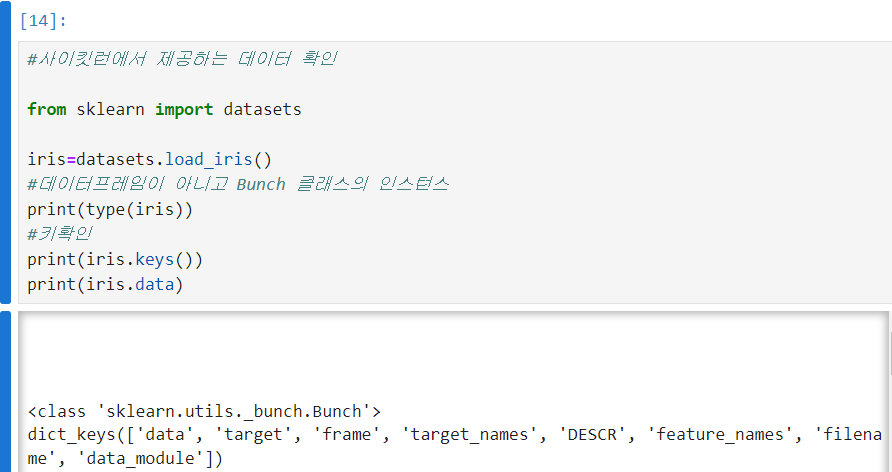
scikit-learn이나 seaborn에서 제공하는 데이터셋
load_digits()
load_boston()
load_iris()
load_diabetes()등등 존재함
=>UCI 머신러닝 저장소:https://archive.ics.uci.edu/ml/index.php
=>kaggle:https://www.kaggle.com
=>데이콘:dacon.io
3.텍스트 파일의 데이터 읽기
=>텍스트 파일을 읽을 떄는 파일의 포맷과 인코딩 방식을 확인할 필요가 있음
=.인코딩 방식:utf-8,euc-kr.cp949(ms949-윈도우 한글 기본 포맷) 가 한글에 적용
1)fwf 파일 읽기
=>일정한 간격을 가지고 컬럼을 구분하는 텍스트 파일
=>읽기 위한 API
pandas.read_fwf('파일 경로',widths=(글자사이간격),names=(컬럼이름나열),encoding=인코딩방식)
#window환경에서는 \을 2개씩 해야함
df=pd.read_fwf('C:\\Users\\User\\Desktop\\lg헬로비전\\python\\numpy,pandas\\data\\data\\data_fwf.txt',widths=(10,2,5),names=(1,2,3))
print(df)
2)csv 파일 읽기
=>csv:구분 기호로 분리된 텍스트 파일
pandas.read_csv:기본 구분자가 ,
pandas.read_table:기본 구분자가 탭
=>첫번째 매개변수로 파일의 경로를 설정
아무런 옵션이 없으면 첫번째 줄 데이터를 컬럼 이름으로 사용
=>item.csv 불러오기
df=pd.read_csv('C:\\Users\\User\\Desktop\\lg헬로비전\\python\\numpy,pandas\\data\\data\\item.csv')
print(df)
print(df.info())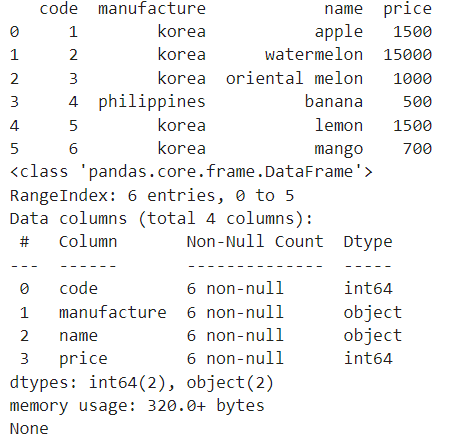
=>옵션
path:데이터 경로
sep(delimiter):구분자 설정
header:칼럼의 이름의 행번호를 설정하는 것으로 기본은 0이고 없을때는 None 을 설정
index_col:인덱스로 사용할 컬럼 번호 나 컬럼 이름을 설정
names:컬럼이름으로 사용할 list로 설정할 수 있는데 header=None 일떄만 사용
skiprows:읽지 않을 행의 개수
nrows:읽어올 행의 개수
skip_footer:무시할 마지막 행의 개수
encoding:인코딩 설정
na_values:NA 값으로 처리할 문자의 list
parse_dates;날짜 텍스트를 문자열이 아니라 날짜로 인식할 수있도록 하기 위한 설정은 기본은 False라서 날짜 형식의 문자열을 문자열로 인식
=>csv 파일을 읽을 때는 파일의 용량이 크지 않다면 먼저 파일을 열어서 첫번째 행이 컬럼의 이름인지 확인하고 한글이 포함되어 있는지 확인하고 구분기호가 무엇인지 확인해봐야합니다
=>데이터의 양이 아주 많은 경우에는 한번에 읽으려고 하면 실패하는 경우가 많습니다
이런경우에는 nrows 속성을 이용해서 시작위치에서 일부분의 데이터만 읽어오고 skiprows 를 이용해서 읽을 수 있고 다른 방법으로는 chunksize를 서정해서 한 번에 읽을 데이터의 개수를 설정하고 이 떄 리턴되는 TextParser 객체를 순회하면서 읽을 수 도 있습니다.
#good.csv 파일의 데이터를 2개씩 읽기
#이방법의 경우에는 데이터의 개수를 알거나 예외처리 해야함
parser=pd.read_csv('C:\\Users\\User\\Desktop\\lg헬로비전\\python\\numpy,pandas\\data\\data\\good.csv',header=None,chunksize=2)
for piece in parser:
print(piece)
=>문자열이 " " 나 ' '으로 감싸 있는 경우 pandas 로 못읽는 경우가 발생할 수 있습니다.
이런 경우에는 csv.reader 함수를 이용할 수 있습니다.
3)csv로 저장
=>Series 나 DataFrame의 to_csv 메서드를 호출하면 되는데 첫번째 매개변수로 파일의 경로를 설정해야하고 sep옵션으로 구분자를 설정할 수 있고 na_rep 옵션으로 NaN값을 원하는 방식으로 설정할 수 있고 기본적으로 index와 컬럼이름이 저장되는데 index 와 header 에 False 를 설정하면 출력되지 않습니다. cols 옵션을 이용해서 컬럼 이름을 list로 설정하면 설정한 컬럼만 파일에 저장이 됩니다.
gangnam_2022.to_csv('gangnam.csv',sep=',',index=False,encoding="euc-kr")
4)엑셀 파일 읽기
=>pandas.read_excel("파일 경로")와 pandas.io.excel.read_excel("파일경로")를 이용하면 되는데, 옵션은 read_csv와 거의 유사한데 sep는 없습니다. 엑셀은 시트가 따로 구분되므로 sheet_name 속성을 이용해서 읽어올 시트 이름을 설정할 수 있습니다.
=>anaconda를 사용하는 경우는 패키지가 내장되어 있는데 그렇지 않은 경우 xlrd 패키지를 설치:pip install xlrd
4.엑셀 파일로 저장
엑셀 파일 경로를 갖는 라이터변수=pandas.ExcelWriter("엑셀파일경로",engine="xlsxwriter")
데이터프레임.to_excel(라이터변수,sheet_name='시트 이름')
라이터변수.save()
=>아나 콘다 배포판이 아니면 openpyxl 패키지를 설치해야합니다.
#엑셀 파일 저장
writer=pd.ExcelWriter("sample.xlsx",engine="xlsxwriter")
#엑섹 파일에 바로 기록하는 것이 아니고 임시 파일에 기록을 합니다
df.to_excel(writer,sheet_name="excel")
#파일을 닫을 때 임시 파일의 내용을 원본 파일에 기록을 합니다
#flush한다라고 표현합니다
writer.close()
5.Web의 데이터 읽기
1)HTML에 있는 table 태그의 모든 가져오기
=>pandas.read_html('파일의 경로나 URL')을 이용하면 table 태그의 내용을 DataFrame 으로 만들어서 DataFrame의 list를 리턴합니다.
=>옵션으로 천단위 구분기호 설정, 인코딩 방식(우리나라-ut-8,euc-kr),na 데이터 설정 등이 있습니다.
브라우저 주소:
https://ko.wikipedia.org/wiki/인구순_나라_목록
인구순 나라 목록 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 2018년 세계 인구의 카토그램; 각 정사각형은 50만 명을 나타낸다. 아래의 도표는 각국 통계청의 인구 통계를 기준으로 집계한 각국의 인구를 순서에 따라 나열
ko.wikipedia.org
프로그램에서 사용하는 주소: https://ko.wikipedia.org/wiki/%EC%9D%B8%EA%B5%AC%EC%88%9C_%EB%82%98%EB%9D%BC_%EB%AA%A9%EB%A1%9D
인구순 나라 목록 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 2018년 세계 인구의 카토그램; 각 정사각형은 50만 명을 나타낸다. 아래의 도표는 각국 통계청의 인구 통계를 기준으로 집계한 각국의 인구를 순서에 따라 나열
ko.wikipedia.org


2)웹에서 데이터 가져오기
=>웹에서 데이터를 가져오기
=>데이터를 파싱(데이터를 해석해서 원하는 데이터를 추출)
=>웹에서 제공되는 텍스트 데이터 종류
-XML:데이터를 태그 형식으로 표현하는데 해석은 사용자가 합니다
-예전에는 많이 사용했고 현재는 일부 RSS 나 설정 파일에 주로 이용
<Persons>
<Person>
<name>귀도반로썸</name>
<language>파이썬</langauge>
</Person>
</Persons>
JSON:
-자바스크립트의 객체 표현법으로 데이터를 표현하는 방식
-최근의 API에서는 대부분 JSON만 지원
{"pesons":[{"name":"하일스베르","language";"C#"}]}
YAML(yml,야믈)
-가장 최근에 등장한 포맷으로 이메일 형식으로 데이터를 표현하는 방식
-클라우드 환경에서 설정 파일의 대부분은 YAML
persons:
person:
name:하일스베르
language:typescript
person:
name:래리앨리슨
language:오라클
HTML
-웹 브라우저가 해석해서 화면에 랜더링하기 위한 포맷
-구조적이지 않아서 데이터를 표현하는데는 사용하기가 어려움
-API를 제공해주지 않는 사이트에서 화면에 보여지는 데이터를 추출하기 위해서 다운로드 받아서 사용
3)웹에서 데이터 가져오기
=>urllib 와 urllib2 라는 파이썬 내장 모듈을 이용해서 웹의 데이터를 가져올 수 있음
내장 모듈의 request 라는 객체의 urlopen이라는 메서드에 url을 문자열로 대입하면 url에 해당하는 데이터를 response type의 객체로 리턴
response 객체의 getheaders()를 이용하면 제공하는 데이터의 정보를 읽을 수 있고 read()을 호출하면 내용을 읽을 수 있습니다.
읽어온 내용이 한글이 포함되어 있다면 인코딩 설정을 해야할 수 있는데 이때는 read().decode("인코딩 정보")를 이용해야합니다.
import urllib.request
result = urllib.request.urlopen("https://www.kakao.com")
print(result.read())
=>URL에는 한글이 포함되어 있으면 인코딩해서 설정
문자열을 인코딩하고자 하면 urllib.parse 모듈의 quote_plus와 quote 함수를 이용하면 됩니다.
두 함수의 차이는 공백을 +로 처리하느냐 %20으로 처리하느냐의 차이입니다
=>한겨례 신문사에서 사이버가수아담의 검색 결과를 가져오기
한겨례 신문사의 검색 URL:https://search.hani.co.kr/search?searchword=검색어
import urllib.request
#한글을 인코딩
from urllib.parse import quote
keyword=quote("사이버가수아담")
result = urllib.request.urlopen("https://search.hani.co.kr/search?searchword="+keyword)
print(result.read())
=>request 패키지를 활용한 웹의 데이터 가져오기
Get,Post,Delete 요청을 사용할 수 있고 데이터 인코딩이 편리한 패키지
파라미터를 넘겨줄 데이터를 dict로 만들어서 GET이나 POST 등에서 사용하면 인코딩을 자동으로 수행
requests.get(url)을 호출하면 웹 페이지의 결과를 Response 객체를 리턴
Response.txt 을 이용하면 문자열을 가져올 수 있고 content 속성을 호출하면 bytes을 리턴
외부 패키지라 pip install requests 을 이용해 설치를 해야 합니다.
import requests
resp= requests.get("http://httpbin.org/get")
print(resp.text)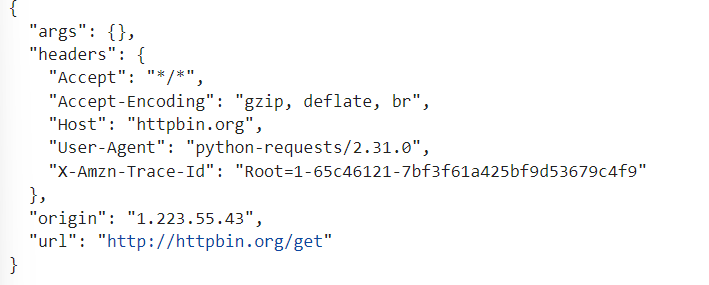
#파라미터 생성
param={"id":"itstudy","name":"군계","age":53}
#파라미터와 함꼐 post 요청
resp=requests.post("http://httpbin.org/post",data=param)
print(resp.text)
#이미지 파일 다운로드
imgurl="https://i.namu.wiki/i/E_8fp_B1t4xd78EQ3WQXD7V88vY1Kyg7_cL4LNDBIRh94djU7zfd7ijtoHoS3B-krtE5zE-Wn00vkC7CAoX3rTZqD4qaRdliNacG3Ay2HUzYWKscxzDKn07rCKFTtubHYtQLOu-cvTbYAaU7E-NK3g.webp"
#저장할 파일 이
filename = "lesserafim.jpg"
try:
#다운로드
resp=requests.get(imgurl)
#파일에 저장
with open(filename,"wb") as h:
#다운로드 받을 내용을 bytes 수로 리턴
img=resp.content
h.write(img)
except Exception as e:
print(e)
4)json파싱
=>방법
-requests 를 이용해서 다운로드 받은 후 직접 파싱하는 방법
-pandas.read_json을 이용해서 자동으로 파싱하도록 하는 방법
=> 옵션이 많으면 requests을 이용해서 다운로드 받아서 사용하는 것이 낫고 데이터의 구조가 단순하다면 pandas를 이용하는것이 편리합니다.
=>pandas 의 read_json을 이용해서
에서 영화 제목과 평점 만 추출해서 출력
df=pd.read_json("http://swiftapi.rubypaper.co.kr:2029/hoppin/movies?version=1&page=1&count=30&genreId=&order=releasedateasc")
#print(type((df)))
hoppin=df["hoppin"]
#print(hoppin)
movies=hoppin["movies"]
#print(movies)
movie=movies["movie"]
#print(movie)
for item in movie:
print(item["title"]+":"+item["ratingAverage"])
{}일때는 하나하나씩 벗겨나가서 마지막에 배열이 될 때 for 문을 이용해서 아이템을 출력하면 됩니다.
=>파이썬의 기본 모듈을 이용해서 json파싱
json.loads(문자열)을 이용하면 json 문자열을 파싱해서 파이썬 dict 나 list 을 만들어줍니다.
{로 시작하면 dict가 되고 [로 시작하면 list가 됩니다.
5)카카오 검색 API 데이털를 가져와서 MySQL에 저장
=>카카오 검색 API를 사용하기 위한 준비
developers.kakao.com에 접속해서 로그인
내 애플리케이션을 클릭해서 애플리케이션을 생성
네이티브 앱키: 안드로이드 용
REST API 키: 데이터 가져올때 용
JS 키:웹에서 쓸 떄용
Admin:카카오톡 로그인 용
Rest API 키를 복사
[제품]-[검색] 에서 문서확인을 통해 활용하기
=>카테고리로 장소 검색
https://dapi.kakao.com/v2/local/search/category.json
파라미터
category_group_code ->PM9(약국)
x,y,radius ->중앙점의 위치와 반경을 설정하는 것이 필수임. rect로 2개의 자표을 설정해도됨
page->페이지 번호
size-> 한 번에 가져올 데이터 수
sort->정렬 옵션
#카카오 Open API 주변약국데이터 가져오기
import requests
import json
#url 만들기
url ='https://dapi.kakao.com/v2/local/search/category.json?category_group_code=PM9&rect=126.95,37.55,127.0,37.60'
#헤더 설정
headers = {'Authorization': 'KakaoAK {}'.format('각자REST API 키')}
data= requests.post(url,headers=headers)
#print(type(data.text))
result=json.loads(data.text)
#print(result)
#documents 키의 데이터를 가져오기
documents=result['documents']
#print(documents)
for item in documents:
print(item['place_name'],":",item['address_name'])

=>카카오톡 이미지데이터 가져오기
#카카오 Open API 이미지데이터 가져오기
import requests
import json
from urllib.parse import quote
from IPython.display import display, Image
keyword=quote("뉴진스")
#url 만들기
url ='https://dapi.kakao.com/v2/search/image?query='+keyword+'&sort=recenecy'
#헤더 설정
headers = {'Authorization': 'KakaoAK {}'.format('44254e8c4edf28dcb284da2129bc5eaf')}
data= requests.post(url,headers=headers)
#print(data.text)
result=json.loads(data.text)
#print(result)
a=result['documents']
#print(a)
for i,image in enumerate(a):
if i >=5:
break
image_url = image['image_url']
print(image_url)
display(Image(url=image_url))

=>MySQL 연동
-패키지 설치
!pip install pyMySQL
-데이터 베이스 접속 확인
import pympysql
con=pymysql.connect(host="데이터베이스 위치",port=포트번호,user="아이디",password="비밀번호",db="데이터베이스이름",charset='인코딩방식')
con.close()
- SELECT을 제외한 구문 실행
import pymysql
con=pymysql.connect(host="127.0.0.1",port=3306,user="bkbk",password="0000",db="bkbk")
#연결 객체를 가지고 cursor()을 호출해서 커서 객체 생성
#테이블 생성 구문 실행
cursor=con.cursor()
#sql 실행
cursor.execute("create table phamacy(placename VARCHAR(30), addressname VARCHAR(200))")
for doc in documents:
cursor.execute("insert into phamacy(placename,addressname) values(%s,%s)",(doc["place_name"],doc["address_name"]))
#commit
con.commit()
#print(con)
con.close()
-SELECT 의 경우는 execute 다음에 커서를 이용해서 fetch_one 이나 fetchall()를 호출해서 튜플을 가져와서 읽음
6)XML Parsing
=>한겨레 rss 에서 title과 link 뽑아오
=>사용할 URL:https://www.hankyung.com/feed/it
=>파싱 방법
#baseline
import xml.etree.ElementTree as et
#urllib.request 을 이용해서 읽어온 데이터:res
#메모리에 펼치기
tree= et.parse(res)
#루트 찾기
xroot = tree.getroot()
#특정 태그의 데이터 가져오기
items = xroot.findall('태그')
#태그는 여럭개 나올 수 있으므로 반복문을 수행
for node in items:
node.find(태그).text#태그안에 데이터#한겨레 rss 파시
import urllib.request
url="https://www.hankyung.com/feed/it"
request=urllib.request.Request(url)
response=urllib.request.urlopen(request)
#print(response.read())
#xml파싱
#메모리에 트리 형태로 펼치기
import xml.etree.ElementTree as et
tree=et.parse(response)
root=tree.getroot()
items=root.findall('.//item')
for item in items:
title = item.find('title').text
link = item.find('link').text
print(title, ":", link)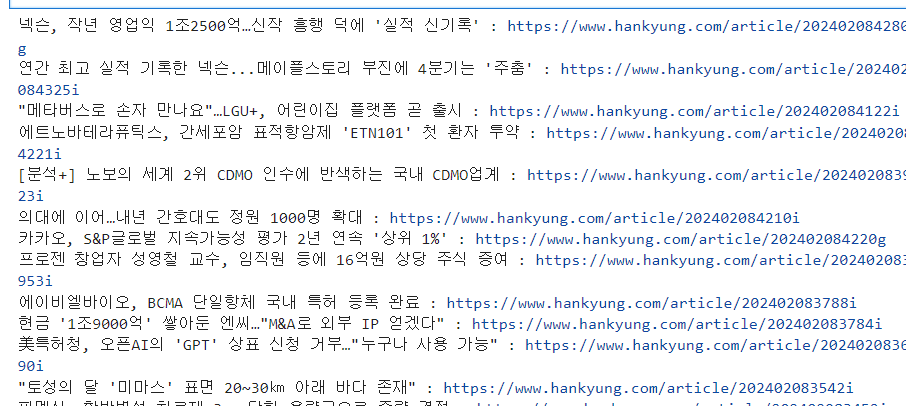
6)HTML Parsing
=>Beautiful Soup 패키지 이용 - 아나콘다에서는 내장
pip install beautifulsoup4
-HTML을 XML로 변환해서 파싱
-모듈을 import 할때는 bs4 를 import
-메모리에 펼치기
bs4.BeatifulSoup(파싱할 html,"html.parser")
-태그 안의 데이터 찾기
bs.태그이름나열.get
import requests
import bs4
resp=requests.get("http://finance.daum.net/")
html=resp.text
#print(html)
bs=bs4.BeautifulSoup(html,'html.parser')
print(bs.body.div.get_text())=>find 함수
find(태그,속성,recursive,text,limit,keywords)
-태그에는 찾고자하는 태그를 설정
-attribute(속성)에는 태그 중에서 특정 속성의 값만 가져오고자 할 떄 사용
-recursive는 False이면 최상위 태그에서만 찾고 True를 설정하면 하위로 들어가면서도 찾음
-일치하는 태그 1개를 찾아옵니다
-일치하는 태그 여러개를 찾고자 하는 경우는 find_all 을 이용
=>select 함수
선택자를 이용해서 찾아오는 함수
=>bs4.element.Tag
find와 select의 결과는 Tag클래스의 list
Tag 클래스에서 getText()를 호출하면 태그가 감싸고 있는 텍스트를 가져올 수 있고 get('속성이름')은 속성의 값을 가져올 수 있습니다.
선택자는 앞에서부터 생략도 가능
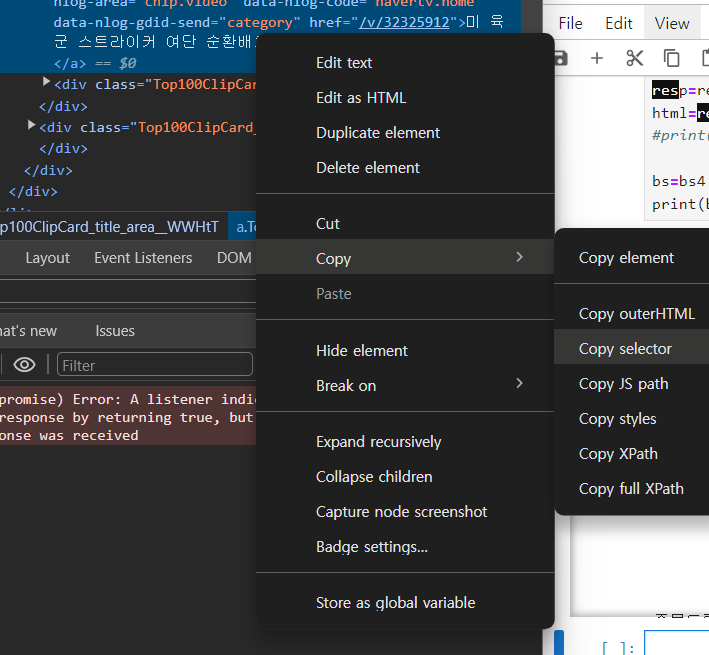
#content > section > div > div.flex-inner > div.left > div:nth-child(1) > ul > li:nth-child(2) > article > a > div.article-list-cont > strong
=>한겨레 신문사 기사에서 제목을 추출
https://search.hani.co.kr/search?searchword=%EC%95%84%EB%8B%B4
import requests
import bs4
resp=requests.get("https://search.hani.co.kr/search?searchword=%EC%95%84%EB%8B%B4")
html=resp.text
#print(html)
bs=bs4.BeautifulSoup(html,'html.parser')
tags=bs.select('article > a > div.article-list-cont > strong') #잎에 있는데 굳이 안지워도됨
for tag in tags:
print(tag.getText())



