** 확률
1.주피터 노트북에서 수학 기호사용
=>TeX 라는 수학기호를 활용하여 사용
2.기본 패키지
import numpy as np
import pandas as pd
import seaborn as sns
import scipy as sp
import scipy.status
#시각화 패키지
import matplotlib.pyplot as plt
#시각화에서 한글 사용하기 위한 설정
#운영체제 별 폰트 설정
from matplotlib import font_manager, rc
import platform
if platform.system() =='DarWin':
rc('font',family='AppleGothic')
elif platform.system() =='Windows':
font_name=font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font',family=font_name)
#시각화에서 음수를 표현하기 위한 설정
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
#소수점 이하 3자리로 제한
%precision 3
pd.options.display.precision = 33.집합(SET)
1)개요
=>집합은 구별 가능한 객체의 모임 - 데이터에 중복이 존재할 수 없음
=>집합은 알파벳 대문자를 이용해서 표현하고 원소는 알파벳 소문자로 표시
=>Python 에서는 set과 frozenset 자료형으로 집합을 나타내는데 set은 내용을 변경할 수 있는 mutable 자료형이고 frozenset 은 내용을 변경할 수 없는 immutable 자료형
2)연산
=>set에서는 합집한이나 교집합, 차집합을 구해주는 함수가 제공
=>합집합이나 교집합은 | 나 &을 활용해서 연산이 가능
#set은 & 연산자 가능( __and__ 가 존재)
#원래는 함수이지만 연산자를 이용해서 호출할 수 있도록 작성 - 연산자 오버로딩
#Overloading:동일한 이름의 메서드가 2개 이상 존재하는 경우로 이 메서드는
#매개변수의 개수나 자료형이 달라야 합니다.
print({1,2,3} | {2,3,4}) # 합집합
print({1,2,3} & {2,3,4}) #교집합
print({1,2,3} > {2,3}) #부분집합 여부
print({1,2,3} - {1,2}) #차집합4.확률
1)확률의 정의와 의미
=>확률은 현실에서 해결하고자 하는 문제와 결부해서 정의
=>확률은 어떤 문제가 어떤 답을 가질 수 있고 그 답의 신뢰성이 얼마나 되는지 계산하는 정량적인 방법 제시
ex.) 동전을 던졌을 때 앞면인가 뒷면인가 의 문제
2)확률에서 나오는 개념
=>확률 표본( random sample, probablilistic sample)
표본은 풀고자 하는 확률적 문제에서 발생할 수 있는 하나의 현상 혹은 선택될 수 있는 하나의 경우
=>표본 공간: 가능한 모든 표본의 집합으로 그리스 문자 오메가 표기
=>시행: 조작
=>표본 공간의 예시
동전 던지기를 하는 경우 표본 공간은 도메인 지식을 바탕으로 결정
일반적으로 동전은 앞면과 뒷면만 나올 것 같기 때문에 표본 공간은 앞면, 뒷면 두가지로 설정
특별한 경우에는 표본 공간의 개수가 무한대가 되기도 함
주식의 등락폭: -30% ~ 30%
=>사건(event):표본 공간의 부분 집합으로 우리가 관심을 가지는 일부 표본의 집합
시행에서 얻을 수 있는 사건의 모든 집합을 전사상이라고 함
동전던지기에서 나올 수 있는 표본은 앞면과 뒷면
전사상:{},{앞면},{뒷면},{앞면,뒷면}
=>확률
-모든 각각의 사건에 어떤 숫자(정량)을 할당하는 함수
-함수가 지켜야 할 규칙:콜모고로프의 공리
모든 사건에 대해 확률은 실수이고 0 또는 양수
표본 공간이라는 사건에 대한 확률은 1
공통 원소가 없는 두 사건의 합집합의 확률은 사건별 확률의 합
-대문자 P로 표시
3)확률을 바라보는 관점
-빈도주의 관점
반복적으로 선택된 표본이 사건 A의 원소가 될 경향을 사건의 확률이라고 보는 것
확률이 0.5 라는 것은 100000번 시행했을 때 5000번이 나오는 경향
-베이지안 관점
신뢰도를 의미하는 것
확률이 0.5 라는 것은 1번 실행 했을 때 그 사건이 발생할 가능성이 50%
-보는 각도에 따라 빈도주의 관점이 될수도, 베이지안 관점이 될 수도 있음
의사가 병이 걸렸을 가능성이 70%라고 진단
의사 입장에서는 여러 명의 환자를 진찰 하기 때문에 10명이 진료를 받았을 때 7명이 병에 걸려 있다라는 의미가 되고 환자 입장에서는 내가 병에 걸렸을 가능성이 70%라고 해석
4)확률의 성질
=>발생할 수 없는 사건의 확률은 0
=>어떤 사건의 여집합인 사건의 확률은 1- (원래 사건의 확률)
=>두 사건의 합집합의 확률은 각 사건의 확률의 합에서 두 사건의 교집합의 확률을 뺀 것
5)결합 확률
=>사건 A와 B가 동시에 발생할 확률
=>두 사건의 교집합
6)주변 확률
=>개별 사건의 확률
범인 찾기 문제
-전체 인원은 20명이고 남자는 12명 여자는 8명
-남자는 머리가 긴 사람 3명, 여자는 머리가 긴 사람이 7명
-범인이 남자이고 머리가 길다면 결합확률은 남자이고 머리가 긴 사람은 3명이므로 3/20
-주변 확률은 남자일 확률은 12/20 이고 머리가 길 확률은 10/20
7)조건부 확률
=>B가 사실일 경우 사건 A에 대한 확률이 사건 B에 대한 사건 A의 조건부확률
A와 B의 주변 확률을 B의 확률로 나눈 것
8)확률을 위한 패키지
!pip install pgmpy앞에 !를 붙이는 것은 이 명령은 파이썬 코드가 아니고 운영체제에게 수행하도록 하는 명령이라는 것을 명시적으로 표현하기 위해 붙임
9)확률을 구해주는 - pgmpy
=>JointProbabilityDistribution(variables, cardinality,values)
- 결합 확률 모형을 만드는데 사용하는 클래스
- variables 는 확률 변수 이름으로 문자열의 리스트로 정의, 문자열이 1개여도 list을 사용해야 합니다
-cardinality(행의 개수)는 각 확률 변수의 표본 또는 사건 수의 리스트
-values: 확률 변수의 모든 표본에 대한 확률 값의 리스트
=>남자가 12명이고 여자가 8명일 때 독립 확률
#남자가 12명 여자가 8명인 경우의 독립 확률
from pgmpy.factors.discrete import JointProbabilityDistribution as JPD
#남자 와 여자는 상호배타 적인 사건이라서 하나의 확률 변수로 표현
#두번째 2는 확률 변수에 대한 사건의 개수
px=JPD(['X'],[2],np.array([12,8])/20)
print(px)
=>결합 확률: 확률 변수가 2개 이상인 경우
남자 12명이고 머리가 짧은 사람 9명 긴 사람이 3명
여자 8명이고 머리가 짧은 사람 1명 긴 사람이 7명
확률 변수가 2개 필요 - X, Y
각 확률 변수의 사건의 개수 -2 ,2
확률 값은 9,3,1,7
#결합 확률
#X:남자,여자
#Y: 머리가 짧다 길다
px = JPD(['X','Y'],[2,2],np.array([3,9,1,7])/20)
print(px)
=>marginal _distribution(values,inplace=True)
-주변 확률을 구해주는 함수
-values 에 주변 확률을 구할 확률 변수의 이름 문자열 리스트
-JPD 객체를 이용해서 호출
=>marginalize(values,inplace=True)
- values 에 어떤 확률 변수의 주변 확률을 구하기 위해서 없애줄 확률 변수의 이름 리스트
=>conditional_distribution(values,inplace=True)
#주변 확률
pxy= JPD(['X','Y'],[2,2],np.array([3,9,1,7])/20)
pmx=pxy.marginal_distribution(['X'],inplace=False)
print(pmx)
pmy=pxy.marginal_distribution(['Y'],inplace=False)
print(pmy)
10) 베이즈 확률
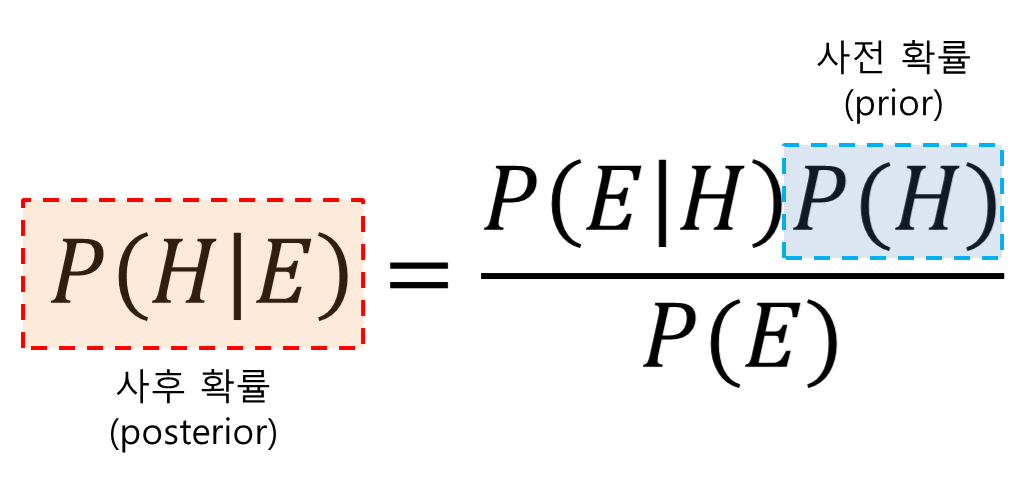
-개요
조건이 주어졌을 때 조건부 확률을 구하는 공식
새로운 데이터가 주어지기 전에 이미 어느 정도 확률 값을 알고 있을 때 이를 새로 수집한 데이터와 합쳐서 최종 결과에 반영
데이터 개수가 부족할 때 유용
데이터를 추가적으로 얻는 상황에서 전체 데이터를 대상으로 새로 분석 작업을 할 필요없이 이전 분석 결과에 새로 들어온 데이터를 합쳐서 업데이트만 수행하면 됩니다.
조건부 확률 공식((P(B|A)P(A)) / P(B))
P(B|A)를 가능도(likelihood)라고 표현
P(B)를 정규화 상수(Normalizing Constant) 또는 증거(Evidence)라고도 함
- 베이즈 정리를 이용한 검사 시약 문제
시약이 병에 걸렸는지 확인을 하는데 병에 걸린 환자에게 시약을 테스트한 결과 99%확률로 양성 반응을 보인 경우 병에 걸렸는지 알 수 없는 환자에게 시약을 이용해서 검사를 했는데 양성이 나온 경우 병에 걸렸을 확률은?
추가 조사를 했는데 이 병에 걸린 사람은 전체 인구의 0.2%
이 병에 걸리지 않은 사람에게 시약 검사를 했을 때 양성반응이 나타날 확률이 5%
(0.99 * 0.002) / ((0.99 * 0.002) + 0.05*(1-0.002))
-몬티홀 문제
세 개의 문 중에 하나의 문 뒤에 선물이 있고 나머지 2개의 문 뒤에는 선물이 없는 경우
하나의 문을 열어서 선물이 없다는 것을 보여주고 현재 선택한 문을 바꿀 것인지 하는 문제
실제로 계산해보면 계산을 수행해보면 바꾸는 것이 바꾸지 않는 것보다 확률이 2배가 높음
문의 위치를 0,1,2 라는 숫자로 표현
선물이 있는 문을 나타내는 확률변수를 C로 하면 값은 0,1,2
참가자가 선택한 문을 나타내는 확률변수를 X로 하면 값은 0,1,2
진행자가 열어준 문을 나타내는 확률변수를 H로 하면 값은 0,1,2
참가자가 1번 문을 선택했고 진행자가 2번 문을 열어서 선물이 없다는 것을 보여준 경우인데 이렇게 되면 이진 분류 문제가 됩니다.
선물은 0번 아니면 1번에 존재
진행자가 어떤 문을 여는가 하는 것은 선물의 위치 와 참가자의 선택에 따라 달라지게 됩니다
선물이 0번 문 뒤에 있고 참가자가 1번문을 선택하면 진행자는 2번 문을 열 수 밖에 없음
선물이 1번 문 뒤에 있고 참가자자 1번문을 선택하면 진행자는 0번과 2번 아무거나 열 수 있음 -1/2
참가자가가 1번 문을 선택하고 진행자가 2번 문을 열어서 선물이 없다는 것을 보인 경우에 0번 문 뒤에 선물이 있을 확률
(1/3) /( (1*1/3)+ (1/2+1/3) + (0*1/3)) => 2/3
**기술통계
1.통계
=>논리적 사고와 객관적인 사실에 따르며 일반적이고 확률적 결정론에 따라서 인과 관계를 규명
=>연구 목적에 의해 설정된 가설들에 대하여 분석 결과가 어떤 결과를 뒷받침하고 있는지를 통계적 방법으로 검정
=>분류
기술 통계: 수집된 데이터의 특성을 쉽게 파악하기 위해서 데이터를 표 나 그래프 또는 대표값으로 정리 요약하는 통계
추론 통계: 기술 통계량 과 모집단에 추출한 정보를 이용해서 모집단의 특성을 과학적으로 추론
2.변수(feature)의 종류
1)질적 변수와 양적 변수
=>질적 변수: 구분을 위한 변수, 범주형,명목 척도와 순서 척도
=>양적 변수: 양을 표현하는 변수, 등간 척도와 비율 척도
=>범주형의 데이터를 머신러닝에 사용하기 위해서 원핫 인코딩을 하게 되면 수치 데이터로 변경이 되는데 이는 양적 변수가 아닙니다.
점수:0과 1
성별:0과 1로 표현
2)척도(scale)수준
=>명목(nominal) 척도:순서가 없는 범주형 데이터
=>순서(ordinal) 척도:순서가 있는 범주형 데이터
=>등간(interval) 척도: 0값이 기준이 되지 않은 데이터
=>비율(ration) 척도: 기준 0값의 의미가 있는 데이터로 상대적 양
3)데이터 가져오기 - descriptive.csv
=>부모의 학력 수준에 따른 자녀의 대학 진학 합격 여부를 조사한 데이터
=>300개의 행과 8개의 컬럼으로 구성
resident: 거주 지역(1,2,3 - 특별시,광역시,시군)
gender:성별( 1,2 - 남과 여)
age:나이
level:학력 수준(1,2,3 - 고졸 이하, 대졸, 대학원졸)
cost:생활비
type: 학교 유형(1,2)
survey:만족
pass: 합격 여부(1,2)
4)명목 척도
=>구별 만을 위해서 의미 없는 수치로 구성한 데이터
=>거주 지역이나 성별과 같은 데이터
=>이러한 데이터는 요약 통계량을 구하는 것은 의미가 없고 구성 비율 정도가 의미 있음
#자료형 확인이 가능하고 결측치도 확인 가능
#성별은 명목 척도
#명목 척도는 데이터의 개수 정도만 확인 - 이상치 확인 가능
print(university['gender'].value_counts())
#0과 5번 데이터는 이상치라서 제거해야함-(직접 제거해도 되고 올바른 데이터만 필터링)
university_gender= university[(university['gender'] ==1) |(university['gender'] ==2)]
print(university_gender['gender'].value_counts())
5)순서 척도
=>순서를 정하기 위해서 만들어진 수치 데이터
=>계급 순위를 수치로 표현한 직급이나 학력 수준등
=>기초 통계량 중에서 빈도수 정도만 의미를 갖음
#순서척도
#level 이 순서 척도
university_gender['level'].value_counts()
6)등간 척도
=>속성의 간격이 일정한 값을 갖는 척도
=>만족도 처럼 각 데이터끼리 비교가 가능하고 가중치 적용 등이 가능
=>일반적으로 이 데이터는 기술 통계량은 의미를 갖지만 산술 연산을 하지는 않음
기술 통계량을 구하기 위해서는 하지만 데이터끼리 산술 연산을 해서 의미를 부여하기는 어려운 데이터 평균을 구하기 위해서 합계를 구하기는 하지만 합계 자체는 의미가 없음
=>절대 원점이 없습니다.
#등간 척도 - survey
university_gender['survey'].describe()
7)비율 척도
=>등간 척도의 특성에 절대 원점이 존재하는 척도
=>특정 값을 기준으로 한 수치 데이터라서 사칙 연산이 의미를 갖는 척도
=>점수,나이, 무게 등
#비율 척도
print(university_gender['cost'].describe())
#일반적으로 빈도를 직접 구하지는 않는 경우가 많음
#대부분의 경우 일정한 범위로 편집을 해서 빈도를 구합니다
#직접 입력받는 경우가 많아서 이상치 탐지를 수행해야 합니다
#범주화: 2-3:1 , 3-6:2 6초과는 3
cost = university_gender["cost"]
cost= cost[(cost>=2) & (cost <=10)]
cost[(cost>=2) & (cost <=3)] =1
cost[(cost>=3) & (cost <=6)] =2
cost[(cost>6)] =3
#실수를 정수로 변환
cost = cost.astype(int)
print(cost.value_counts())
cost.value_counts().plot.bar(color='k')
8)이산형 데이터와 연속형 데이터(discrete & continuous)
=>이산형 데이터는 0,1,2, ... 와 같이 하나하나의 값을 취하는 변수로 서로 인접한 숫자 사이에 값이 존재하지 않은 변수
주사위의 눈은 1,2,3,4,5,6 이렇게 6가지 종류를 가지고 중간에 다른 값이 존재하지 않으므로 이산형 데이터
=>연속형 데이터는 연속적인 값을 취할 수 있는 데이터로 어떤 두 숫자 사이에 반드시 숫자가 존재하는 형태로 길이 나 무게등
=>연속형 데이터라고 하더라도 측정 정밀도에 한계가 있어서 실제로는 띄엄띄엄 값을 취할 수 밖에 없는것 으로 간주
이렇게 되면 이산형 데이터지만 연속형 데이터로 취급
3.데이터 특성
1)특성 파악
=>평균이나 분산 등의 수치 데이터를 요약해서 파악할 수 있고 그래프를 그려서 시각적으로 데이터를 파악하기도 합니다
2)대푯값
=>데이터를 하나의 값으로 요약한 지표
=>평균(mean):모든 값의 총합을 데이터 개수로 나눈 값 - 산술 평균
기하 평균:평균 비율을 구할 떄 사용하는 평균으로 각 데이터의 비율을 곱한 후 제곱근을 구하는 것
매출액이 100인 회사에서 다음 해의 매출이 110을 기록했고 그 다음해의 매출이 107.8 을 기록 했을 떄 연 평균 성장률은?
산술 평균으로 구하면 첫 해에 10프로 늘어났고 두번째 해에 2프로 감소했으므로 4%
1.1 * 0.98의 제곱근으로 구하면 기하 평균
import math
s=pd.Series([100,110,107.8])
print("산술 평균성장률:",s.pct_change().mean())
print(100*1.04 * 1.04)
#비율의 평균을 구할 떄는 산술 평균이 아닌 기하 평균 사용
print("기하 평균",math.sqrt((110/100)*(107.8/110)))
-조화 평균: 속도의 평균을 구할 떄 사용하는 평균
데이터를 전부 곱하고 2를 곱한 값을 데이터의 합으로 나누는 것
동일한 거리를 한번은 시속 100km 달리고 한번은 60km로 달렸을 때 평균 속도는?
(2*100*60)/(100+60)
#조화 평균 - 속도의 평균
#300km을 한번은 시속 100km 로 달리고 한번은 60km로 달린경우 속도의 평균은?
print(600/80)
print(600/(((2*100*60))/(100+60)))
-가중 평균(Weighted Mean):가중치를 곱한 값의 총합을 가중치의 총합으로 나눈 값
데이터를 수집할 때 모든 사용자 그룹에 대해서 정확히 같은 비율의 데이터를 수집하는 것은 매우 어렵기 때문에 데이터를 수집한 후 가중치를 부여해서 평균을 구하는 것
여론 조사에서 많이 사용
어느 정당을 지지하는지 알고싶어서 샘플링을 수행해야 하는데 샘플링을 실제 투표권자의 비율대로 수집하는 것은 거의 불가능에 가까움
샘플링을 한 후 샘플링 된 데이터에 투표권자의 비율을 가중치로 곱해수 가중치의 합으로 나누는 방식을 채택
-Outlier(이상치):대부분의 값과 매우 다른 데이터 값(극단값)
-Robust:이상치 또는 극단값에 민감하지 않은 것을 의미하는데 resistant(저항성) 이 있다라고도 합니다.
-Trimmed Mean(절사 평균): 정해진 개수의 극단 값을 제외한 나머지 값들의 평균
이상치를 제거하고 구한 평균은 실제로는 절사 평균
=>median(중앙값)
- 데이터를 크기 순서대로 나열할 때 정확하게 중앙에 위치한 값
- 중앙값은 평균에 비해서 이상치에 강하다는 특성이 있음
데이터가 1,2,3,4,5 ,6,1000 이렇게 존재하는 경우
평균: 145.85
중앙값:4
위의 데이터를 더 잘 설명한 값은 중앙값
- 데이터가 짝수 개일 때는 중앙값은 중앙에 위치한 데이터 2개의 평균
데이터가 1,2,3,4,5,6 이렇게 존재하는 경우 중앙값은 (3+4)/2=3.5
=>평균 과 중앙값: tdata.csv 파일의 성적 컬럼의 평균
tdata=pd.read_csv("C:\\Users\\User\\Desktop\\python_statistics-main\\python_statistics-main\\data\\tdata.csv",encoding='cp949')
#일반적인 산술 평균
print(tdata['성적'].mean())
#중앙값
print(tdata['성적'].median())
#절사 평균 - scipy.stats.trim_mean으로 구하는데 매개변수로 잘라낼 비율을 설정
#10% 제거하고 평균 구하기
from scipy import stats
print(stats.trim_mean(tdata['성적'],0.1))
#3개의 값이 별 차이 없음
print(tdata)
=>가중 평균 - numpy.average 함수를 이용하는데 weights 에 가중치 설정
state 데이터에는 Population이 인구이고 Murder.Rate가 살인 사건 발생 비율인데 살인 사건의 평균 비율을 알고자 할 때 단순하게 murder.rate 의 평균을 구하는 것은 바람직하지 않습니다
인구가 많은 지역은 가중치를 높게 설정하고 인구가 작은 지역은 가중치를 적게 설정해서 평균을 구해야 합니다
가중 중앙값은 wquantiles 패키지의 median 함수를 이용
import wquantiles
#살인율의 평균
#단순 평균
print("단순 살인율의 평균",state['Murder.Rate'].mean())
#가중 평균
print("가중치를 적용한 살인율의 평균",np.average(state['Murder.Rate'], weights=state['Population']))
#가중 중앙값
print("가중치를 적용한 살인율의 평균",wquantiles.median(state['Murder.Rate'], weights=state['Population']))
=>이동 평균
- 데이터가 방향성을 가지고 움직일 때 (시계열 데이터가 대표적) 이동하면서 구해지는 평균
-단순 이동 평균( SMA - Simple Moving Average)
n번째 데이터를 포함한 왼쪽 m 개(window)데이터의 평균
실제 함수는 매번 단순 이동 평균을 계산하지 않고 (이전의 이동평균) + 새로운 데이터 - 가장 오래된 데이터를 계산한 후 윈도우 크기로 나누어서 계산
-누적 이동 평균( CMA -Cumulative Moving Average)
단순 이동 평균과 계산하는 방법은 같은데 윈도우 크기를 설정하지 않고 새로운 값이 들어올 때마다 전체 평균을 다시 구하는 것
-선형 가중 이동 평균(WMA- Weighted Moving Average)
단순 이동 평균 처럼 윈도우 개수(m)을 설정해서 구하는데 가중치가 선형으로 변경됩니다
dot product 연산을 수행: ([ m, m-1,m-2,...,1])[n번째 데이터, .... n-m+1 번째 데이터])
오래된 데이터 일수록 가중치가 선형적으로 감소하기 때문에 선형 가중 이동 평균이라고 합니다
최신의 데이터에 큰 가중치를 제공해서 최신의 데이터가 결과에 더 큰 영향력을 발휘하게 함
목적에 조금 더 유연하게 비선형적인 방식으로 곱해나가기도 합니다.
-지수 가중 이동 평균( EWMA - Exponentially Weighted Moving Average)
span(알파 값)을 설정해서 데이터에 (1-알파)을 지수승으로 적용한 가중치를 이용한 평균
1번째 지수 이동 평균: 1번째 데이터
n번째 지수 이동 평균: (1-a)*(n-1번째 지수 가중 이동 평균)+ a * 현재 데이터 값
알파 값은 일반적으로 2/(windows개수 +1) 으로 설정
=>최빈값(mode)
-데이터베이스 가장 많이 나타나는 값
-Series 나 DataFrame 에서 mode 함수를 호출하며 구해줍니다.
-질적 데이터의 대표값을 구할 때 이용
print(state['Murder.Rate'].mode())
3)변이 추정
=>개요
- 데이터 값이 얼마나 밀집해 있는지 혹은 퍼져있는지를 나타내는 것으로 분산(dispersion)이라고도 함
- 변이를 측정해서 실제 변이와 랜덤을 구분하고 실제 변이의 다양한 요인들을 알아보고 변이가 있는 상황에서 결정을 내리는 등의 작업을 위해서 추정
=>지표
-편차(Deviation):관측된 데이터와 위치 추정을 위한 값(평균) 사이의 차이로 오차 또는 잔차(residual)
편차를 가지고 평균을 구하려고 하면 편차는 음과 양의 부호로 존재해서 서로 상쇄되어 버려서 평균을 구하면 0에 가까운 값이 되버림
-분산(variance): 평균 과의 편차의 제곱한 값들의 합을 n 이나 n-1 로 나눈 값인데 평균 제곱 오차라고도 합니다.
-표준편차(Standard Deviation):분산의 제곱근으로 L2 norm 또는 유클리드 norm
-★평균 절대 오차( Mean Absolute Deviation):평균에 대한 편차의 절대값의 평균으로 L1 norm 또는 맨해튼 norm
-중간 값의 중위 절대 편차(Median Absoulte Deviation from the Median): 중간 값과의 편차의 절대값의 중앙 값
-범위range):최대값과 최소값의 차이
데이터를 scailing 할 때 0~1 사이로 만드는 방법은 (데이터 -최소값)/(최대값 - 최소값)
-순서 통계량(Order Statistics): 최소에서 최대까지 정렬된 데이터 값에 따른 계량형 순서
-백분위 수(Percentile):분위 수라고 하는데 P 퍼센트 값
-사분위 범위(Interquartile Range):75 % 값에서 25% 값을 뺸 값으로 IQR이라고도 합니다.
-자유도(Degrees of Freedom -df)
과학분야에서는 독립적으로 달라질 수 있는 시스템의 매개변수 개수라고도 함
평면에서의 한 점은 평행 이동을 할 때 X와 Y 좌표 2개를 자유롭게 가질 수 있는데 이경우 자유도는 2
통계학에서는 통계적 추정을 할 때 표본 자료 중 모집단에 대한 정보를 주는 독립적인 자료의 수
표준편차나 분산은 표본의 평균에 따른다는 제약조건을 가지기 때문에 1개의 데이터는 독립적이지를 못함
표준 편차나 분산에서는 n-1의 자유도를 설정
ANOVA(분산 분석) 처럼 다수의 집단을 고려할 대는 자유도가 n- 집단의 개수
-분산,표준편차,평균 절대 편차 등은 특이값과 극단값에 로버스트 하지 않기 떄문에 중위 절대 편차를 이용하는 경우가 있음
MAD = median(| 데이터 - 그룹의 중앙값 |)
MAD을 구해주는 함수는 statsmodel.robust.scale.mad 함수
수식: ( 절대값(데이터 - 그룹의 중앙값)의 중앙값 /0.6744897501960817 )
=>변이 추정 실습
#표준편차
print(state['Population'].std())
#IQR - 75% -25%
#변이 추정에 사용하고 이상치를 검출할 때도 이용
#IQR * 1.5 를 곱한 후 25% 숫자에서 뺸 값보다 작은 값이나
#75% 숫자에 더한 값 보다 큰 값을 이상한 데이터로 간주하기도 합니다
#이 방식은 데이터의 개수가 12개 보다 적으면 검출을 못합니다
#이런 경우에는 중위 값을 가지고 보정을 해서 구하기도 합니다.
print(state['Population'].quantile(0.75) - state['Population'].quantile(0.25))
#중위 절대 편차 -MAD
print(abs(state['Population']-state['Population'].median()).median()/0.6744897501960817)
from statsmodels import robust
print(robust.scale.mad(state['Population']))
4)데이터의 분포 탐색
=>분포 탐색을 위한 시각화
-Box Plot(상자 그림): 사각형과 수염을 이용해서 중앙값과 4분위수 그리고 극단치 등을 표시해주는 그림
극단치가 있는 경우 데이터를 스케일링(단위 조정)해서 극단치의 영향력을 감소시키는 방법도 있고 극단치를 제거하고 사용하기도 하고 극단치를 이용해서 별도의 변수를 생성해서 데이터 분서에 활용하기도 합니다
비의 양을 데이터 화 시킬 때 우리나라의 경우 하루에 보통 0에서 100mm 정도 온다고 가정했을 때 비가 1000mm 가 온 날이 있다면 비가 500mm 이상 온 변수를 생성해서 True 와 False로 설정
-도수 분포표 (Frequency Table): 어떤 구간에 해당하는 수치 데이터 값들의 빈도를 나타내는 기록
-히스토그램: 도수 분포표의 내용을 그래프로 표현
-밀도 그림(Density Plot):히스토그램을 부드러운 곡선으로 나타낸 그림으로 KDE(Kernel Density Estimation -커널 밀도 추정) 을 주로 이용
밀도 그림을 그려서 어떤 확률 분포를 따르는지 파악
=>상자 그림 - plot.box
상자 그림은 중앙값과 4분위 수 그리고 극단치를 파악하는데는 좋지만 실제 데이터의 분포를 알아보는 것은 안됨
# 상자 그림
ax= (state['Population']).plot.box(figsize=(3,4))
plt.show()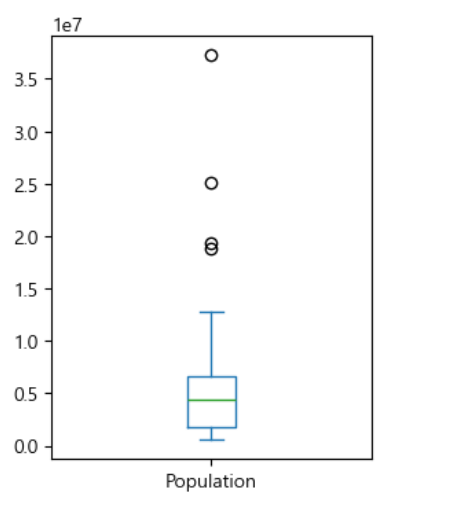
데이터의 분포를 확인하고자 하는 경우에는 scatter(산포도) 나 바이올린 차트등이 유용
상자 그림에서 사각형 안에 그어진 선은 중앙값이고 사각형의 위나 아래선은 25% 와 75% 값으로 고정
API 에 따라서는 평균을 표시할 수 있고 수염의 양 끝은 기본적으로는 IQR*1.5 배 한 값을 사분위 수에서 빼거나 더한 값인데 최소나 최대로 바꿀 수도 있고 90분위 수나 95분위 또는 99분위 수로 변경이 가능합니다.
=>도수 분포표
상대 도수: 계급에 해당하는 빈도
누적 상대 도수: 계급 까지 누적된 빈도 - numpy.cumsum을 이용해서 구할 수 있습니다.
연속형 데이터의 구간 분할 - 직접 구현해도 되지만 pandas의 cut 함수를 활용
#히스토그램
ax=(state['Population']).plot.hist(figsize=(3,4))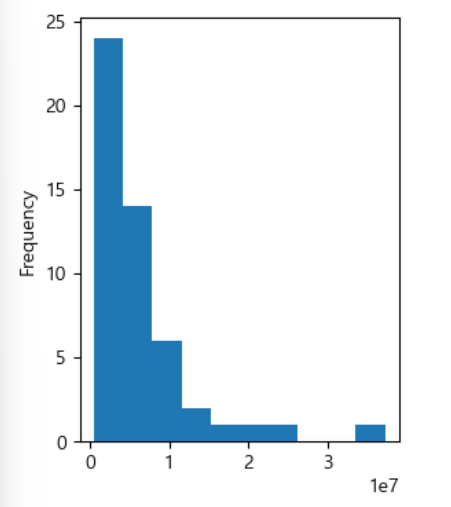
#밀도 추정
ax=(state['Population']).plot.hist(density=True,xlim=[0,12],bins=range(1,12),figsize=(4,4))
state['Murder.Rate'].plot.density(ax=ax)
plt.show()
4.다변량 탐색
1)개요
=>평균이나 분산 같은 추정값들은 한 번에 하나의 변수를 다루는 것인데 이를 일변량 분석이라고 함
=>두개이상의 변수 관계를 파악하는 것을 다변량 분석(multivariate analysis) 라고 하고 2개의 변수간의 관계를 파악하는 것은 이변량 분석(bivariate analysis)라고 합니다.
=>다변량 분석에서 많이 사용하는 시각화
-분할표(Contingency Table):두 가지 이상의 범주형 변수의 빈도수를 기록한 표
-육각형 구간: 두 변수를 육각형 모양의 구간으로 나눈 그림
-등고 도표
-바이올린 도표
2)교차 분석(Cross Table Analyze)
=>범주형 자료를 대상으로 2개 이상의 변수들에 대한 관련성을 알아보기 위해서 결합 분포를 나타내는 교차 분할표를 작성하고 이를 통해서 변수 상호 간의 관련성 여부를 분석하는 방법
=>교차 분석에 사용되는 변수는 값을 10가지 미만으로 갖는 것이 좋습니다.
=>교차 분석을 할 떄는 범주형 데이터가 수치로 만들어져 있는 경우 원래의 의미를 갖도록 변환해서 사용하는 것이 좋습니다
=>descriptive.csv 파일의 데이터를 이용한 교차 분할표 만들기
#gender 필드인데 1이면 남자 2이면 여자
#성별 필드를 추가해서 남자와 여자골 기록
university['성별']='남자'
idx = 0
for val in university['gender']:
if val ==2:
university['성별'][idx]='여지'
idx=idx +1
print(university['성별'].value_counts())
3)공분산(covariance)
=>개요
2종류의 데이터를 가지고 결합 분포의 평균을 중심으로 각 자료들이 어떻게 분포되어 있는지를 보여주는 수치
공분산이 분산과 다른점은 가로 축과 세로 축의 데이터가 다르기 때문에 편차들로 만든 도형이 직사각형이 되고 음의 면적도 만들 수 있음
=>키와 체중의 공분산을 구하는 경우
(첫번째 키- 키의 평균)(첫번쨰 체중 - 체중의 평균) + ( 두번쨰 키 - 키의 평균)(두번째 체중- 체중의 평균)... 이렇게 구해진 값을 데이터 개수로 나누면 됩니다.
=>해석
공분산이 0보다 큰 경우: 변수 한쪽이 큰 값을 갖게 된 경우 다른 한쪽도 커지게 됩니다
공분산이 0보다 작은 경우:변수 한쪽이 큰 값을 갖게 되는 경우 다른 한쪽도 작아지게 됩니다
공분산이 0 인경우: 2개의 변수 사이에는 아무런 연관성이 없을 수 있음
=>numpy의 cov라는 함수가 공분산 값을 구해줍니다
ddof 옵션으로 제약조건의 개수를 설정
#공분산을 구하기 위해서는 평균을 알아야 하고 데이터 개수도 알아야 합니다
N=len(cov_data)
#print(N)
x=cov_data['x']
y=cov_data['y']
mu_x=np.mean(x)
mu_y=np.mean(y)
cov=sum((x-mu_x) * (y-mu_y))/(N-1)
print("공분산:",cov)
#numpy 의 cov 이용해서 구할 수 있는데 각 열의 분산과 공분산을 같이 해줍니다
np.cov(x,y,ddof=1) # 공분산 행렬
#ddof 는 제약 조건의 개수이므로 자유도는 데이터 개수 - 제약조건의 수
#cov 함수는 분산, 공분산 행렬을 리턴합니다
#0,0 과 1,1 은 각 열의 분산입니다
#0,1 과 1,0 은 공분산이어서 2개의 값은 같습니다
4)상관계수( correlation coefficient)
=>공분산은 단위나 자료의 범위에 따라 값의 차이가 크게 발생하기 때문에 이를 가지고 여러 컬럼들 사이의 관련성을 확인하는 것은 어렵습니다
=>2개의 변수 관계를 파악할 때 방향성만 분리해서 보는 것이 유용하기 떄무네 새로운 지표를 생성
공분산을 가지고 연산을 수행해서 -1~ 1사이의 값으로 변경한 것이 상관계수
=>수식
상관계수 = 공분산 /( 각 열의 표준편차를 곱한 값)
=>해석
부호 자체는 공분산과 동일하게 해석
절대값 0.9 이상이면 매우 높은 상관 관계이고, 0.7 이상이면 높은 상관관계이고, 0.4 이상이면 상관관계가 다소 높다라고 하고 그 이외는 상관관계가 약하다거나 없다라고 판정합니다
상관관계나 공분산 만으로 데이터의 관계를 파악하는것은 위험합니다. 실제 분포도 확인해봐야 합니다.
'Study > Data전처리 및 통계' 카테고리의 다른 글
| 확률 분포모형 (1) | 2024.02.23 |
|---|---|
| 기술 통계 (0) | 2024.02.22 |
| Pandas(8)-한글 NLP (0) | 2024.02.20 |
| Pandas(7)-Outlier,Encoder,자연어처리 (0) | 2024.02.19 |
| Pandas(6)-Scaler 및 Normalization (0) | 2024.02.16 |



