1.인공지능
1)지능
=>문제를 해결할 수 있는 능력
=>환자를 보고 병을 진단
2)인공 지능
=>지능 작업을 수행할 수 있는 기계의 능력
=>환자에 대한 정보를 입력하면 컴퓨터가 병을 진단
3)구현 방법
=>지식 공학(전문가 시스템):문제 해결을 위한 알고리즘을 사람이 작성
전문가들의 도움을 받아서 개발자가 알고리즘을 작성해서 컴퓨터에 저장하고 이 알고리즘에 따라 문제를 해결
컴퓨터의 역할은 결과를 만들어내는 것
=>Machine Learning
Data 와 Output 을 주면 컴퓨터가 알고리즘을 만들어 내는 방식
알고리즘을 누가 만드냐에 따라 지능 공학 or 머신러닝인지로 나뉨
4)인공지능과 머신러닝의 관계
인공지능 > 기계학습(머신러닝) > 딥러닝,강화 학습
전문가 시스템 ->머신 러닝 ->딥러닝 ,강화학습
이미지 데이터가 존재하는 경우 머신 러닝은 이미지 데이터 1개를 데이터 1개로 바라보지만, 딥러닝은 이를 작게 쪼개서 그 안에서 알고리즘을 찾을 수 있음
생성형 AI 은 딥러닝 + 강화 학습
2.Machine learning
1)개요
=>데이터를 가지고 학습하도록 컴퓨터를 프로그래밍하는 과학
=>명시적으로 프로그램 되는 것이 아니라 훈련되며 작업과 관련있는 샘플을 제공하면 이 데이터에서 통계적 구조를 찾아 그 작업을 자동화하기 위한 규칙을 만들어 내는 것
=>지금 만들어져 있는 것들은 CI/CD가 잘 되어있질 않음->실시간으로 데이터를 어떻게 넣을지.
운영과정에서 생긴 데이터를 다시 학습하지 않겠다 수집부터 재학습까지 ->MLOps
고객들의 데이터이 새로 들어올 때 바로 서비스가 가능한가?가 Main Point
2)필요 요소
=>입력 데이터 포인트: 최근에는 여러 입력 데이터 포인트로 얻어진 데이터를 한 곳에 모아서 처리하는 부분에 대해서 중점을 둡니다.
데이터 발생지가 여러 곳인 경우 별도로 처리를 하는 것이 어렵기 때문에 한 곳에 잘 정리해서 모으는 것이 중요합니다.
=>기대 출력: 어떤 결과를 원하는 것인지
=>알고리즘의 성능을 측정하는 방법: 평가 지표(도메인에 따라 다름)
=>얼마나 정확하게 추천을 했는가 가 중요
3)사용하는 이유
=>전통적인 방식으로는 너무 복잡하거나 알려진 알고리즘이 없는 문제
음성 인식 같은 경우는 직접 알고리즘을 만들기에는 너무 복잡해서 머신러닝을 이용
=>머신 러닝을 통해서 학습을 할 수 있기 때문
대용량의 데이터를 분석하다 보면 기존에 알고있지 않은 또는 겉으로는 보이지 않은 패턴 발견할 수 있음- 데이터 마이닝
4)역사
1.=>확률적 모델링
-나이브 베이즈
-로지스틱 회귀
2.=>신경망
-등장은 1950년대 했는데 이 때는 컴퓨터의 성능이 좋지 못해서 효과적인 훈련 방법을 찾지 못함
-1989년에 얀 르쿤에 의해서 초창기 합성곱 신경망이 등장하면서 다시 각광을 받음
3.=>커널 방법
-분류에 사용이 되었는데 선형이 아닌 비선형으로 결정 경계를 만들기 시작
4.=>Decision Tree, RandomForest, Gradient Boosting:앙상블의 모형
-컴퓨터의 성능이 좋아지면서 하나의 알고리즘을 부트스트랩을 이용하거나 여러개의 알고리즘을 한꺼번에 학습하는 방법
5.=>다시 신경망:2010년 초반 부터
6.=>생성형 AI
5)분류
=>레이블(정답)의 존재 여부에 따라 분류
-지도 학습: 레이블이 존재(회귀나 분류)
-비지도 학습: 레이블이 존재하지 않음( 주성분 분석. 군집, 연관 분석 등)
-준지도 학습: 레이블을 만드는 작업 - 레이블이 일부분밖에 없어서 (생물학,의학 분야)
-강화 학습: 보상이 주어지는 방식
=>실시간으로 점진적으로 학습을 할 수 있는지 여부
-온라인 학습:점진적 학습이 가능
-배치 학습: 점진적 학습이 안됨
=>사례기반 학습과 모델 기반 학습
모델 기반 학습: 패턴을 발견해서 예측 모델을 만드는 방식
사례 기반 학습: 알고 있는 데이터와 새 데이터를 비교하는게 목적
6)지도 학습(Supervised Learning)
=>레이블이 존재하는 학습
=>입력- 출력 쌍들을 매핑해주는 함수를 학습
=>종류
-출력이 이산적일 때는 분류 문제
-출력이 연속적일 떄는 회귀 문제
-출력이 확률인 경우는 추정(Deep Learning)
=>단점
-사용할 수 있는 데이터에 한계가 있음
-데이터를 생성하는데 비용이 많이 발생
=>종류
-선형 회귀
-로지스틱 회귀
-k 최근접 이웃
-SVM
-결정 트리
-랜덤 포레스트
-신경망
=>로지스틱 회귀를 제외하고는 분류와 회귀 모두에 사용 가능
로지스틱 회귀는 분류만 가능
7)비지도 학습(Unsupervised learning)
=>레이블이 존재하지 않는 학습
=>데이터에 내재된 고유의 특징을 탐색하기 위해서 사용
=>지도 학습에 비해서 학습하기 어려움
=>군집
- k means
-DBSCAN
-계층 군집
-이상치 탐지 와 특이치 탐지
-원 클래스
-아이솔레이션 포레스트
=>시각화와 차원 축소
-PCA(주성분 분석)
-LLE(지역적 선형 임베딩)
-t-SNE
=>연관 규칙 학습
-Apriori
-eclat
8)준지도 학습
=>라벨링이 일부분만 되어 있어서 그 데이터를 이용해서 라벨이 없는 데이터에 라벨을 붙이기 위해서 사용
9) 강화 학습
=>결과가 바로 주어지지 않고 시간이 지나서 주어지는 방식
=>최근에 로봇 같은 분야에 많이 이용
10)애플리케이션 사례
=>Netflix 의 영화 추천 시스템: 고객의 평점 작성 내역과 구매 내역을 이용해서 추천
=>미국 국가 안보국의 SKYNET :파키스탄의 테러리스트 식별해서 사살하기 위한 프로그램
휴대전화 기록을 이용했는데 휴대 전화를 자주 끄거나 USIM을 변경하는 사람을 테러리스트로 식별해서 사살했는데 잘못된 알고리즘으로 무고한 사람이 희생
3.scikit learn
1)개요
=>파이썬 머신러닝 패키지 중 가장 많이 사용되는 라이브러리
=>가장 Python 스러운 API
=>패키지 이름은 sklearn
아나콘다에서는 기본으로 설치 되있음
4.데이터 표현 방식
1)테이블로서의 데이터
=>기본 테이블은 2차원 데이터 그리드 형태
=>행은 데이터 세트의 개별 요소를 나타내고 열은 각 요소와 관련된 수량을 나타냄
=>행을 sample아라고 부르는 경우가 많고 행의 개수를 n_samples 라고 표현
=>열은 Feature 또는 target 이라고 부르는 경우가 많고 열의 개수를 n_features라고 표현
feature:독립적인 데이터
target: feature로 인해서 만들어진 데이터로 label이라고도 합니다.
2)feature
=>보통은 X라는 변수에 저장
=>특징 행렬이라는 표현을 사용하는데, [n_samples,n_features]의 모양을 가진 2차원 행렬이라고 가정을 하며 실제 자료형은 numpy의 ndarray 나 pandas의 DataFrame으로 되어 있는 경우가 많은데 가끔 sklearn의 희소 행렬인 경우도 있음
=>정량적인 데이터이어야 하기 떄문에 대부분의 경우는 실수 이지만 이산적인 데이터나 부울도 가능
3)target
=>대상 행렬이라고 하는데 y로 표시
=>numpy의 1차원 ndarray 나 pandas 의 Series 인 경우가 많음
=>연속적인 수치나 이산 클래스를 가질 수 있음
4)데이터를 가져와서 feature와 target 분리
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
#이 데이터는 sepal_length, sepal_width, petal_length, petal_width 를 가지고
#species 를 분류하기 위한 데이터
#species 는 target 나머지 데이터는 특징 행렬
X_iris = iris.drop('species',axis= 1)
y_iris = iris['species']
print(X_iris.head,y_iris.head)5.Estimator API (머신러닝 모델 API)
1)기본 원칙
=>일관성 : 모든 객체는 일관된 문서를 갖춘 제한된 함수 집합에서 비롯된 공통 인터페이스를 공유
거의 모든 객체는 동일한 작업을 수행하는 메서드를 공통으로 소유
템플릿 메서드 패턴 : 공통으로 사용될 것 같은 메서드를 인터페이스에 등록하고 이를 클래스에서 구현해서 사용
t 검정- t통계량, pvalue
z검정- z 통계량, pvalue
=>검사(inspection)
parameter :함수 나 기능을 수행하기 위해서 필요한 데이터인데 argument 라고 하기도 하고 인수, 인자, 매개변수라고 하기도 합니다.
hyper parameter:개발자가 직접 설정하는 파라미터를 하이퍼 파라미터라고 하고 함수가 내부적으로 사용하는 데이터를 파라미터라고 합니다.
하이퍼 파라미터 튜닝이라는 것은 하이퍼 파라미터 값을 변경을 해서 더 좋은 모델을 만들거나 최적의 파이퍼 파라미터를 찾아가는 작업입니다.
모든 hyperparamter를 public 속성으로 노출해서 확인이 가능하도록 함
=>제한된 객체 계층 구조
알고리즘만 Python클래스에 의해 표현되고 데이터 세트는 표준 포맷(numpy의 ndarray,pandas 의 DataFrame, scipy의 희소행렬)으로 표현되며 매개변수 이름은 문자열
=>구성: 대부분의 머신 러닝 작업은 기본 알고리즘의 시퀀스로 나타낼 수 있음
=>합리적인 기본값 : 대다수의 하이퍼파라미터는 라이브러리가 적절한 기본값을 가지도록 정의
2)사용방법
=>적절한 모델 클래스를 import
=>모델 클래스를 인스턴스 화 할 떄 적절한 하이퍼 파라미터를 설정
=>데이터를 특징 배열과 타겟 배열로 생성
=>모델 클래스의 인스턴스의 fit 메서드를 호출해서 모델을 데이터에 적합하도록 훈련
=>모델을 새 데이터에 적용
- 지도 학습의 경우: predict 함수에 새로운 데이터를 사용해서 에측
-비지도 학습의 경우: transform 이나 predict 을 이용해서 데이터의 속성을 변환하거나 예측
3)선형 회귀 수행: sklearn.linear_model.LinearRegression
\#샘플 데이터 생성
import numpy as np
rng = np.random.RandomState(42)
#데이터 50개 생성
x= 10 * rng.rand(50)
#데이터를 이용해서 타겟 데이터 생성 - rng.randn(50)은 잡음
y= 2*x -1 + rng.randn(50)
print(x.shape) # 1차원 배열 - 특성 배령른 2차원 배열, DataFrame, 희소 행렬
X=x.reshape(x.shape[0],-1) #x[:np.newaxis]로도 가능
print(X.shape) #X는 특성 배열이 된 것
#추정기 인스턴스 생성
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept = True)
#기존데이터 훈련
model.fit(X,y)
#훈련결과 확인 - 스스로 만든 파라미터나 결과에는 _가 붙습니다.
#하이퍼파라미터에는 _ 가 붙지 않습니다.
print("회귀 게수:",model.coef_)
print("절편:",model.intercept_) # _ 가 들어간건 모델이 계산한것
#회귀는 지도 학습
xfit = np.linspace(-1, 11)
Xfit = xfit[ : , np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x,y)
plt.plot(xfit,yfit)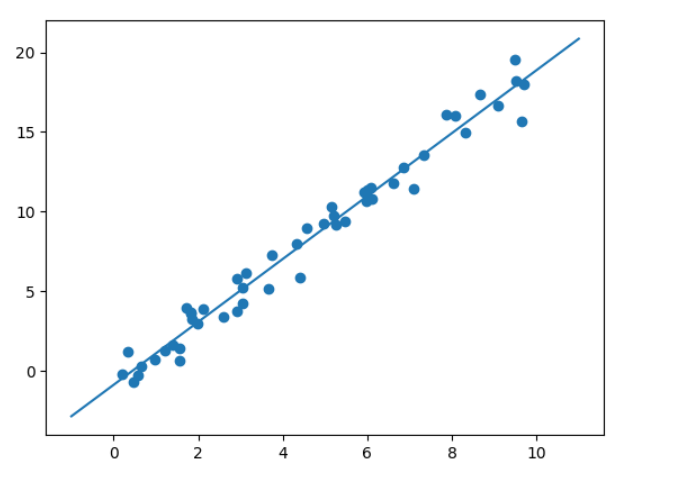
4)붓꽃 데이터를 이용한 훈련 데이터와 테스트를 분리해서 훈련한 후 평가 지표를 이용한 성능 평가
=>앞의 방식은 모든 데이터를 가지고 훈련을 해서 모델을 만든 후 새로운 데이터를 가지고 예측
=>위의 방식은 여러가지 모델을 이용해서 만든 모델을 평가할 수 없음
일반적으로 머신러닝에서는 기존 데이터를 분할해서 훈련에 사용하고 나머지 데이터를 이용해서 모델을 평가
여러 머신러닝 추정기를 적용한 후 최적의 성능을 가진 모델을 선택하는 것이 일반적입니다.
6.Machine learning 절차
1)순서
=>작업 환경 설정: 파이썬 설치, 가상 환경 생성, 필요한 패키지 설치
서비스를 만들고자 하는 경우는 가상 환경 생성 작업이 필수
=>문제 정의
=>데이터 수집
=>데이터 탐색
=>데이터 전처리
=>모델을 선택하고 훈련
=>평가를 하고 전처리 부터 다른 모델을 선택해서 다시 수행하거나 하이퍼파라미터를 조정하면서 다시 수행
=>최적의 모델을 선택하고 솔루션을 제시
=>시스템을 런칭하고 모니터링 하면서 유지보수
2)실행
=>환경 설정
=>데이터 수집 - housing.csv
-california 주택 데이셋
-블록 별로 여러 컬럼들을 소유하고 있음
=>문제 정의 : 중간 주택 가격을 예측
-주택 가격이 이미 존재하므로 지도 학습
-주택 가격은 연속형 데이터이므로 회귀 분석
=>데이터 불러와서 탐색
import pandas as pd
#데이터 가져오기
housing = pd.read_csv("C:\\Users\\User\\Desktop\\데이터\\python_machine_learning-main\\python_machine_learning-main\\data\\housing.csv")
print(housing.head())
=>데이터 분리:훈련 데이터와 테스트 데이터 또는 검증 데이터로 분리를 하는 것이 일반적
데이터 전체를 파악하기 전에 분리하는 것이 좋습니다
전체 데이터를 가지고 데이터 탐색을 수행하게 되면 과대 적합 될 가능성이 발생
사람의 뇌가 패턴을 감지해버릴 수 있기 때문 ->data snooping이라고 합니다
데이터를 나눌 때 보통 7:3 이나 8:2 을 많이 이용하지만 데이터 개수에 따라 다른 선택을 할 수 있습니다.
일반적으로 데이터가 ㅁ낳으면 훈련 데이터의 비율을 낮추고, 데이터의 개수가 적으면 훈련 데이터의 비율을 높임
데이터가 아주 많으면 검증용 데이터를 별도로 분할해도 됩니다.
데이터를 순차적으로 분할해야 하는 경우도 있는데 이런 경우는 시계열 데이터인 경우
훈련을 여러 번 반복해서 수행하는 경우 알고리즘의 비교 측면이나 전체 데이텅를 학습하게 되는 상황을 방지하기 위해서 일정한 데이터를 랜덤하게 추출하는 경우가 존재
분류 문제에서는 타겟의 비율이 다르다면 층화 추출도 고려
=> sklearn의 model_selection.train_test_split API을 이용한 데이터 분리
train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
arrays는 데이터 배열, test_size는 테스트 비율,train_size는 데이터가 아주 많으면 훈련하는데 시간이 너무 많이 걸릴 수 있어서 설정하기도함, random_state는 시드 번호로 설정하는 것을 권장. shuffle은 데이터 섞을지 여부로 random_state를 설정하면 무의미 , stratify는 층화 추출을 하고자 할 떄 데이터의 비율
X=housing.drop('median_house_value',axis=1)
y=housing['median_house_value']
X_train,X_test,y_train,y_test = sklearn.model_selection.train_test_split(X,y,test_size=0.2 ,random_state=42)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
=>층화 추출: 계층적 샘플링 - 데이터를 일정한 비율로 샘플링
-회귀나 분류를 할 떄 타겟의 데이터 분포가 일정하지 않은 경우 왜곡된 결과를 만들 수 있습니다.
-분류의 경우 1과 0 의 비율을 10 대 1 정도 되는 상황에서 훈련데이터에 0으로 분류되는 데이터가 하나도 없다면 이 경우 -모델은 테스트 데이터에 결과가 좋지 않을 것입니다.
-0으로 분류되는 모든 데이터가 훈련 데이터에 포함되어 버리면 잘못하면 테스트 데이터에 완전하게 맞는 결과가 나와버릴 수 있습니다.
회귀의 경우 타겟이 연속형 이라면 범주형으로 변환을 해서 수행해야 합니다.
-이 때 사용할 수 있는 함수는 pandas의 cut 이라는 함수입니다.
데이터 와 구간의 리스트 그리고 레이블의 리스트를 대입하면 됩니다.
-API 함수는 StratifiedShuffleSplit 입니다.
-이 함수의 리턴되는 데이터는 데이터가 아니고, 데이터의 index입니다.
결과를 가지고 다시 데이터를 추출해야 합니다.
=>median_income의 비율을 이용한 층화 추출
# 연속형 데이터를 범주형으로 변환
#pd.cut(데이터, bins =[경계값 나열] ,labels =[ 레이블 나열 ])
housing['income_cat'] = pd.cut(housing['median_income'],
bins=[0, 1.5 ,3.0 ,4.5, 6, np.inf],
labels=[1,2,3,4,5])
print(housing['income_cat'].value_counts())
print(housing['income_cat'].value_counts()/20640) #비율
=>StratifiedShuffleSplit API 을 이용한 층화 추출
from sklearn.model_selection import StratifiedShuffleSplit
#계층적 층화 추출을 위한 객체를 생성
#n_splits 은 조각의 개수입니다.
#몇 개의 조각을 만들 것인지를 설정하는 것인데 k-fold validation 수행할때 내부에서 사용
split = StratifiedShuffleSplit(n_splits =1 ,test_size= 0.2, random_state=42)
#인덱스를 리턴해주므로 인덱스를 이용해서 행 단위 추출
result = split.split(housing , housing['income_cat'])
for train_index,test_index in result:
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
#비율확인
strat_train_set['income_cat'].value_counts() / len(strat_train_set)
=>데이터 탐색을 완료하기 전에 데이터를 분리하는 것을 권장
=>데이터 탐색: 상관 계수 출력 - 데이터의 독립성을 살펴볼 때는 상관 계수만 보면 안됩니다.
여러 개의 feature 가 다른 feature 를 설명 할 수도 있기 떄문
=>corr함수를 이용
#상관계수 출력 - 예전 API 에서는 숫자 이외의 컬럼이 있으면 제거하고 계산
#housing.info()
corr_matrix =housing.drop("ocean_proximity",axis=1).corr()
print(corr_matrix)
=>scatter_matrix 함수를 이용
from pandas.plotting import scatter_matrix
scatter_matrix(housing.drop("ocean_proximity",axis=1),figsize=(12,8))
plt.show()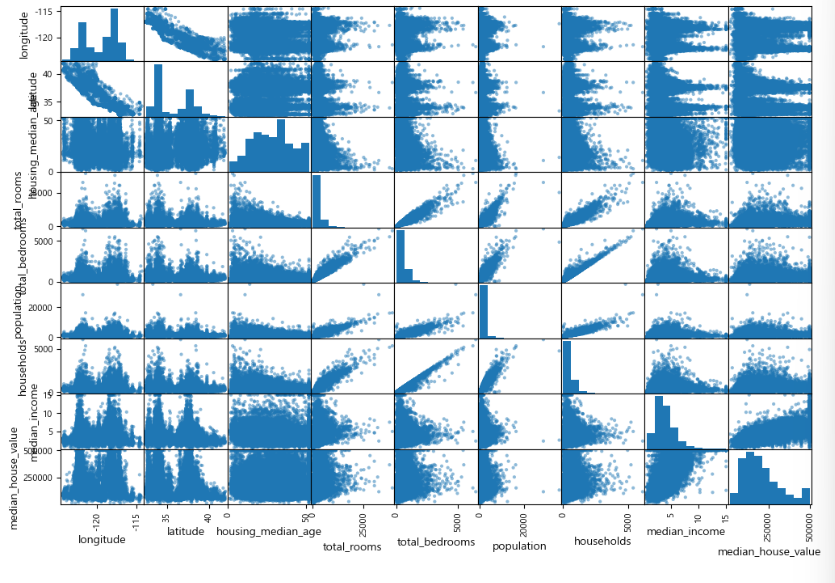
=>특성 조합을 이용한 탐색
-특성 단위로만 탐색을 하는 것이 아니라 여러 특성을 조합해서 새로운 특성을 만들고 그 특성과 다른 특성과의 관계를 확인해보는 것도 중요합니다.
-방의 개수보다 방의 개수 대비 침실의 개수 와 같은 특성을 만들어서 확인해 볼 수 있습니다.
housing['bedrooms_per_room'] = housing ['total_bedrooms']/housing['total_rooms']
corr_matrix = housing.drop('ocean_proximity',axis =1 ).corr()
print(corr_matrix['median_house_value'].sort_values(ascending=False))-타겟에 대한 상관 계수가 침실이나 방의 개수보다 침실/방의 개수가 더 높게 나옴
=>feature 와 target을 분리
housing_feature = strat_train_set.drop('median_house_value',axis =1)
housing_labels = strat_train_set['median_house_value'].copy()
=> 누락된 데이터 처리: 누락된 행을 제거할지. 열을 제거 . 누락값 대체
#결측치 확인
sample_incomplete_rows = housing_features[housing_features.isnull().any(axis = 1)]
print(sample_incomplete_rows)#누락된 행 제거
housing_features.dropna(subset = ['total_bedrooms']).info()#열을 제거
sample_incomplete_rows.drop('total_bedrooms',axis =1)#누락 값 대체 - SimpleImputer 클래스를 이용
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='median')
#숫자로 된 컬럼만 추출해서 NaN 값을 중간값으로 대체
housing_num = housing_features.select_dtypes(include = [np.number])
#housing_num.info()
imputer.fit(housing_num)
X = imputer.transform(housing_num)
#print(type(X)) ->ndarray로 변경되었음 -> 다시 DataFrame으로 변경
housing_tr = pd.DataFrame(X,columns = housing_num.columns , index = list(housing_features.index.values))
print(housing_tr.head())=>범주형 데이터 처리 - 머신 러닝은 숫자만 다룹니다.
-범주형 이나 문자열 데이터가 있다면 숫자로 변환해야 합니다.
-범주형의 경우는 일련번호 형태로 변경을 하거나 원 핫 인코딩을 해야 합니다.
-일련번호 형태로 만들 때는 pandasd 의 Series 의 factorize()을 이용할 수 있고 sklearn.preprocessing.OrdinalEncoder 클래스를 이용해도 됩니다.
#범주형 데이터 추출
housing_cat = housing_features['ocean_proximity']
#일련번호로 만들기
housing_cat_encoded,housing_categories= housing_cat.factorize()
print(housing_cat_encoded[:10])
print(housing_categories)#sklearn의 변환기들은 2차원 배열을 요구합니더
from sklearn.preprocessing import OrdinalEncoder
oridinalEncoder = OrdinalEncoder()
result =oridinalEncoder.fit_transform(housing_features[['ocean_proximity']])
print(result[:10])ValueError: Expected 2D array, got 1D array instead:
array=['INLAND' 'NEAR OCEAN' 'INLAND' ... '<1H OCEAN' '<1H OCEAN' 'INLAND'].
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.=> sklearn의 변환기들은 2차원 배열을 요구함. 위의 오류가 나게 된다면 []을 하나 더 붙여서 list 형으로 변경해야합니다.
# 원 핫 인코딩 - 범주형의 개수 만큼 열을 만들어서 해당하는 열에만 1을 표시
from sklearn.preprocessing import OneHotEncoder
oneHotEncoder = OneHotEncoder()
#기본적으로 희소 행렬 (sparse matrix)
result =oneHotEncoder.fit_transform(housing_features[['ocean_proximity']])
print(result[:10])
#밀집 행렬로 변환
print(result.toarray()[:10])=>특성 스케일링
-입력 숫자 특성들의 스케일이 많이 다르면 정확한 예측을 하지 못하는 경우가 발생
-입력 숫자 특성들만 스케일링을 수행하는데 타겟의 경우는 범위가 너무 큰 경우 로그 스케일링을 수행하는 경우가 있지만 대부분은 수행하지 않음
-훈련 데이터와 테스트 데이터로 분할된 경우 훈련 데이터에만 fit 을 수행하고 훈련 데이터와 테스트에 transform을 수행
-min-max scaler 와 standard scaler 두가지를 많이 이용
정규화 - MinMaxScaler (데이터- 최솟값)/(최댓값- 최솟값) 이렇게 계산
표준화 - StandardScaler
먼저 평균을 뺀 후( 평균이 0) 표준편차로 나누어서 분포의 분산이 1이 되도록 함
범위의 상한과 하한이 없어서 어느정도의 값이 만들어지질 지 예측하기가 어려움
딥러닝에서는 0~ 1의 값만을 요구하는 경우가 있어서 이를 사용할 수가 없음
머신러닝에서는 이상치의 영향을 덜 받음 ->Robust 함
대부분의 경우 이상치에 따라 정규화를 할지 표준화를 할지 정함.
=>전처리 작업을 위한 Pipeline(연속해서 작업을 수행)
- 결측치 대체를 하고 스케일링을 수행한다고 했을 때 따로따로 작업을 해도 되지만 이를 묶어서 한번에 수행하도록 할 수 있습니다.
이렇게 여러 개의 작업을 하나로 묶어서 수행하는 것을 pipeline이라고 합니다.
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
#수행하고자하는 작업을 이름과 추정기로 튜플을 묶어서 list로 설정해주면 됩니다/
num_pipeline =Pipeline([
('imputer',SimpleImputer(strategy='median')),
('std_scaler',StandardScaler())
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
print(housing_num_tr)=>ColumnTransformer
-sklearn 0.2 버전에서 추가된 변환기로 여러 특성에 다른 변환 처리를 할 수 있도록 해주는 클래스
-만드는 방법은 Pipeline과 유사한데 튜플을 만들 떄 (변환기 이름, 변환기, 컬럼이름 리스트) 형태로 대입을 해야합니다.
from sklearn.compose import ColumnTransformer
#숫자 컬럼 이름 리스트
num_attribs = list(housing_num)
cat_attribs = ['ocean_proximity']
#print(num_attribs)
#열별로 다른 변환기를 적용하기 위한 인스턴스 생성
full_pipeline = ColumnTransformer([
("num",num_pipeline,num_attribs),
("cat",OneHotEncoder(),cat_attribs)
])
#변환기 적용
housing_prepared = full_pipeline.fit_transform(housing_features)
print(housing_prepared)
print(housing_prepared.shape)
print(housing_labels.shape) #윗 줄과 column 수 가 동일해야함이걸 활용하면 차후에 작업이 굉장히 편리 -> 잘못되면 수정해야하는데, 처음부터 다시 똑같은 걸 하는 것보단 훨씬 효율적
초보자 와 경력자의 차이 => 초보자는 컴파일되면 끝. 경력자는 튜닝을 하기 위해서 한번 더 봄.
제대로 만들어도 다시 한번 코드 리뷰하면서 고치는게 습관이 되야 함
=>모델 적용 및 테스트
#선형 회귀 모델을 이용
from sklearn.linear_model import LinearRegression
#예측 모델 인스턴스 생성
lin_reg= LinearRegression()
#훈련
lin_reg.fit(housing_prepared, housing_labels)
#테스트
some_data = housing_features.iloc[:5]
some_labels =housing_labels.iloc[:5]
#sample feature 전처리
some_data_prepared = full_pipeline.transform(some_data)
print("예측한 값:",lin_reg.predict(some_data_prepared))
print("실제 값:",list(some_labels))=>평가 지표
-모델을 생성하고 나면 이 모델을 다른 모델과 비교하기 위해서는 평가지표가 있어야 합니다.
-회귀의 평가지표로 사용되는 것으로는 RMSE 와 RMAE 등이 있음
RMSE 는 예측한 값과 실제 값의 차이(residual - 잔차)를 제곱해서 더한 후 제곱근을 해서 사용하고 RMAE는 잔차에 절대값을 절대값을 적용한 후 합계를 구한 것. 값이 적은 쪽이 우수한 모델
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
#모델을 만들 떄 사용한 데이터를 가지고 예측
housing_predictions = lin_reg.predict(housing_prepared)
#잔차 제곱합
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
#잔차 절대값 합
lin_mae = mean_absolute_error(housing_labels, housing_predictions)
print("잔차 제곱합:",lin_mse)
print("잔차 제곱합의 제곱근:",lin_rmse)
print("잔차 절대값합:",lin_mae)
위 코드는 훈련에 사용한 데이터를 가지고 테스트를 했는데 훈련에 사용한 데이터에도 잘 맞지 않으면 과소적합(underfit)
훈련데이터에는 잘 맞지만 테스트 데이터 또는 새로운 데이터에 잘 맞지 않으면 과대 적합(overfit)
과소 적합이 발생하면 데이터를 더 수집하거나 다른 모델을 사용하거나 hyperparameter 를 조정해야 합니다.
=>새로운 모델을 적용 - DecisionTree
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(random_state=42)
tree_reg.fit(housing_prepared , housing_labels)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
print(tree_rmse)=>K-fold cross- validation(K겹 교차 검증)
-트리 모델은 일반적인 형태로 검증을 하지 않고 데이터를 K개 그룹으로 나눈 후 (K-1)개의 데이터 그룹을 사용해서 모델을 생성하고 나머지 그룹을 이용해서 테스트를 수행하는데 이런 작업을 K번 반복해서 그 떄의 평균을 리턴합니다.
-sklearn에서는 점수가 높은 것이 좋다고 생각하기 떄문에 평가지표를 설정할 때 - 를 곱해서 사용합니다.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg , housing_prepared , housing_labels ,
scoring ='neg_mean_squared_error',cv =10)
tree_rmse_scores = np.sqrt(-scores)
print(tree_rmse_scores)
=>그리드 탐색
-파라미터라고 할 떄는 함수 또는 메서드가 수행할 떄 결정하는 데이터이고 하이퍼 파라미터는 사용자가 직접 설정하는 데이터
대부분의 하이퍼 파라미터는 가장 알맞는 기본값을 소유하고 있음
-가장 좋은 하이퍼파라미터를 찾는 것
-GridSearchCV을 이용하면 여러종류의 하이퍼파라미터를 설정해서 훈련한 후 가장 좋은 하이퍼 파라미터를 추천해줍니다.
-파라미터를 설정할 때는 list 의 dict 로 설정을 하게 되는데 dict 에 하이퍼 파라미터 이름 과 값의 list 를 설정을 하는데 하나의 dict 내에 있는 파라미터는 모든 조합을 가지고 수행하고 각 dict 는 별개로 수행
-시간이 오래 걸릴 가능성이 높음
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor(random_state = 42)
#파라미터 조합을 생성
param_grid =[{'n_estimators':[3,10,30],'max_features':[2,4,6,8]},
{'bootstrap':[False],'n_estimators':[3,10],'max_features':[2,3,4]}]
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(forest_reg,param_grid,cv=5,
scoring='neg_mean_squared_error',
return_train_score= True , n_jobs = -1)
grid_search.fit(housing_prepared,housing_labels)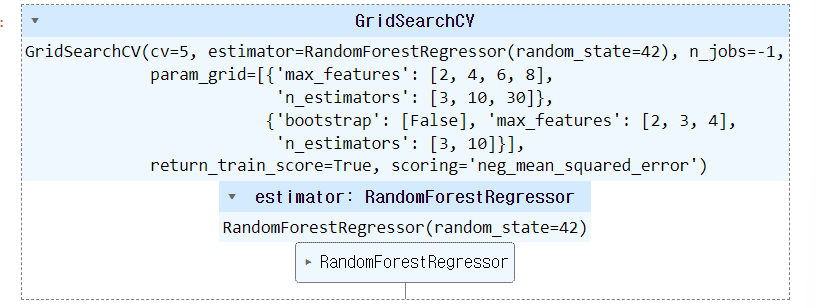
print(grid_search.best_params_)반드시 _(언더바)를 붙어야됨. 내가 만든건 안붙이지만 알고리즘 상으로 만들어졌을 경우 _가 붙어야 출력이 됨
#평가 점수 확인
cvres =grid_search.cv_results_
for mean_score, params in zip(cvres['mean_test_score'],cvres['params']):
print(np.sqrt(-mean_score),params) #negative mean임으로 -을 붙어야함=>랜덤 서치
-그리드 서치는 하이퍼파라미터 값을 직접 입력해서 선택하도록 하는데 이 방식은 파라미터가 몇 개 안될 때는 유용하지만 많을 때는 사용하기가 어려움 =>해서 나온게 랜덤 서치
-RandomizedSearchCV은 파라미터의 하한과 상한을 설정해서 몇 번 수행할지를 설정하면 랜덤하게 숫자를 추출해서 가장 좋은 조합을 찾아줍니다.
=>앙상블
-여러 개의 모델을 사용하는 방식
-Decision Tree는 하나의 트리를 이용하지만 RandomForest 은 여러 개의 Decision Tree 를 가지고 예측
=>테스트를 할 때는 모델을 만들 떄 사용한 데이터가 아니라 Test Data를 가지고 테스트를 수행하기도 합니다
훈련 데이터에는 잘 맞지만 테스트 데이터에 잘 맞지 않는 상황이 발생할 수 있는데 이 경우을 Overfitting(과대적합)이라고 합니다.
훈련 데이터에도 잘 맞지 않은 UnderFitting(과소적합)이라고 합니다.
'Study > Machine learning,NLP' 카테고리의 다른 글
| 머신러닝(5) - Regression(2) (0) | 2024.03.05 |
|---|---|
| 머신러닝(4)-Regression(1) (0) | 2024.03.04 |
| 머신러닝(3)-Classification(2) (0) | 2024.02.29 |
| 머신러닝(2)-Classification(1) (0) | 2024.02.28 |
| 이미지 데이터 다루기 (0) | 2024.02.20 |



