1.Keras
=>모든 종류의 신경망을 손쉽게 만들고 훈련, 평가, 실행할 수 있는 고수준 딥러닝 API
=>API 문서는 https://keras.io
Keras: Deep Learning for humans
A superpower for developers. The purpose of Keras is to give an unfair advantage to any developer looking to ship Machine Learning-powered apps. Keras focuses on debugging speed, code elegance & conciseness, maintainability, and deployability. When you cho
keras.io
=>거의 모든 딥러닝 라이브러리에서 사용 가능
2.Keras 의 Dense
=>완전 연결층을 만들기 위한 클래스
이전층의 모든 연산을 받아들이는 층을 완전 연결층이라고 합니다
1)생성할 때 파라미터
=>unit :뉴런의 개수
=>activation:활성화 함수로 기본값은 None 이고 sigmoid, softmax(다중 분류 문제에서 사용),tanh(하이퍼볼릭 탄젠트 함수), relu 등을 설정할 수 있습니다.
=>input_shape 은 입력층(첫번째 층)의 경우 입력되는 데이터의 크기를 지정해야 하는 매개변수
2)Tensorflow 의 Keras 모델 생성방법
=>Sequential API
=>Functional API
=>SubClassing
3)Sequential API 활용
=>개요
-층을 이어 붙이듯 시퀀스에 맞게 일렬로 연결하는 방식
-입력 레이러부터 출력 레이어까지 순서를 갖는 형태
-입력 레이어가 첫번째 레이어가 되는데 입력 데이터가 이 레이어에 투입되고 순서대로 각 층을 하나씩 통과하면서 딥러닝 연산을 수행
-이해하기가 가장 쉬운 방법이지만 2개 이상의 다중 입력이나 다중 출력을 갖는 복잡한 구조를 만들 지 못함
=>모델 구조
-list 이용
model = tf.keras.Sequential([
tf.keras.layers.Dense(10),
tf.keras.layers.Dense(5),
tf.keras.layers.Dense(1)
])
-add 함수를 이용
model tf.keras.Sequential()
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Dense(5))
model.add(tf.keras.layers.Dense(1))
=>입력 데이터 형태 지정
- 첫번째 층의 input_shape 에 튜플이나 리스트 형태로 설정
shape가 150,4 인 경우 (150,4),[150,4] 도 가능하고 (4,)[4] 도 가능
첫번째 숫자가 데이터의 개수이고,나머지 부분이 데이터의 shape 가 되므로 데이터의 개수를 생략하더라도
shape가 설정되면 데이터의 개수는 유추할 수 있기 때문
#단순 선형 회귀
#Layer는 1개면 가능
#입력 데이터는 피처가 1개
#출력도 하나의 숫자
model = tf.keras.Sequential([
tf.keras.layers.Dense(1,input_shape=(1,))
])
=>Sequential 모델은 모델의 구조를 확인하는 것이 가능
model.summary()
=>모델 compile
model.compile(optimizer='sgd', loss='mean_squared_error',
metrics=['mean_squared_error', 'mean_absolute_error’])
model.compile(optimizer='sgd', loss='mse', metrics=['mse', 'mae’])
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.005),
loss=tf.keras.losses.MeanAbsoluteError(),
metrics=[tf.keras.metrics.MeanAbsoluteError(),
tf.keras.metrics.MeanSquaredError()
])
=>훈련 - fit
-훈련을 하면 가중치를 업데이트
-훈련 데이트 세트의 입력 (X)와 정답에 해당하는 출력(y) 그리고 반복횟수에 해당하는 epoch를 설정하는데 기본적으로 훈련을 할 때마다 손실과 평가 지표를 출력하는데 verbose =0을 추가하면 중간 과정이 생략
-validation_data 에 검증 데이터를 설정하면 검증 데이터에 대한 손실과 평가 지표도 같이 반환
-fit 함수가 리턴하는 객체는 epoch 별 손실과 평가지표를 dict로 저장하고 있습니다.
=>검증 및 예측
-검증은 evaluate 메서드에 훈련 데이터를 입력하면 됩니다.
-예측은 predict 예측을 통해 성능 검증을 합니다
4)Classification(분류)
=>데이터가 어느 범주(Category)에 해당하는지 판단하는 문제
=>회귀가 알고리즘의 퍼포먼스를 확인하기 위해서 잔차 제곱의 합(SSE) 나 잔차 제곱의 평균(MSE)등을 사용하고 이 값들은 일반적으로 실수
=>분류에서는 같은 목적으로 예측이 정답을 얼마나 맞혔는지에 대한 정확도를 측정
정확도는 보통 퍼센트로 나타내고 이 수치는 직관적이기 때문에 머신러닝 알고리즘의 벤치마크 역할을 분류를 가지고 판단
=>ImageNet이라는 데이터베이스를 이용해서 이미지의 범주를 분류하는 대회가 있는데 2012년 CNN이 등장하면서 2017년에 거의 100% 달성
=>이항 분류
- 정답의 범주가 2개인 분류 문제
=>레드와 화이트 와인 분류: 이항 분류
-데이터
red:http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv
white: http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv
-구분자:;(세미콜론)
-feature:
fixed acidity
volatile acidity
citric acid
residual sugar
chlorides
free sulfur dioxide
total sulfur dioxide
density
pH
sulphates
alchol
quality
=>데이터 가져오기
#데이터 가져오기
import pandas as pd
red = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv',sep=';')
white = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv',sep=';')
red.info()
white.info()=>데이터 전처리 및 가져오기
#타겟 생성
red['type']=0
white['type']=1
wine = pd.concat([red,white])
wine.info()
#기술통계량
wine.describe()#데이터를 랜덤하게 shuffling
wine_shuffle = wine_norm.sample(frac=1)
print(wine_shuffle.head())
wine_np = wine_shuffle.to_numpy()
print(wine_np[:5])#훈련데이터와 테스트 데이터 만들기
#80%에 해당하는 인덱스 구하기
train_idx = int(len(wine_np)*0.8)
#80%을 기준으로 훈련데이터와 테스트 데이터 분리
train_X, train_Y = wine_np [:train_idx,:-1],wine_np[:train_idx,-1]
test_X, test_Y = wine_np [train_idx:,:-1],wine_np[train_idx:,-1]#타겟을 원핫인코딩을 수행
train_Y = tf.keras.utils.to_categorical(train_Y, num_classes=2)
test_Y = tf.keras.utils.to_categorical(test_Y, num_classes=2)
print(train_Y[0])
print(test_Y[0])
일반 머신러닝 알고리즘에서는 타겟을 원핫인코딩하지 않음 하지만 딥러닝에서는 원핫인코딩을 진행함
=>분류 모델 생성
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=48, activation='relu', input_shape=(12,)),
tf.keras.layers.Dense(units=24, activation='relu'),
tf.keras.layers.Dense(units=12, activation='relu'),
tf.keras.layers.Dense(units=2, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.07), loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()unit의 개수를 점차 줄여나가면서 진행 . 마지막 층의 unit개수는 출력하는 데이터의 개수(회귀는 1 분류는 2) 첫번째에만 input_shape이 들어가면됨

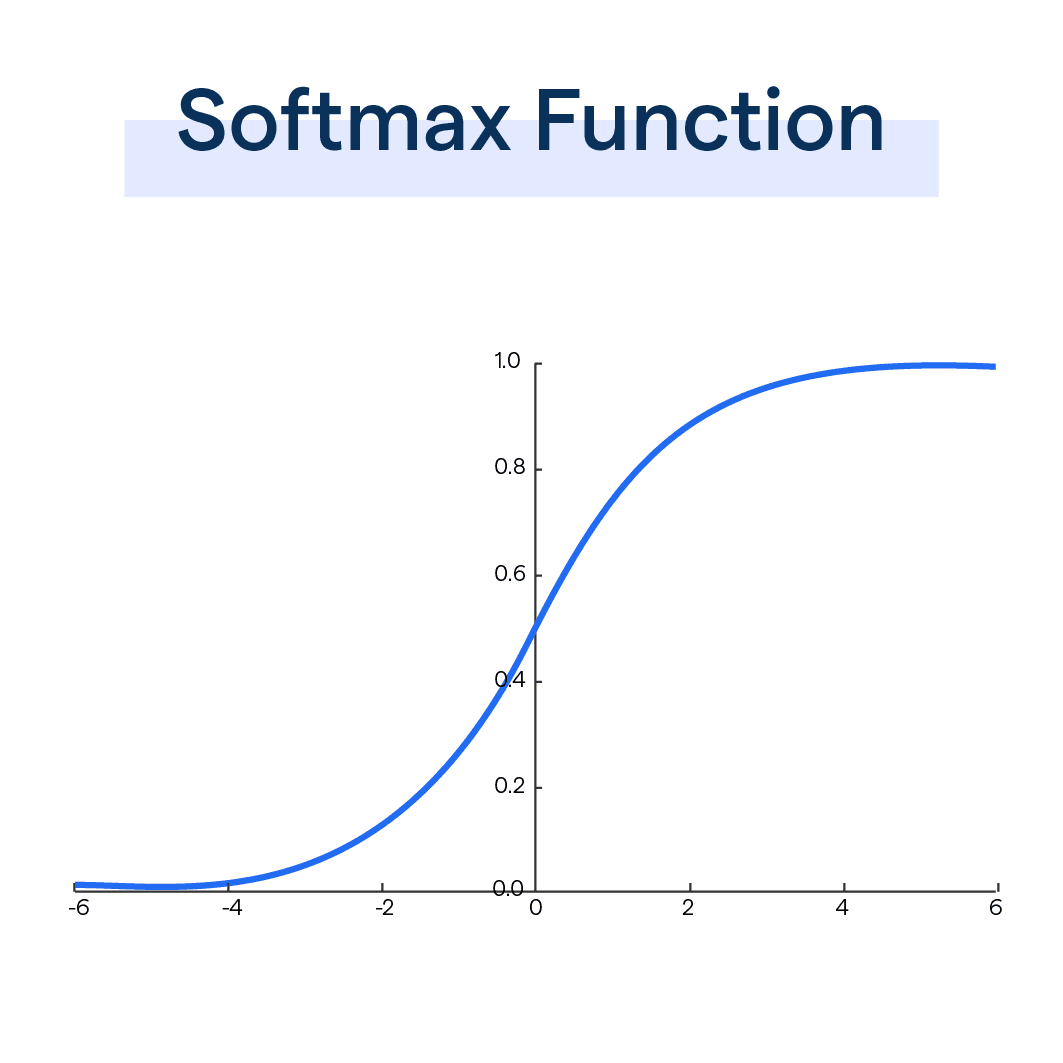
※softmax 함수는 자연로그의 밑인 e의 지수를 사용해 계산한 뒤 모두 더한 값으로 나누는데 이렇게 나온 결과는 총합이 1.0인 확률값
softmax 는 분류나 RNN에서 다음 토큰 예측 등 결과값으로 확률이 필요한 분야에서 사용
여기 예시에서는 [0.97,0,03] 으로 나오는데 앞이 red와인 일 확률
시그모이드 처럼 곡선 함수
※Cross-Entropy는 정보이론에서 정보량을 나타내기 위해 사용하는 단위.
확률의 역수에 로그를 취한 값
-log확률
이걸 사용하는 이유는 확률이 높은 사건일수록 정보량이 적다고 판단하기 때문입니다.
엔트로피의 기댓값은 엔트로피에 확률을 곱해준 값
엔트로피가 높다는 뜻은 높은 불확실성을 나타냅니다.
분류 문제에서는 불확실성의 정도는 낮추는 방향으로 학습을 진행
분류 문제에서는 어느 한쪽의 확률이 높은 쪽으로 학습을 진행
history = model.fit(train_X, train_Y, epochs=25, batch_size=32, validation_split=0.25)
#모델 평가
model.evaluate(test_X,test_Y)
이진 분류를 할 때 타겟은 2개 속성으로 만들어져야하고 출력층에서unit 의 개수는 2개이고 손싷람수로 corss_entropy를 사용하고 출력 층의 activation funcation는 softmax를 사용
다중 클래스 분류는 출력 층에서 unit 개수만 변경하면 됩니다
=>다중 클래스 분류
#타겟으로 사용할만한 특성 확인
print(wine['quality'].describe())
#샘플의 타겟 비율이 너무커서 샘플링 비율을 조정해야합니다
print(wine['quality'].value_counts())
#6을 기준으로 6보다 작으면 0 6이면 1 7이상이면 2로 구간화
wine.loc[wine['quality'] <= 5, 'new_quality'] = 0
wine.loc[wine['quality'] == 6, 'new_quality'] = 1
wine.loc[wine['quality'] >= 7, 'new_quality'] = 2
print(wine['new_quality'].describe())
print(wine['new_quality'].value_counts())
del wine['quality']
wine_backup = wine.copy()
wine_norm = (wine - wine.min()) / (wine.max() - wine.min())
wine_norm['new_quality'] = wine_backup['new_quality']
wine_shuffle = wine_norm.sample(frac=1)
wine_np = wine_shuffle.to_numpy()
train_idx = int(len(wine_np) * 0.8)
train_X, train_Y = wine_np[:train_idx, :-1], wine_np[:train_idx, -1]
test_X, test_Y = wine_np[train_idx:, :-1], wine_np[train_idx:, -1]
train_Y = tf.keras.utils.to_categorical(train_Y, num_classes=3)
test_Y = tf.keras.utils.to_categorical(test_Y, num_classes=3)정규화 -딥러닝을 할 때는 이 작업을 하지 않아도 되는데 대신에 이런 경우 epoch를 늘려주던지 아니면 layer를 더 많이 쌓아서 해결
셔플- 데이터를 읽을 때 순서대로 데이터를 읽었기 때문에 셔플을 하지 않으면 샘플링할 때 어느 한 쪽 데이터가 과표집 될 수 있습니다. 여론조사는 컨벤션효과라고 하는 것 때문에 과표집 문제가 많이 발생합니다.
딥러닝을 이용해서 분류할 때는 타겟을 원핫인코딩 하는 경우가 많습니다.
분류를 할때는 activation 을 softmax 로 설정하는 경우가 많은데
softmax는 각 클래스에 대한 기대값을 확률의 형태로 나타냅니다
출력이 여러개의 값으로 구성이 됩니다.
가장 기대값이 높은 인덱스에 1을 설정하고 나머지는 0으로 설정
=>모델 생성
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=48, activation='relu', input_shape=(12,)),
tf.keras.layers.Dense(units=24, activation='relu'),
tf.keras.layers.Dense(units=12, activation='relu'),
tf.keras.layers.Dense(units=3, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.003), loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(train_X, train_Y, epochs=25, batch_size=32, validation_split=0.25)
=>모델 성능 시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], 'g-', label='accuracy')
plt.plot(history.history['val_accuracy'], 'k--', label='val_accuracy')
plt.xlabel('Epoch')
plt.ylim(0.5, 0.7)
plt.legend()
plt.show()
3)패션 이미지 분류
=>데이터 가져오기:Keras 의 내장 데이터세트 활용
여러가지 종류)boston housing, cifar10, cifar100,mnist,..등등
-load_data라는 함수를 호출하면 훈련 데이터 튜플과 테스트 데이터 튜플로 데이터를 리턴해줍니다
각각의 튜플은 피처와 레이블로 나뉘어져 있습니다.
=>데이터 확인
fashion_mnist = keras.datasets.fashion_mnist
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist.load_data()
#딥러닝은 0~1사이의 실수인 경우 학습을 더 잘하는 것으로 알려짐
X_valid, X_train = X_train_full[:5000] / 255., X_train_full[5000:] / 255.
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
X_test = X_test / 255.
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
n_rows = 4
n_cols = 10
plt.figure(figsize=(n_cols * 1.2, n_rows * 1.2))
for row in range(n_rows):
for col in range(n_cols):
index = n_cols * row + col
plt.subplot(n_rows, n_cols, index + 1)
plt.imshow(X_train[index], cmap="binary", interpolation="nearest")
plt.axis('off')
plt.title(class_names[y_train[index]], fontsize=12)
plt.subplots_adjust(wspace=0.2, hspace=0.5)
save_fig('fashion_mnist_plot', tight_layout=False)
plt.show()
=>모델 생성
model = keras.models.Sequential()
#Dense 는 데이터의 차원을 1차원으로 입력 받아야합니다
#이미지 데이터의 경우는 가로 * 세로 또는 가로*세로 * 채널의수 로 입력
model.add(keras.layers.Flatten(input_shape=[28, 28]))
model.add(keras.layers.Dense(300, activation="relu"))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.summary()

※활성화 함수
-입력을 비선형 출력으로 변환해주는 함수
-선형 관계를 나타내는 함수에 비선형성을 추가하는 방법
-Sigmoid,ReLu,tanh 등이 있는데 적용방법은
https://www.tensorflow.org/api_docs/python/tf/keras/activations에 기록
※손실 함수
- 출력 층의 활성화 함수가 sigmoid:binary_crossentropy
- 출력 층의 활성화 함수가 softmax:categorical_crossentropy(원핫인코딩 된 경우)
sparse_categorical_crossentropy(원핫 인코딩 안된 경우)
※옵티마이저 함수
-손실을 낮추기 위해서 신경망의 가중치와 학습률 등의 신경망의 속성을 변경하는데 사용되는 최적화 방식
-종류
SGD(확률적 경사하강법)
RMSprop
Adam: 가장 많이 사용되는 알고리즘으로 좋은 성능을 내는 것으로 알려져 있음
Ftrl 등등존재
-평가 지표
-분류:auc, precision,recall,accuarcy
-회귀:,mse, mae,rmse
=>모델 컴파일
분류를 할 때 활성화 함수가 sigmoid 이면 loss 가 binary_crossentropy
softmax 이고 원핫인코딩 되어 있으면 categorical_crossentropy
softmax이고 원핫인코딩 안되어 있으면 sparse_categorical_crossentropy
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
=>모델 훈련
history = model.fit(X_train,y_train,epochs=30,validation_data=(X_valid,y_valid))
=>모델 평가
model.evaluate (X_test,y_test)
=>예측
-predict:각 클래스에 대한 기댓값
-predict_classes : 가장 높은 클래스가 리턴
y_pred = np.argmax(model.predict(X_new),axis=-1)
print(y_pred)
for i in range(3):
print(class_names[y_pred[i]])
4)실습 - Sequential API를 사용하여 회귀 구현
층을 연결하고 모든 데이터가 순차적으로 층을 통과하면서 출력을 만드는 방식
=>데이터 불러오기
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
#print(type(housing))
#외부에서 데이터를 가져오면 자료형 확인
#dict 이면 모든 key 확인
#class 이면 dir 확인
print(dir(housing))
=>데이터 전처리(분할 및 스케일링 처리)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
housing = fetch_california_housing()
X_train_full, X_test, y_train_full, y_test = train_test_split(housing.data, housing.target, random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)
=>모델 생성
- Sequential API를 이용해서 회귀용 MLP를 구축, 훈련, 평가, 예측하는 방법은 분류에서 했던 것과 매우 비슷하지만 차이점은 출력 층이 활성화 함수가 없는 하나의 뉴런을 가져야 한다는 것과 손실함수가 MSE 나 MAE 로 변경해야함
from tensorflow import keras
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=X_train.shape[1:]),
keras.layers.Dense(1)
])
model.compile(loss="mean_squared_error", optimizer=keras.optimizers.SGD(lr=1e-3))
#모델 학습
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
#모델 평가
mse_test = model.evaluate(X_test, y_test)
plt.plot(pd.DataFrame(history.history))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
5)실습 - Functional API를 활용한 회귀
Functional API가 나온이유: 일반적 MLP(Sequential API)는 네트워크에 있는 층 전체에 모든 데이터를 통과시키는데 이렇게 하면 간단한 패턴이 연속적인 변환으로 인해서 왜곡 될 수 있음
입력의 일부 또는 전체를 출력층에 바로 연결하는 방식
MLP가 전체를 통과하기도 하고 일부분만 통과하기도 하기 때문에 복잡한 패턴과 단순한 패턴 모두를 학습해서 더 좋은 성과를 내기도 합니다.
Sequential API는 그냥 쭉 쌓으면 되지만, Functional API는 일일이 어떻게 들어가는지 설명해야 합니다.
Functional API를 사용하게 되면 입력 데이터를 설정해주어야 합니다
층 간의 결합도 직접 설정해주어야 합니다.
#모델 만들기
input_ = keras.layers.Input(shape=X_train.shape[1:])
hidden1 = keras.layers.Dense(30, activation="relu")(input_)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs=[input_], outputs=[output])
model.compile(loss="mean_squared_error", optimizer=keras.optimizers.SGD(lr=1e-3))
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)
y_pred = model.predict(X_new)

=>여러 경로의 input을 사용
input_A = keras.layers.Input(shape=[5], name="wide_input")
input_B = keras.layers.Input(shape=[6], name="deep_input")
#input_A는 하나의 hidden 층도 통과하지 않은 데이터 이고 hidden 2 는 hidden층을 통과한 데이터
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1, name="output")(concat)
model = keras.models.Model(inputs=[input_A, input_B], outputs=[output])
모든 입력이 hidden layer 를 통과하게 되면 깊이가 깊어질 때 데이터의 왜곡이 발생할 수 있음
-학습 결과
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
X_train_A, X_train_B = X_train[:, :5], X_train[:, 2:]
X_valid_A, X_valid_B = X_valid[:, :5], X_valid[:, 2:]
X_test_A, X_test_B = X_test[:, :5], X_test[:, 2:]
X_new_A, X_new_B = X_test_A[:3], X_test_B[:3]
history = model.fit((X_train_A, X_train_B), y_train, epochs=20,
validation_data=((X_valid_A, X_valid_B), y_valid))
mse_test = model.evaluate((X_test_A, X_test_B), y_test)
y_pred = model.predict((X_new_A, X_new_B))

=>출력을 여러 개 생성
필요한 이유) 그림에 있는 주요 물체를 분류하고 위치를 알아야하는 경우가 있는데 이 경우는 분류와 회귀 동시에 수행해야하는 경우나, 다중 분류 작업을 하고자 하는 경우 나 보조 출력을 사용하고자 할 때
서로 다른 입력을 받아서 딥러닝을 수행한 후 일정 비율을 적용해서 반영
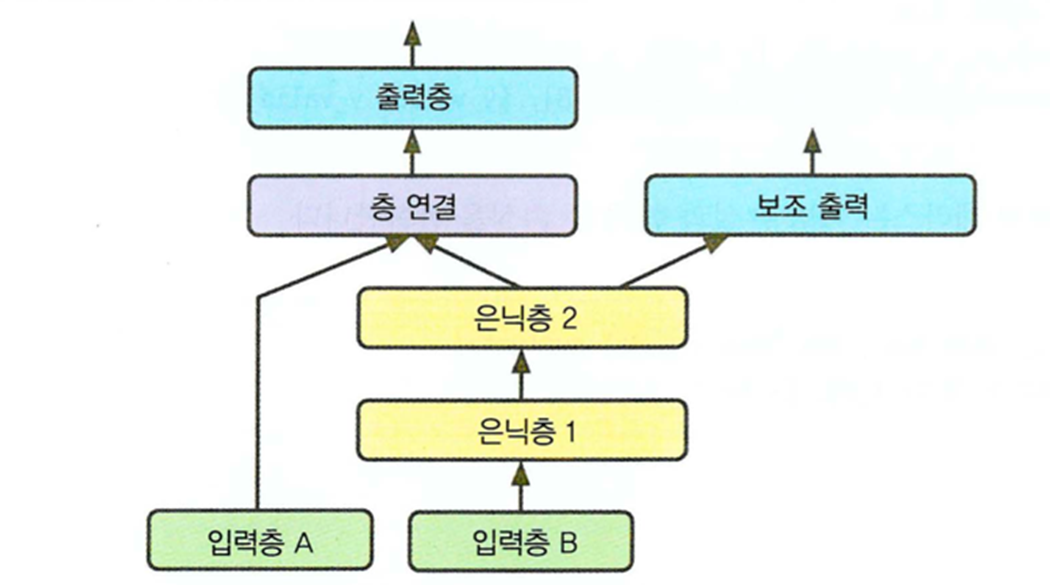
=>다른 입력을 받아서 출력을 만든 후 0.9 대 0.1 비율로 출력 만들기
#손실 ㅎ마수를 수행할 때 각 출력의 비중을 다르게 반영하도록 하기
#여러 경로의 input 사용
input_A = keras.layers.Input(shape=[5], name="wide_input")
input_B = keras.layers.Input(shape=[6], name="deep_input")
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1, name="main_output")(concat)
aux_output = keras.layers.Dense(1, name="aux_output")(hidden2)
#보초 출력 추가하기
model = keras.models.Model(inputs=[input_A, input_B],
outputs=[output, aux_output])model.compile(loss=["mse", "mse"], loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(lr=1e-3))
history = model.fit((X_train_A,X_train_B),y_train,
epochs = 20,validation_data = ((X_valid_A,X_valid_B),y_valid))
출력값이 2개이상 나오는 것을 확인할 수 있음
model.evaluate([X_test_A,X_test_B],y_test)
'Study > Deep learning' 카테고리의 다른 글
| Deep learning(6) - 자연어처리 (1) | 2024.03.25 |
|---|---|
| Deep Learning(5)-RNN (0) | 2024.03.22 |
| Deep learning(4) - CNN (0) | 2024.03.21 |
| Deep Learning(3) - Optimizer 와 activation함수 알아보기 (0) | 2024.03.20 |
| Deep Learning(1) - 개요 (0) | 2024.03.18 |



