1. colab 에서 사용시 데이터 활용
=>구글 드라이브 마운트
from google.colab import drive
drive.mount('/content/drive')
2.CNN개요
=>CNN(Concolutional Neural Network) 은 대뇌의 시각 피질 연구에서 시작되었구 1980년대 부터 이미지 인식 분야에서 사용되었는데 최근에는 복잡한 이미지 처리 문제에서 사람의 성능을 능가하기도 함
=>최근에는 이미지 검색 서비스, 자율 주행, 영상 자동 분류 시스템에 큰 기여를 함
=>음성 인식 분야나 자연어 처리같은 다른 작업에도 사용됨
=>뉴런들이 시각의 일부 범위 안에 있는 시각 자극에만 반응
=>고수준 뉴런이 이웃한 저수준 뉴런의 출력에 기반
=>이미지 인식 분야에서는 완전 연결 층의 심층 신경망을 사용하지 않는데 이런 신경망은 작은 이미지(MNIST)에서는 잘 동작하지만 큰 이미지에서는 아주 작은 파라미터가 만들어지기 때문에 문제가 발생해서 100* 100 이미지라면 픽셀은 10,000개 이고 Hidden layer 를 뉴런 1000개로 생성한다면 파라미터 또는 연결이 1000 만개가 만들어져야 함
이렇게 되면 과대적합 문제가 발생할 수 있으므로 CNN은 층을 부분적으로 연결하고 가중치를 공유해서 이문제를 해결

=>첫번째 합성곱 층의 뉴런은 입력 이미지의 모든 픽셀에 연결되는 것이 아니라 합성곱 층 뉴런의 수용장 안에 있는 픽셀에만 연결
두번째 합성곱 층에 있는 뉴런은 첫번째 층의 작은 사각 영역 안에 위치한 뉴런에만 연결
=>완전 연결층은 한 줄로 길게 늘어선 뉴런으로 구성되기 때문에 입력 이미지를 신경망에 주입할 때 1D 배열로 펼쳐야 했는데, CNN에서는 각 층이 2D로 표현되기 때문에 뉴런을 그에 상응하는 입력과 연결하기가 더 쉬움
공장에서 불량률을 따질 때 정확하게 하는 것도 중요하지만, 속도가 더 중요할 수 있습니다.
1)Stride
=>한 수용장과 다음 수용장 사이의 간격
2)필터
=>수용장 안에 있는 데이터를 값으로 치환할때 적용하는 행렬
=>실제 합성곱 층은 여러가지 필터를 가지고 필터마다 하나의 특성 맵을 출력하기 때문에 2D 이미지가 3D로 표현
3)채널
=>입력 이미지를 구성하는 2차원 배열의 수
=>흑백 이미지는 단일 채널 즉 채널의 개수가 1개인 이미지이고 컬러 이미지의 경우는 3개의 채널 (RGB)
=>컬러 이미지의 shape은 5*5 픽셀이라면 (5,5,3)으로 표현
=>실제 계산이 될 때는 각 채널마다 하나씩 커널을 적용해서 합성곱 연산을 수행하고 그 결과를 element-wise 덧셈연산으로 모두 더해주면 최종 특성 맵이 만들어집니다.

4)패딩
=>좌우 여백
=>패딩을 적용하지 않고 수용장을 만들면 사이드에 있는 특성이 적게 적용되는 현상이 발생
길이 또는 적용 횟수를 동일하게 만들기 위해서 값을 채움
5)합성곱 구현
=>텐서플로에서 각 입력 이미지는 보통 [높이,너비,채널] 형태의 3D텐서로 표현
=>하나의 미니 배치는 [ 미니배치 크기, 높이, 너비, 채널] 형태의 4D 텐서로 표현
=>합성곱의 가중치도 4D텐서이고 편향은 1D텐서
6)이미지에 필터 적용
-흑백으로 이미지 출력하는 함수랑 컬러로 출력하는 이미지 함수
def plot_image(image):
plt.imshow(image, cmap="gray", interpolation="nearest")
plt.axis("off")
def plot_color_image(image):
plt.imshow(image, interpolation="nearest")
plt.axis("off")
-이미지 가져오기
!pip install Pillow
import PIL.Image as Image
#이미지 가져오기 및 출력
china = np.array(Image.open("/content/drive/MyDrive/china.jpg")) / 255
flower = np.array(Image.open("/content/drive/MyDrive/flower.jpg")) / 255
images = np.array([china, flower])
plt.imshow(china)
plt.axis("off")
plt.show()
=>이미지를 7*7 이미지로 변경
batch_size, height, width, channels = images.shape
# Create 2 filters
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # vertical line
filters[3, :, :, 1] = 1 # horizontal line
#합성곱 적용
outputs = tf.nn.conv2d(images, filters, strides=1, padding="SAME")
plt.imshow(outputs[0, :, :, 1], cmap="gray")
plt.axis("off")
plt.show()
=>tf.nn.conv2d
-images 는 (첫번째 매개변수)는 입력의 미니배치(4D텐서)
-filters 는 적용될 일련의 필터(4D텐서)
-strides 는 1개나 4개의 원소를 갖는 1D배열로 지정할수 있는데 배열로 설정할 때는 첫번째와 마지막은 1이어야하고 두번쨰가 수직 그리고 세번째가 수직
-padding은 Valid 나 Same 둘 중 하나로 Valid 를 설정하면 제로 패딩을 사용하지 않은 것이고 SAME을 사용하면 제로 패딩을 사용
=>실제 사용은 대부분 keras.layers.Conv2D (filters = ? , kernel_size=?,strides=?,padding=?,activation=?)을 사용
7)메모리 요구 사항
=>합성곱 층은 많은 양의 RAM을 필요로 합니다
CNN 모델을 colab의 무료계정에서 사용하면 메모리 부족이 발생하는 경우가 있음
=>훈련하는 동안 역전파 알고리즘이 역방향 계산을 할 때 정방향에서 계산했던 모든 값을 필요로 하기 때문
=>5*5 필터로 스트라이드 1과 same 패딩을 사용해서 150 * 100 크기의 이미지를 뉴런 200개를 가지고 수행하는 합성곱 층은 (5*5*3 +1) *200 *32 byte의 연산이 이루어져야 하고 여기에 미니배치가 100이라면 곱하기 100을 더해야 함
8)Pooling layer
=>합성곱 층에서 사용한 파라미터의 수를 줄이기 위해서 subsample을 만드는 것
=>최대나 최소 값은 합산함수를 사용해서 입력값을 더해주는 것
=>최대 폴링(입력 값 손실이 심함)과 최소 폴링이 있음.
=>일반적으로 MaxPooling 함수를 사용하는게 성능이 좋다고 보지만 75%데이터를 잃어버림
=>Keras 에서는 MaxPool2D와 AvgPool2D 클래스로 제공하는데 생성할 떄 pool_size 에 풀링의 크기를 설정

from tensorflow import keras
#최대 풀링 층을 생성 - 이미지를 1/4의 데이터만 가지고 생성
#2*2 영역 중 가장 큰 데이터만 사용
max_pool = keras.layers.MaxPool2D(pool_size=2)
#이미지를 자르는 함수
def crop(images):
return images[150:200, 130:250]
#이미지 자르기
cropped_images = np.array([crop(image) for image in images], dtype=np.float32)
#Pooling 적용
output = max_pool(cropped_images)
fig = plt.figure(figsize=(12, 8))
gs = mpl.gridspec.GridSpec(nrows=1, ncols=2, width_ratios=[2, 1])
ax1 = fig.add_subplot(gs[0, 0])
ax1.imshow(cropped_images[0])
ax1.axis("off")
ax2 = fig.add_subplot(gs[0, 1])
ax2.imshow(output[0])
ax2.axis("off")
plt.show()
=>최대 풀링 과 평균 풀링은 공간 차원으로 수행을 하는데 깊이 차원으로 수행하고자 하면 keras 에서 제공해주지 않기 때문에 Layer를 상속받아서 직접 구현하게 됩니다.
=>Global Average Poling Layer
- 마지막 Pooling Layer로 주로 사용
- 각 특성 맵의 평균을 계산
- 각 특성 맵마다 하나의 숫자를 출력
- 거의 대부분을 잃어버리기 때문에 파괴적인 연산이지만 출력 층에서는 유용할 수 있습니다.
- keras.layers.GlobalAvgPool2D 클래스를 사용
#GlobalAvgPool2D
#특성 맵 전체의 평균을 사용하기 때문에 채널 당 하나의 값만 유지
global_avg_pool = keras.layers.GlobalAvgPool2D()
global_avg_pool(cropped_images)
3.CNN구조
1)일반적인 구조
=>합성곱 층을 몇 개 쌓고 그 다음에 풀링층을 쌓고 그 다음에 합성곱 층을 쌓고 그 다음에 풀링층을 쌓는 식
2)CNN을 이용한 패션 이미지 분류
=>데이터 가져오기
#데이터 가져오기
from sklearn.model_selection import train_test_split
(train_input, train_target),(test_input,test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape)
#스케일링 - 흑백 이미지라서 차원을 1개 늘려서 255 로 나눔
train_scaled = train_input.reshape(-1,28,28,1) /255.0
print(train_scaled.shape)
train_scaled,val_scaled, train_target , val_target = train_test_split(train_scaled,train_target , test_size =0.2 , random_state=42)
=>모델 생성
model = keras.Sequential()
#32개의 필터를 사용하며 커널의 크기는 (3,3) 이고 relu 활성화 함수와 same 패딩 사용
model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu', padding='same',
input_shape=(28,28,1)))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Conv2D(64, kernel_size=(3,3), activation='relu', padding='same'))
model.add(keras.layers.MaxPooling2D(2))
#데이터를 1차원으로 만들어주는 층
model.add(keras.layers.Flatten())
#데이터를 1차원으로만 Dense활용
model.add(keras.layers.Dense(100, activation='relu'))
#드랍아웃 적용
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
#Adam 옵티마이저 사용하고 Modelcheckpoint 콜백과 EarlyStopping 콜백을 함께 사용해 조기 종료기법
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-cnn-model.keras')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
#아래 합성곱 층으로 내려갈 떄 뉴런의 개수를 늘렸는데 이유는 중간에 MaxPooling2D(Dropout 적용해도 동일)를 적용했기 실제 파라미터 개수가 줄어들어서 사용되므로 뉴런의 개수를 늘려도 실제 늘어난 효과가 나타나진 않음
딥러닝은 fit 을 하면 이전에 훈련한걸 가지고 다시 훈련하고 있음
따라서 parameter를 수정하면 model부터 다시 만들어서 해야 원래대로 학습함
#평가
#훈련에 사용하는데이터가 스케일링이 되어있다면 에측에 사용하는 데이터도 스케일
model.evaluate(test_scaled,test_target)
3)도로 교통 표지판 인식
=>데이터
- 43개의 교통 표지판과 관련된 4만여개의 이미지로 만들어진 데이터셋
https://drive.google.com/drive/folders/1AktNCWqVBv-4xxme4OUC82OLJTHzMFsq?usp=sharing
-ppm:무손실 압축 이미지 파일 형식
-image크기: 32*32
=>신경망 구조를 만들 떄 선택 사항
- 2차원 컨볼루션에서 필터 개수와 커널크기
-Fully Connected 계층(Dense)에서의 유닛 개수
-계층 별 배치 크기, 최적화 알고리즘, 학습률, 활성화 함수, epoch 수 등
=>이미지 전처리
-이미지 크기를 32* 32 생성
-43개의 레이블 생성: 디렉토리 이름이 레이블
-표지판의 경우 구분해야 할 것은 색상이 아니라 모양: 이미지를 흑백으로 변경
objective detection 할 경우 색깔이 중요한게 아니라 모양이 중요함 => 색깔 값 무효 시킴
데이터를 다룰 때 목적을 생각하고 작업을 시작해야합니다
# 클래스 개수와 이미지의 크기를 변수에 저장
#이 2개의 값은 constant값
#변하지 않는 값을 저장할 변수의 이름은 모두 대문자로 작성하는 것이 좋습니다
#SNAKE 표기법
N_CLASSES = 43
RESIZED_IMAGE = (32, 32)
import matplotlib.pyplot as plt
import glob
from skimage.color import rgb2lab
from skimage.transform import resize
from collections import namedtuple
import numpy as np
np.random.seed(101)
%matplotlib inline
#이름이 있는 튜플 생성 - 다른 언어에서는 튜플을 이런 형태로 만듬
#튜플의 원래 목적은 변경할 수 없는 하나의 행 (record, row )를 표현하기 위한 것이므로
#인덱스가 아니라 이름으로 구별하는 것이 타당
Dataset = namedtuple('Dataset', ['X', 'y'])collections 패키지 공부해야함 => namedtuple, deque, Counter, OrderDict 만큼은 꼭 알아야함 ★
itertools 패키지도 공부해야함
glob => 디렉토리를 핸들링 할 때 사용하는 모듈
#포맷 변경해주는 함수
def to_tf_format(imgs):
return np.stack([img[:, :, np.newaxis] for img in imgs], axis=0).astype(np.float32)#이미지 디렉토리에 있는 모든 이미지들에 라벨링을 하기 위한 작업
#이미지의 크기 변경도 여기서 수행
def read_dataset_ppm(rootpath, n_labels, resize_to):
#이미지 데이터와 라벨링을 저장할 list
images = []
labels = []
for c in range(n_labels):
#루트경로 /00001/형태로 이미지 경로 생성
full_path = rootpath + '/' + format(c, '05d') + '/'
#각 이미지 디렉토리를 순회하면서 확장자가 ppm 인 파일의 경로를 가지고
for img_name in glob.glob(full_path + "*.ppm"):
#이미지 읽어오기
img = plt.imread(img_name).astype(np.float32)
#이미지 정규화
img = rgb2lab(img / 255.0)[:,:,0]
if resize_to:
img = resize(img, resize_to, mode='reflect')
#라벨 생성
#43개짜리 배열을 만들어서 자신의 인덱스에 해당하는 값에만 1을 대입
#원핫 인코딩 된 라벨
label = np.zeros((n_labels, ), dtype=np.float32)
label[c] = 1.0
images.append(img.astype(np.float32))
labels.append(label)
return Dataset(X = to_tf_format(images).astype(np.float32),
y = np.matrix(labels).astype(np.float32))dataset = read_dataset_ppm("GTSRB_Final_Training_Images\GTSRB\Final_Training\Images"
, N_CLASSES, RESIZED_IMAGE)
print(dataset.X.shape)
print(dataset.y.shape)
=>데이터셋 분
from sklearn.model_selection import train_test_split
idx_train, idx_test = train_test_split(range(dataset.X.shape[0]), test_size=0.25, random_state=101)
X_train = dataset.X[idx_train, :, :, :]
X_test = dataset.X[idx_test, :, :, :]
y_train = dataset.y[idx_train, :]
y_test = dataset.y[idx_test, :]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
ar = []
ar = []
for i in np.asarray(y_train):
for k, j in enumerate(i):
if j == 1:
ar.append(k)
y_train = np.array(ar)
ar = []
for i in np.asarray(y_test):
for k, j in enumerate(i):
if j == 1:
ar.append(k)
y_test = np.array(ar)=>모델 생성
model = keras.Sequential()
model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu', padding='same',
input_shape=(32,32,1)))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Conv2D(64, kernel_size=(3,3), activation='relu', padding='same'))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(43, activation='softmax'))
model.summary()
=>모델 학습
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-cnn-model.keras')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)
history = model.fit(X_train, y_train, epochs=20,
callbacks=[checkpoint_cb, early_stopping_cb])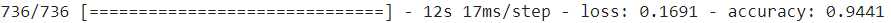
똑같은 데이터가 아닌 다른 데이터를 활용해야함
4.이미지 증강
1)CNN의 취약점
=>영상의 2차원 변환인 회전, 크기, 밀림, 반사,이동 과 같은 2차원 변환인 Affine Transform에 취약
=>Noise 삽입, 색상, 밝기 변형 등을 활용해서 Data Augmentation 효과를 얻어서 해결
2)augmentor 라이브러리를 이용한 증강
=>증강된 이미지를 output이라는 별도의 디렉토리에 저장
=>기본 패키지가 아니라서 설치를 해야합니다: pip install Augmentor
import Augmentor
img = Augmentor.Pipeline('./sample')
# 좌우 반전
img.flip_left_right(probability=1.0)
# 상하 반전
img.flip_top_bottom(probability=1.0)
#모퉁이 왜곡
img.skew_corner(probability=1.0)
#회전&크롭
img.rotate_without_crop(probability=1, max_left_rotation=0.8, max_right_rotation=0.8, expand=False, fillcolor=None)
# 왜곡
img.random_distortion(probability=1, grid_width=10, grid_height=10, magnitude=30)
# 증강 이미지 수
img.sample(1)sample 디렉토리에 이미지가 있어야 하고 마지막에 만들 이미지의 개수를 설정해주어야 합니다
3)keras 의 ImageDataGenerator
=>문서: 케라스의 imagedatagenerator 검색
=>기능
-학습 도중에 이미지에 임의 변형 및 정규화를 적용
-변형된 이미지를 배치 단위로 불러올 수 있는 Generator 생성
=>generator 를 생성할 때 flow(data, label) 과 flow_from_directory(디렉토리) 두가지 함수를 이용
=>변환하는 파라미터
- rotation_range
- width_shift_range
...
=>효과 생성
from keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.preprocessing import image
#효과 생성
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
rescale= 1.0/255.0,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')효과 생성시 주의 : 증강을 하는 이유는 이미지에 변화를 주어서 학습 데이터를 많게 해서 성능을 높이기 위해서 수행하기 때문에 train_set 에만 수행하면 되지만, rescale 이 있는 경우는 test_set 에도 해주어야합니다.
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='sample/', save_prefix='adam', save_format='jpeg'):
i += 1
if i > 20:
break # 이미지 20장을 생성하고 마칩니다
5.데이터 증강을 이용한 분류
1)데이터
- url: https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
- 코드로 압축 해제
import shutil
shutil.unpack_archive('파일 경로', '압축을 해제할 경로')
2)데이터 경로 설정
# 데이터 디렉토리 설정
train_dir = "./data/cats_and_dogs_filtered/train"
valid_dir = "./data/cats_and_dogs_filtered/validation"
3)데이터 증강을 위한 설정
rom tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.preprocessing import image
#데이터 증강 객체를 생성(데이터 증강은 일반적으로 이미지에서만 수행)
image_gen = ImageDataGenerator(rescale=(1/255.))
#증강할 이미지가 있는 디렉토리를 설정
#이미지 증강을 할 때 여러 레이블이 있는 경우는 디렉토리로 구분
train_gen = image_gen.flow_from_directory(train_dir,
batch_size=32,
target_size=(224, 224),
classes=['cats', 'dogs'],
class_mode='binary',
seed=2020)
valid_gen = image_gen.flow_from_directory(valid_dir,
batch_size=32,
target_size=(224, 224),
classes=['cats', 'dogs'],
class_mode='binary',
seed=2020)
4)샘플이미지 출력
#샘플 이미지 출력
class_labels = ['cats', 'dogs']
batch = next(train_gen)
images, labels = batch[0], batch[1]
plt.figure(figsize=(16, 8))
for i in range(32):
ax = plt.subplot(4, 8, i+1)
plt.imshow(images[i])
plt.title(class_labels[labels[i].astype(np.int8)])
plt.axis('off')
plt.tight_layout()
plt.show()
5)모델 생성 - 출력이 둘 중 1개를 구분하는 이진 분류(출력하는 값은 1개이고 활성화 함수는 sigmoid)
import tensorflow as tf
from tensorflow import keras
#모델 생성
def build_model():
model = tf.keras.Sequential([
#배치 정규화
#정규화하는 이유는 학습을 빨리 하기 위한 목적과 지역 최저점에 도달하는 것을 방지
#학습을 할 때 평균 과 분산을 조정해서 정규화 해줍니다.
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(32, (3, 3), padding='same', activation="relu"),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(64, (3, 3), padding='same', activation="relu"),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(128, (3, 3), padding='same', activation="relu"),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Dense(1, activation='sigmoid')
])
return model
model = build_model()
model.summary()
6)모델 컴파일 및 훈련
#모델 컴파일 및 훈련
model.compile(optimizer=tf.optimizers.Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
early_stopping_cb = keras.callbacks.EarlyStopping(patience=5,
restore_best_weights=True)
history = model.fit(train_gen, validation_data=valid_gen, epochs=20)
6.전이 학습
1)개요
=>기존에 보유한 지식을 기반으로 복잡한 작업에 숙달하거나 비슷한 행동에 이미 가지고 있는 기술을 바꿔 적용하는 것
=>머신러닝은 특정 단일 작업을 수행하기 위한 용도로 설계
- 하나의 훈련된 모델을 다른 데이터 셋에 바로 적용하면 형편없는 결과를 얻을 수 있음
두 데이터 샘플의 의미가 동일하지 않은 경우: MNIST 로 학습한 후 ImageNet 데이터에 적용
동일한 이미지 품질이나 샘플이 아닌 경우: 해상도 차이가 너무 많이 나는 경우
=>활용 사례
- 제한적 훈련 데이터로 유사한 작업 수행
제공되는 사전 훈련된 모델을 가져온 후 마지막 계층을 제거하고 목표한 작업에 맞춰 조정한 계층으로 교체하고 수행
- 제한적 훈련 데이터로 유사하지 않은 작업 수행하는 경우
마지막 계층 뿐 아니라 최종 합성곱 일부분도 제거하고 위에 얕은 분류기를 추가
- 데이터가 충분히 많다면 직접 모델을 생성해서 작업을 수행해도 되지만 일반적으로 전이학습을 이용하는 것이 효율적이라고 알려져 있습니다.
2)구현
=>계층 제거
- model.layers.pop(): 마지막 계층이 제거
=>계층 추가
- Model(기존레이어, 추가할 레이어)
3)LeNet-5
=>가장 널리 알려진 CNN 구조
=>얀 르쿤이 1998 년에 만듬
4)AlexNet
- 2012년 이미지 분류 대회에서 우승한 모델
5)VGGNet
=>2014년 옥스퍼드 대학교에서 만든 모델로 이미지 분류 대회에서 2위를 한 모델
=>간단한 CNN 모델이어서 YOLO, R-CNN, SSD 등 의 물제 검출기에서 특징 검출기로 사용한 모델
=>케라스에서 이 모델을 제공
6)GoogleNet
'Study > Deep learning' 카테고리의 다른 글
| Deep learning(6) - 자연어처리 (1) | 2024.03.25 |
|---|---|
| Deep Learning(5)-RNN (0) | 2024.03.22 |
| Deep Learning(3) - Optimizer 와 activation함수 알아보기 (0) | 2024.03.20 |
| DeepLearning(2)-딥러닝 기초 (0) | 2024.03.19 |
| Deep Learning(1) - 개요 (0) | 2024.03.18 |



