1.자연어 처리
1)자연어 처리 분야
=>규칙 기반 처리
=>확률 기반 처리
-자연어 이해
-자연어 생성
2)자연어 처리에서 많이 사용되는 모델
=> BERT(Bidirectional Encoder Representations from Transformer)
- 사전 학습 단계에서 입력 문장의 좌우 문맥을 고려해서 단어의 Embedding 벡터를 생성한 후 Fine Tuning(미세 조정) 단계에서 해당 과제의 데이터로 추가 학습하여 성능을 개선
=>GPT(Generative Pretrained Transformer)
- 단방향 언어 모델
- 이전 단어들을 사용해서 다음 단어를 생성하도록 학습
- 주어지는 문장의 길이나 선택 가능성에 따라 뒤에 올 수 있는 단어의 수는 제한적
3)딥러닝 모델을 사용하기 위한 데이터 셋 준비
=>과정
-토큰화(공백을 기준으로 나누거나 형태소 분석을 수행) + 단어 사전(단어 와 숫자를 매칭)
-문장 인코딩(사전을 바탕으로 문장들을 숫자로 변경)
=>단어사전을 만들 떄 일반적으로 자주 등장하는 단어가 앞쪽에 배치
=>토큰화
- 영문의 경우 공백을 기준으로 분할
keras 에서 Tokenizer 라는 클래스를 이용해서 토큰화를 수행할 수 있도록 함
from tensorflow.keras.preprocessing.text import Tokenizer
sentences =[
'영실이는 나를 너무 좋아해',
'영실이는 영화를 무척 좋아해'
]
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
print(tokenizer.word_index)
#문장 인코딩
word_encoding = tokenizer.texts_to_sequences(sentences)
print(word_encoding)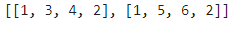
=>OOV(사전에 없는 새로운 단어)
- 기본적으로는 무시됨
new_sequences = ['영실이는 아담을 좋아해']
#사전에 없는 단어는 기본적으로 무시됨
word_encoding = tokenizer.texts_to_sequences(new_sequences)
print(word_encoding)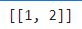
- encoding결과에서 없는 단어는 결과가 나오질 않음
-Out of Vocabulary 처리를 위해서 Keras 에서는 OOV Token 이라는 개념 도입
-Tokenizer 를 생성할 떄 oov_token이라는 매개변수에 OOV에 대한 태그 값을 설정할 수 있도록 함
tokenizer = Tokenizer(oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
print(tokenizer.word_index)
word_encoding = tokenizer.texts_to_sequences(new_sequences)
print(word_encoding)
=>빈도 수 문제
-텍스트 데이터셋을 만들 떄 빈도수가 작은 단어가 많이 존재하는 경우에 이들 단어를 제외하기도 합니다
-문장을 토큰으로 인코딩할 때 빈도수가 많은 순서대로 최대 사전 개수를 정하고 빈도수가 적은 단어를 제외
-num_words 파라미터를 통해 설정하는데 여기에 설정한 빈도 순으로 인코딩하고 나머지는 OOV 로 처리
-Tokenizer 를 생성할 때 num_words 파라미터를 이용하게 되는데 사전에 단어가 포함되지 않는 것이 아니고 문장을 인코딩할 때 제외되는 것입니다
tokenizer = Tokenizer(oov_token="<OOV>",num_words=3)
tokenizer.fit_on_texts(sentences)
print(tokenizer.word_index)
#문장을 인코딩할 때 3개의 단어만 사용하고 나머지는 모두 OOV 처리
word_encoding = tokenizer.texts_to_sequences(new_sequences)
print(word_encoding)
=>패딩
-RNN에 데이터를 입력으로 넣기 위해서는 길이가 동일하게 맞추어 져야하는데 이 작업을 수행하는 것을 padding이라고 합니다
-keras 에서는 pad_sequence 라는 함수를 제공하는데 최대 문장 길이 보다 짧으면 앞에 0을 추가해주는데 뒤에 추가할 수도 있습니다
from tensorflow.keras.preprocessing.sequence import pad_sequences
sentences =[
'영실이는 아담을 정말 정말 좋아해',
'영실이는 영화를 좋아해'
]
word_encoding = tokenizer.texts_to_sequences(sentences)
print(pad_sequences(word_encoding))
print(pad_sequences(word_encoding,padding = 'post'))
=>단어에 대한 인덱스 부여
-Keras 의 Embedding은 단어 각각에 대해서 Embedding 작업을 수행할 수 있도록 합니다.
-기본적으로 많이 등장한 단어에 앞쪽에 인덱스를 부여하는데 이렇게 한 경우 인덱스가 단어의 등장 횟수를 나타내기 때문에 등장 횟수가 적은 단어 제거가 쉽습니다
인덱스 1000이상 제거하게 되면 자주 등장한 단어 1000개만 사용하는 것이 됩니다
4)한국어 전처리
=>데이터 불러오기
#데이터 읽어오기
train = pd.read_csv('./ratings_train.txt',sep='\t')
train.head()
=>형태소 분석기 생성
#형태소 분석기 생서 - McCab 가 가장 빠른데, Windows에 설치가 안됨
import konlpy
from konlpy.tag import Kkma,Komoran,Okt
kkma=Kkma()
komoran= Komoran()
okt = Okt()
=>형태소 분석기 사용
text="시리야오늘날씨어때?" # 같이 띄어쓰기가 안된 경우 사용 불가능
#형태소 분석을 수행해서 단어와 품사를 리턴
print(kkma.pos(text))
print(komoran.pos(text))
print(okt.pos(text))
=>텍스트 전처리 (정규표현식 사용)
#텍스트 전처리 - 공백 제거
#영어 와 한글만 남겨두고 삭제
#자연어를 이용해서 감성 분석 같은 작업 할때 대부분의 경우는 숫자 제거
train['document']=train['document'].str.replace("[^A-Za-z가-힣ㄱ-ㅎ ㅏ-ㅣ]","")
train['document'].head()
=>불용어 제거
#형태소 분석기 객체 생성
from konlpy.tag import Okt
okt = Okt()
def word_tokenization(text):
#불용어 사전
stop_words = ['는','을','를','이','와']
return [word for word in okt.morphs(text) if word not in stop_words]
data = train['document'].apply((lambda x : word_tokenization(x)))
data.head()
=>데이터 분리
#훈련 데이터와 검증 데이터 분리
training_size =120000
train_sentences = data[:training_size]
test_sentences = data[training_size:]
train_labels = train['label'][:training_size]
test_labels = train['label'][training_size:]
=>토큰화
#토큰화 - 단어 사전을 만들고 문장을 숫자로 변환
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
#현재 가진 텍스트를 가지고 단어 사전 생성
tokenizer = Tokenizer()
tokenizer.fit_on_texts(data)
print("단어 개수:",len(tokenizer.word_index))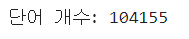
=>자주 사용하지 않은 단어 제거
#5회 이상 등장하지 않은 단어 제거
def get_vocab_size(threshold):
cnt = 0
for x in tokenizer.word_counts.values():
if x >=threshold:
cnt = cnt + 1
return cnt
print("5회이상 등장한 단어의 개수:",get_vocab_size(5))
=>OOV
oov_tok = "<OOV>"
vocab_size = 15000
tokenizer = Tokenizer(oov_token = oov_tok, num_words = vocab_size)
tokenizer.fit_on_texts(data)
print("단어 개수:",len(tokenizer.word_counts))
=>문장을 숫자로 변경
#문장을 숫자로 변경
train_sequences = tokenizer.texts_to_sequences(train_sentences)
valid_sequences = tokenizer.texts_to_sequences(valid_sentences)
print(train_sentences[:3])
print(train_sequences[:3])
=>문장의 길이를 전부 동일하게 만들기
#문장의 길이를 전부 동일하게 만들기
#가장 긴 문장 길이를 확인
max_length = max(len(x) for x in train_sequences)
print(max_length)
#문장의 길이가 최대 길이보다 짧은 경우 0을 채울 위치와 최대 길이보다 긴 경우
#자를 위치를 설정
trunc_type ='post'
padding_type = 'post'
train_padded = pad_sequences(train_sequences , truncating = trunc_type,
padding=padding_type,maxlen=max_length)
valid_padded = pad_sequences(valid_sequences , truncating = trunc_type,
padding=padding_type,maxlen=max_length)
train_labels = np.asarray(train_labels)
valid_labels = np.asarray(valid_labels)
=>결과 확인
#원래 아 더빙.. 진짜 짜증나네요 목소리 텍스트 였는데 형태소 분석을 해서
#단어의 list로 변경한 후 숫자로 변경하고 일정한 길이로 맞추는 작업을 수행
print(train_sentences[:1])
print(train_sequences[:1])
print(train_padded[:1])
3.RNN을 이용한 자연어 처리
1)RNN에서 사용한 용어를 자연어 처리에 반영
=>hidden_size: 출력의 크기
=>timesteps: 각 문서에서의 단어 수
=>input_dim: 각 단어의 벡터 표현의 차원 수
2)RNN을 이용해서 분류
=>many - to - one
=>many - to - many: 마지막에 return_sequences = True 속성이 설정되어야합니다

RNN에서는 return_sequences = True 부분을 활용 잘 해야 합니다.
항상 기본적인 텍스트 문제는 many to one 문제인데 다른점은 클래스가 몇 개 이냐에 따라 이진 분류와 다중 클래스 분류로 나누면 이 두가지 경우 다른 활성화 함수와 손실함수를 사용
=>이진 분류는 활성화 함수로 시그모이드 그리고 손실함수로 categorical_crossentropy 를 사용하고 다중 분류 문제는 활성화 함수로 softmax 그리고 손실 함수로 categorical_crossentropy를 사용
3)RNN을 이용한 스펨메일 분류
=>데이터 가져오기 : kaggle data 활용
import urllib.request
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
data = pd.read_csv('spam.csv',encoding='latin1')
data.info()
v1: 스펨메일 여부
v2:메일 내용
=>데이터 preprocessing
#빈 컬럼 제거
del data['Unnamed: 2']
del data['Unnamed: 3']
del data['Unnamed: 4']
#스펨이면 1 아니면 0 으로 변경
data['v1'] = data['v1'].replace(['ham','spam'],[0,1])
data[:5]#data null 값 확인
data.isnull().values.any()#data 중복 확인
data['v2'].nunique(), data['v1'].nunique()#중복 제거
data.drop_duplicates(subset=['v2'], inplace=True) # v2 열에서 중복인 내용이 있다면 중복 제거
print('총 샘플의 수 :',len(data))
data['v2'].nunique(), data['v1'].nunique()#학습 데이터와 레이블 분리
X_data = data['v2']
y_data = data['v1']
print('메일 본문의 개수: {}'.format(len(X_data)))
print('레이블의 개수: {}'.format(len(y_data)))
=>문자열을 숫자로 변경
#토큰화 와 단어를 숫자값,인덱스로 변환하여 저장
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_data) # 5169개의 행을 가진 X의 각 행에 토큰화를 수행
sequences = tokenizer.texts_to_sequences(X_data) # 단어를 숫자값, 인덱스로 변환하여 저장
print(sequences[:5])#인덱스화 됬는지 확인
word_to_index = tokenizer.word_index
print(word_to_index)
#단어의 비율 확인
threshold = 2 # 단어의 최소 등장 횟수
#전체 단어의 개수
total_cnt = len(word_to_index)
rare_cnt = 0 #임계값보다 작은 등장 횟수 개수
total_freq = 0 #훈련 데이터의 전체 단어 빈도 수
rare_freq = 0 #threshold 보다 적게 등장한 단어의 빈도수 총합
# 단어와 빈도 수의 쌍(pair)을 key와 value로 받는다.
for key, value in tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도 수가 threshold보다 작으면
if(value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print("단어 집합(vocabulary)에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)
X_data = sequences
print('메일의 최대 길이 : %d' % max(len(l) for l in X_data))
print('메일의 평균 길이 : %f' % (sum(map(len, X_data))/len(X_data)))
plt.hist([len(s) for s in X_data], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()
메일 최대 길이와 평균 길이 확인 - 숫자로 변환할 떄 길이를 얼마로 할지 알기 위해서
일반적으로는 가장 긴 문자열을 찾아서 그 문자열의 길이로 패딩을 추가해서 사용하는데
아주 긴 내용이 1개가 있고 나머지 내용은 모두 짧은 경우 이 경우에는 긴 것에 맞추면 메모리 낭비
=>데이터에 패딩 적용
max_len = 189
# 전체 데이터셋의 길이는 max_len으로 맞춥니다.
data = pad_sequences(X_data, maxlen = max_len)
print("훈련 데이터의 크기(shape): ", data.shape)
=>데이터 분할
n_of_train = int(len(sequences) * 0.8)
n_of_test = int(len(sequences) - n_of_train)
print('훈련 데이터의 개수 :',n_of_train)
print('테스트 데이터의 개수:',n_of_test)
X_test = data[n_of_train:] #X_data 데이터 중에서 뒤의 1034개의 데이터만 저장
y_test = np.array(y_data[n_of_train:]) #y_data 데이터 중에서 뒤의 1034개의 데이터만 저장
X_train = data[:n_of_train] #X_data 데이터 중에서 앞의 4135개의 데이터만 저장
y_train = np.array(y_data[:n_of_train]) #y_data 데이터 중에서 앞의 4135개의 데이터만 저장
=> 모델 생성 및 학습
단어들 간의 관계 생성
단어를 몇 차원 벡터의 숫자로 만들것인가 하는 것
32차원 벡터로 변환하는데그냥 다른 숫자로 변환하는 것이 아니고 단어의 등장을 확인해서
단어가 가까이 등장하면 가깝게 멀리서 등장하면 거리를 멀게 숫자로 변환
첫번쨰 매개변수는 단어의 개수이고 두번째 매개변수는 변환할 벡터의 크기
from tensorflow.keras.layers import SimpleRNN, Embedding, Dense
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(Embedding(vocab_size, 32)) # Embedding 벡터의 차원은 32
model.add(SimpleRNN(32)) # RNN 셀의 hidden_size는 32
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train, y_train, epochs=10, batch_size=64, validation_split=0.2)
print("\n 테스트 정확도: %.4f" % (model.evaluate(X_test, y_test)[1]))

4)GRU를 이용한 네이버 쇼핑 리뷰 감성 분석
=>한글은 단어 사전 만드는 법이 다름
한글은 형태소 분석을 수행해야 합니다
직접 크롤링한 데이터들은 정리가 되어 있지 않기 때문에 특수문자나 숫자 등을 제거를 해주어야 합니다
중복데이터가 발생하는 경우가 많음
중복 된 데이터가 있으면 임베딩 같은 것을 할 때 종속이 심해집니다
=>데이터 가져오기
total_data = pd.read_table('./ratings_total.txt', names=['ratings', 'reviews'])
print('전체 리뷰 개수 :',len(total_data)) # 전체 리뷰 개수 출력header 가 따로 없어서 만들어야함
=>데이터 전처리
-감성분석을 하려고 하는데 감성에 대한 열이 없어서 ratings을 이용해서 직접 생성
ratings 3을 기준으로 해서 초과하면 긍정 그렇지 않으면 부정
total_data['label'] = np.select([total_data.ratings > 3], [1], default=0)
total_data[:5]
-중복 확인 및 중복 제거
total_data['ratings'].nunique(), total_data['reviews'].nunique(), total_data['label'].nunique()
total_data.drop_duplicates(subset=['reviews'], inplace=True) # reviews 열에서 중복인 내용이 있다면 중복 제거
print('총 샘플의 수 :',len(total_data))
- 데이터 분할
from sklearn.model_selection import train_test_split
train_data, test_data = train_test_split(total_data, test_size = 0.25, random_state = 42)
print('훈련용 리뷰의 개수 :', len(train_data))
print('테스트용 리뷰의 개수 :', len(test_data))
-공백 제거
# 한글과 공백을 제외하고 모두 제거
train_data['reviews'] = train_data['reviews'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
#아무 내용도 없는 텍스트를 찾아서 nan으로 치환
train_data['reviews'].replace('', np.nan, inplace=True)
print(train_data.isnull().sum())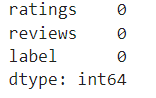
-테스트 데이터 전처리
test_data.drop_duplicates(subset = ['reviews'], inplace=True) # 중복 제거
test_data['reviews'] = test_data['reviews'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","") # 정규 표현식 수행
test_data['reviews'].replace('', np.nan, inplace=True) # 공백은 Null 값으로 변경
test_data = test_data.dropna(how='any') # Null 값 제거
print('전처리 후 테스트용 샘플의 개수 :',len(test_data))
-Okt모델 확인
okt = Okt()
print(okt.morphs('와 이런 것도 상품이라고 차라리 내가 만드는 게 나을 뻔'))
-불용어 제거(Okt 모델 보다는 Mecab 을 사용할 수만 있다면 사용하는게 나음)
stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를', '인', '듯', '과', '와', '네', '들', '듯', '지', '임', '게']
train_data['tokenized'] = train_data['reviews'].apply(okt.morphs)
train_data['tokenized'] = train_data['tokenized'].apply(lambda x: [item for item in x if item not in stopwords])
test_data['tokenized'] = test_data['reviews'].apply(okt.morphs)
test_data['tokenized'] = test_data['tokenized'].apply(lambda x: [item for item in x if item not in stopwords])
-negative word & postiive word
negative_words = np.hstack(train_data[train_data.label == 0]['tokenized'].values)
positive_words = np.hstack(train_data[train_data.label == 1]['tokenized'].values)
negative_word_count = Counter(negative_words)
print(negative_word_count.most_common(20))
positive_word_count = Counter(positive_words)
print(positive_word_count.most_common(20))


- 리뷰 평균 길이 확인
fig,(ax1,ax2) = plt.subplots(1,2,figsize=(10,5))
text_len = train_data[train_data['label']==1]['tokenized'].map(lambda x: len(x))
ax1.hist(text_len, color='red')
ax1.set_title('Positive Reviews')
ax1.set_xlabel('length of samples')
ax1.set_ylabel('number of samples')
print('긍정 리뷰의 평균 길이 :', np.mean(text_len))
text_len = train_data[train_data['label']==0]['tokenized'].map(lambda x: len(x))
ax2.hist(text_len, color='blue')
ax2.set_title('Negative Reviews')
fig.suptitle('Words in texts')
ax2.set_xlabel('length of samples')
ax2.set_ylabel('number of samples')
print('부정 리뷰의 평균 길이 :', np.mean(text_len))
plt.show()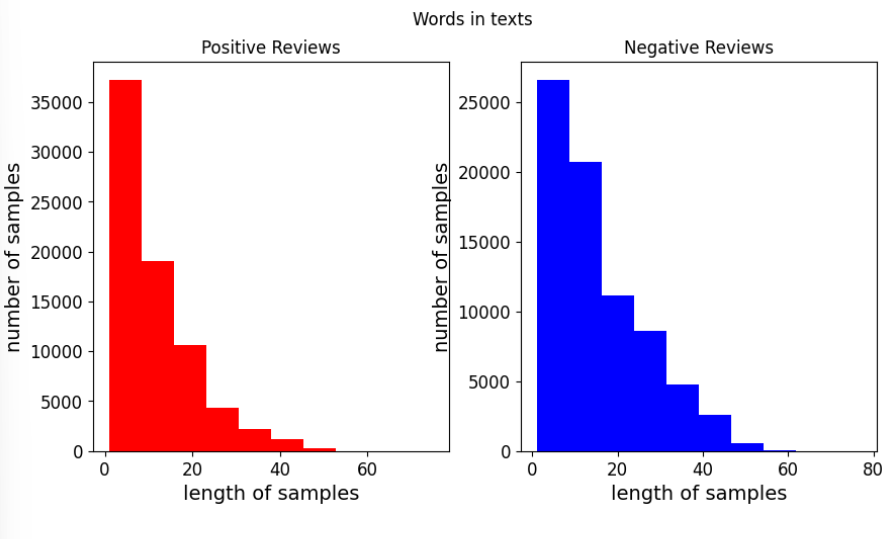
- 토큰화
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_train)
threshold = 2
total_cnt = len(tokenizer.word_index) # 단어의 수
rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트
total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합
rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합
# 단어와 빈도수의 쌍(pair)을 key와 value로 받는다.
for key, value in tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도수가 threshold보다 작으면
if(value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)
-text_to_sequences
tokenizer = Tokenizer(vocab_size, oov_token = 'OOV')
tokenizer.fit_on_texts(X_train)
X_train = tokenizer.texts_to_sequences(X_train)
X_test = tokenizer.texts_to_sequences(X_test)
print(X_train[:3])
-패딩
X_train = pad_sequences(X_train, maxlen = max_len)
X_test = pad_sequences(X_test, maxlen = max_len)
- 모델 생성 및 훈련
from tensorflow.keras.layers import Embedding, Dense, GRU
from tensorflow.keras.models import Sequential
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
model = Sequential()
model.add(Embedding(vocab_size, 100))
model.add(GRU(128))
model.add(Dense(1, activation='sigmoid'))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train, y_train, epochs=15, callbacks=[es, mc], batch_size=60, validation_split=0.2)
-글을 가지고 예측
#글을 가지고 예측
new_review = "이 상품 진짜 좋아요 저는 강추 대박"
#토큰화
new_sentence = okt.morphs(new_review)
#불용어 제거
new_sentence = [ word for word in new_sentence if not word in stopwords]
#정수 인코딩
encoded = tokenizer.texts_to_sequences([new_sentence])
#패딩
pad_new = pad_sequences(encoded, maxlen = max_len)
#예측
score = float(loaded_model.predict(pad_new))
if(score > 0.5):
print("{:.2f}% 확률로 긍정 리뷰입니다.".format(score * 100))
else:
print("{:.2f}% 확률로 부정 리뷰입니다.".format((1 - score) * 100))
5)Tagging
=>개체명 인식기와 품사 태거를 만드는 경우가 있는데 이 작업이 Tagging
이 경우는 RNN의 many-to-many 모델이고 BidirectionalRNN을 이용
하나의 문장은 여러 개의 단어로 구성이 되고 입력은 sequence 이고 품사 태깅의 경우 각 단어에 품사를 제공해야 하기 때문에 sequence가 됩니다
요즘은 직접 태깅하는 경우는 별로 없습니다
6)Subword Tokenizer
=>OOV
-기계가 학습하지 못한 단어
=>Subword Tokenizer
- OOV 문제가 발생하면 자연어처리가 어려워짐
- 하나의 단어를 더 작은 단위의 의미있는 여러 서브 워드들의 분리시키는 것
-어떤 단어들은 분리가 가능하기 때문: ex.)의류창고 -> 의류 + 창고, 전기세 - >전기 세
-희귀 단어 나 신조어 그리고 단어의 합성 등의 문제를 해결할 수 있습니다
=>Byte Pair Encoding
-데이터 압축 알고리즘으로 출발했지만 최근에는 자연어 처리의 서브 워드 분리 알고리즘으로 응용
ex.)aaabdaaabac 를 압축
기본적으로 연속적으로 가장 많이 등장한 글자의 쌍을 찾아서 하나의 글자로 병합
여기서는 글자라는 단어 대신에 byte 라는 단어를 사용
'aa'라는 단어와 'ab'라는 단어가 연속적으로 2번씩 등장
'aa'를 대문자 Z로 'ab'라는 단어를 Y로 치환
ZYdZYac 로 변경
보면 'ZY'도 2번 등장
'ZY'를 X로 치환
XdXac로 변경
-자연어처리에서는 모든 단어를 글자 단위로 분할해서 수행
등장한 단어가 low:5,. lower:2. newest:6, widest:3
각 글자 단위로 분할: l o w e r n s t i d 로 분할
의류창고 물류창고 음류 창고
창고, 류창고, 이런식으로 겹치는 단어를 만들어나감
'Study > Deep learning' 카테고리의 다른 글
| Deep Learning(8)-Pytorch (0) | 2024.03.26 |
|---|---|
| DeepLearning(7)- AutoEncoder,생성모델 (0) | 2024.03.26 |
| Deep Learning(5)-RNN (0) | 2024.03.22 |
| Deep learning(4) - CNN (0) | 2024.03.21 |
| Deep Learning(3) - Optimizer 와 activation함수 알아보기 (0) | 2024.03.20 |



