1.Auto Encoder & GAN
1)Auto Encoder
=>어떤 지도 없이도 (레이블이 없는 형태) 잠재 표현을 학습할 수 있는 인공 지능
=>입력보다 낮은 차원을 가지기 때문에 차원 축소 또는 시각화에 유용
=>일부 오토 인코더는 훈련 데이터와 매우 비슷한 새로운 데이터를 생성할 수 있는데 이를 생성 모델이라고 하면 얼굴 사진으로 오토 인코더를 훈련하면 새로운 얼굴을 생성할 수 있지만 생성된 이미지가 흐릿하고 실제 이미지 같지 않음
2)GAN(Generative Adversarial Networks - GAN: 생성적 적대 신경망)
=>비지도 학습에 사용되는 인공지능 알고리즘으로 제로섬 게임 틀 안에서 서로 경쟁하는 두 개의 신경 네트워크 시스템에 의해 구현
=>Style GN 이라는 최신 GAN 구조를 이용해서 얼굴 이미지 나 에어 비앤비의 침실을 생성한 이미지 등을 만든 것을 볼 수 있음
3)Auto Encoder 와 GAN 차이
=> Auto Encoder 는 단순히 입력을 출력으로 복사하는 방법을 학습하는데 다양한 방법으로 네트워크에 제약을 가해 이 작업을 오히려 어렵게 만드는데 잠재 표현의 크기를 제한하거나 입력에 잡음을 추가하고 원본 입력을 복원하도록 네트워크를 훈련할 수 있는데 이런 제약은 오토 인코더가 단순히 입력을 출력으로 바로 복사하지 못하도록 막고 데이터를 효율적으로 표현하는 방법을 배우게 만드는 것
=>GAN은 생성자와 판별자를 만들어서 생성자가 만든 데이터를 판별자가 판별을 해서 가짜 데이터가 아닌것으로 판정할 때 까지 게속 학습을 하는 구조
4)효율적인 데이터 표현
40,27,25,6
100,98,96,94,...,0 이게 위의 방식보다 데이터의 표현을 암기하는 것이 더 효율적
=>데이터를 전부 기억하는 것이 아니고 데이터의 패턴을 기억하는 것이 효율적
=>Auto Encoder 는 입력을 받아서 효율적인 내부 표현으로 바꾸고 입력과 가장 가까운 어떤 것을 출력하는 것
=>Auto Encoder는 항상 두 분으로 구성되는데 입력을 내부 표현으로 변경하는 Encoder(Recognition Network) 와 내부 표현을 출력으로 변경하는 Decoder(Generative Network)라고 함
=>보통의 오토 인코더는 출력 층의 뉴런 개수가 입력 개수와 동일한 다중 퍼셉트론
=>입력 층의 개수와 출력 층의 개수가 다르면 입력을 단순하게 코딩으로 복사할수 없기 떄문에 이런 경우에는 입력 데이터에서 가중 중요한 특성을 학습해서 중요하지 않은 것을 버리게 됩니다.
이 경우는 차원 축소와 유사하게 동작합니다.
5)오토 인코더를 이용해서 PCA를 수행
=>데이터 생성
np.random.seed(42)
def generate_3d_data(m, w1=0.1, w2=0.3, noise=0.1):
angles = np.random.rand(m) * 3 * np.pi / 2 - 0.5
data = np.empty((m, 3))
data[:, 0] = np.cos(angles) + np.sin(angles)/2 + noise * np.random.randn(m) / 2
data[:, 1] = np.sin(angles) * 0.7 + noise * np.random.randn(m) / 2
data[:, 2] = data[:, 0] * w1 + data[:, 1] * w2 + noise * np.random.randn(m)
return data
X_train = generate_3d_data(60)
X_train = X_train - X_train.mean(axis=0, keepdims=0)=>모델 생성 및 훈련
#모델 생성
np.random.seed(42)
tf.random.set_seed(42)
#입력 데이터 학습할 수 있는 Encoder 생성
encoder = keras.models.Sequential([keras.layers.Dense(2, input_shape=[3])])
#학습된 내용을 출력으로 변경하는 Decoder 생성
#Decoder 는 인코더의 입력 개수와 출력개수가 동일해야함
decoder = keras.models.Sequential([keras.layers.Dense(3, input_shape=[2])])
#오토 인코더는 Encoder 와 Decoder 가 합쳐져서 생성
autoencoder = keras.models.Sequential([encoder, decoder])
#PCA을 수행하고자 할 떄는 activation_function을 사용하지 않고 cost_func 은 MSE
autoencoder.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1.5))
#모델 훈련
#비지도 학습이라서 별도의 레이블 없이 자기 자신을 레이블로 설정
history = autoencoder.fit(X_train, X_train, epochs=20)
codings = encoder.predict(X_train)
=>3차원 그래프 출력
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# X_train 데이터의 각 열은 각각 x, y, z 좌표에 해당합니다.
x = X_train[:, 0]
y = X_train[:, 1]
z = X_train[:, 2]
# 3D 그래프 생성
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 데이터 포인트 그리기
ax.scatter(x, y, z)
# 각 축의 레이블 지정
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
# 그래프 출력
plt.show()
=>결과 출력
fig = plt.figure(figsize=(4,3))
plt.plot(codings[:,0], codings[:, 1], "b.")
plt.xlabel("$z_1$", fontsize=18)
plt.ylabel("$z_2$", fontsize=18, rotation=0)
plt.grid(True)
save_fig("linear_autoencoder_pca_plot")
plt.show()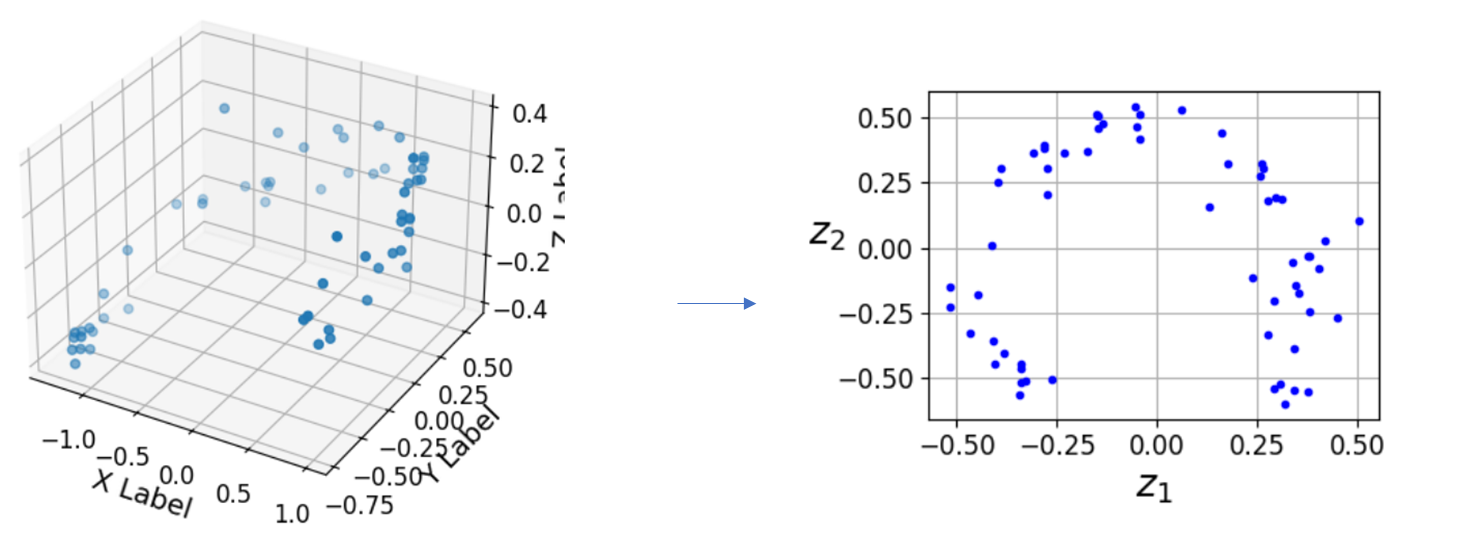
6)적층 오토 인코더

=>은닉층을 여러개 갖는 오토 인코더
=>stacked auto encoder 또는 deep auto encoder 라고도 합니다
=>층을 여러개 쌓으면 인코더가 조금 더 복잡한 패턴을 학습할 수 있지만 훈련 데이터를 완벽하게 재구성 할 수 있지만 새로운 샘플에 잘 일반화되지 않을 수 있음
=>이 경우 샌드위치를 구조로 가짐
Encoder 와 Decoder 가 순서대로 쌓여있는 형태로 생성
=>Fashion MNIST 데이터셋에 SELU 함수를 이용해서 적층 오토 인코더 생성
=>데이터 생성
(X_train_full, y_train_full), (X_test, y_test) = keras.datasets.fashion_mnist.load_data()
X_train_full = X_train_full.astype(np.float32) / 255
X_test = X_test.astype(np.float32) / 255
X_train, X_valid = X_train_full[:-5000], X_train_full[-5000:]
y_train, y_valid = y_train_full[:-5000], y_train_full[-5000:]
=>모델 생성
def rounded_accuracy(y_true, y_pred):
return keras.metrics.binary_accuracy(tf.round(y_true), tf.round(y_pred))
tf.random.set_seed(42)
np.random.seed(42)
stacked_encoder = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(100, activation="selu"), #hidden layer
keras.layers.Dense(30, activation="selu"),#hidden layer
])
stacked_decoder = keras.models.Sequential([
keras.layers.Dense(100, activation="selu", input_shape=[30]),
keras.layers.Dense(28 * 28, activation="sigmoid"),#이미지가 일차원 출력
keras.layers.Reshape([28, 28])#일차원 데이터 2차원으로 복원
])=>모델 훈련
stacked_ae = keras.models.Sequential([stacked_encoder, stacked_decoder])
#손실함수는 binary_crossentropy(이진분류에 이용)
#적층 인코더 부터는 이진 판별 문제(생성을 하고 난 후 확인해서 진짜 가짜 판별)
stacked_ae.compile(loss="binary_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=1.5), metrics=[rounded_accuracy])
history = stacked_ae.fit(X_train, X_train, epochs=20,
validation_data=(X_valid, X_valid))
=>예측하고 이미지 확인
#예측하고 이미지 확인
#흑백 이미지 출력
def plot_image(image):
plt.imshow(image,cmap='binary')
plt.axis('off')
#샘플 데이터 받아서 출력하고 출력된 데이터를 다시 화면에 그려주는 함수
#모델과 이미지와 개수를 매개변수로 받아서 수행
def show_reconstructions(model, images=X_valid, n_images=5):
#이미지 예측
reconstructions = model.predict(images[:n_images])
fig = plt.figure(figsize=(n_images * 1.5, 3))
for image_index in range(n_images):
#원래 이미지
plt.subplot(2, n_images, 1 + image_index)
plot_image(images[image_index])
#예측한 이미지
plt.subplot(2, n_images, 1 + n_images + image_index)
plot_image(reconstructions[image_index])
show_reconstructions(stacked_ae)
save_fig("reconstruction_plot")
=>결과
-원본 이미지에 비해서 많은 정보를 잃어버린 것 같음
-모델을 더 많이 훈련하거나 인코더와 디코더 층을 늘리거나 마지막 코딩의 크기를 늘리면 더 많이 복원이 가능하지만 유익한 패턴을 학습하지 못한 상태에서 완벽한 재구성 이미지를 만들 수 있음
=>활용
-차원 축소 차원에서만 보면 다른 차원 축소 알고리즘에 비해서 좋은 결과를 만들지 못하지만 샘플과 특성이 많은 대용량 데이터 셋을 다룰 수 있기 때문에 오토인코더를 통해서 적절한 수준으로 차원을 축소한 후 다른 차원 축소 알고리즘을 이용하면 더 뛰어난 차원 축소 효과를 볼 수 있음
현재는 30개의 특성으로 차원을 줄인 상태
=>30개의 특성으로 축소된 이미지를 tSNE 알고리즘을 이용해서 차원 축소를 수행한 후 시각화
#줄어든 특성을 이용한 시각화
np.random.seed(42)
from sklearn.manifold import TSNE
#차원 축소: 28*28 차원의 이미지를 30개의 차원으로 줄임
#군집을 수행하고 난 후 cmap에 색상 값을 이용해서 어느 군집이 비슷한지 확인 가능
X_valid_compressed = stacked_encoder.predict(X_valid)
tsne = TSNE()
X_valid_2D = tsne.fit_transform(X_valid_compressed)
#min_max_scaling
X_valid_2D = (X_valid_2D - X_valid_2D.min()) / (X_valid_2D.max() - X_valid_2D.min())
plt.scatter(X_valid_2D[:, 0], X_valid_2D[:, 1], c=y_valid, s=10, cmap="tab10")
plt.axis("off")
plt.show()
=>Fashion MNIST 데이터 셋에서 색상의 원래 이미지를 출
plt.figure(figsize=(10, 8))
cmap = plt.cm.tab10
plt.scatter(X_valid_2D[:, 0], X_valid_2D[:, 1], c=y_valid, s=10, cmap=cmap)
#점들 위에 이미지 출력
image_positions = np.array([[1., 1.]])
for index, position in enumerate(X_valid_2D):
#각 점과 이미지 위치 값을 계산
dist = np.sum((position - image_positions) ** 2, axis=1)
#이미지 분류할 때 또는 일반 분류더라도 이미지가 있는 경우라면
#이런 형태로 출력해주면 설명력이 높음
#어디서 오류가 많이 발생할 지도 예측이 가능해집니다
if np.min(dist) > 0.02: # 다른 이미지와 거리가 0.02 정도 멀다면
image_positions = np.r_[image_positions, [position]]
imagebox = mpl.offsetbox.AnnotationBbox(
mpl.offsetbox.OffsetImage(X_valid[index], cmap="binary"),
position, bboxprops={"edgecolor": cmap(y_valid[index]), "lw": 2})#박스로 이미지 출력
plt.gca().add_artist(imagebox)
plt.axis("off")
save_fig("fashion_mnist_visualization_plot")
plt.show()
차원 축소가 이렇게 데이터를 설명하기 위한 목적으로 사용되는 경우가 많아서 시각화가 목적이라고 합니다
=>가중치 묶기
- 인코더 와 디코더의 모양이 완전히 대칭이라면 디코더의 가중치와 인코더의 가중치를 묶는 것이 일반적인데 이렇게 하면 가중치의 수를 절반으로 줄여서 훈련 속도는 높이고 과대 적합의 가능성을 줄일 수 있음
-구현 할 때는 사용자 정의 클래스를 만들어서 사용
class DenseTranspose(keras.layers.Layer):
def __init__(self, dense, activation=None, **kwargs):
self.dense = dense
self.activation = keras.activations.get(activation)
super().__init__(**kwargs)
def build(self, batch_input_shape):
self.biases = self.add_weight(name="bias",
shape=[self.dense.input_shape[-1]],
initializer="zeros")
super().build(batch_input_shape)
def call(self, inputs):
z = tf.matmul(inputs, self.dense.weights[0], transpose_b=True)
return self.activation(z + self.biases)사용자 정의 층은 일반적인 Dense층과 비슷하지만 다른 Dense 층의 전치된 가중치를 사용
- transpose_b = True 로 지정하는 것이 두번째 매개변수를 전치하는 것과 동일 하지만 matmul() 연산에서 동적으로 전치 수행하는게 훨씬 효율적
keras.backend.clear_session()
tf.random.set_seed(42)
np.random.seed(42)
dense_1 = keras.layers.Dense(100, activation="selu")
dense_2 = keras.layers.Dense(30, activation="selu")
tied_encoder = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
dense_1,
dense_2
])
tied_decoder = keras.models.Sequential([
DenseTranspose(dense_2, activation="selu"),
DenseTranspose(dense_1, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
=>한 번에 오토 인코더 1개씩 훈련
-최근에는 잘 사용하지 않는 방법인데 한번에 전체 오토 인코더를 훈련하는 대신 오토 인코더 하나를 훈련하고 이를 쌓아 올려서 한개의 적층 오토 인코더를 만드는 방식
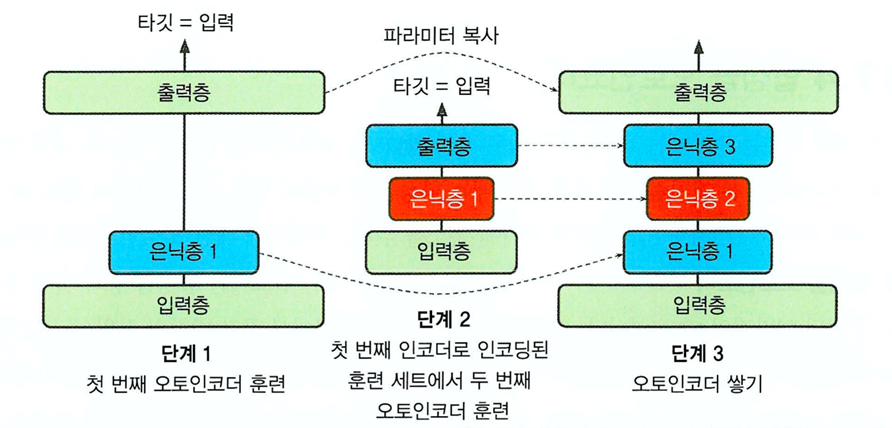
7)합성곱 오토 인코더(Convolutional auto encoder)
=>오토 인코더에서 Dense 대신에 Convolutional2D를 활용함.
=>이미지를 다룰 때 주로 사용
=>인코더를 만들 때는 합성곱 층과 폴링 층으로 구성된 CNN이고 디코더는 반대로 동작
=>이미지를 다룰때는 합성곱 신경망이 밀집 네트워크 보다 훨씬 잘 맞는데 비지도 사전 훈련이나 차원 축소를 위해 이미지에 대한 오토 인코더를 만들려면 합성곱 오토 인코더를 만들어야함
=>모델 생성
tf.random.set_seed(42)
np.random.seed(42)
conv_encoder = keras.models.Sequential([
keras.layers.Reshape([28, 28, 1], input_shape=[28, 28]),
keras.layers.Conv2D(16, kernel_size=3, padding="SAME", activation="selu"),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Conv2D(32, kernel_size=3, padding="SAME", activation="selu"),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Conv2D(64, kernel_size=3, padding="SAME", activation="selu"),
keras.layers.MaxPool2D(pool_size=2)
])
#Encoder 에서 마지막 output 개수가 Decoder input 개수
#Encoder 에서 마지막 출력한 데이터의 shape 가 Decoder 의 입력층 shape
conv_decoder = keras.models.Sequential([
keras.layers.Conv2DTranspose(32, kernel_size=3, strides=2, padding="VALID", activation="selu",
input_shape=[3, 3, 64]),
keras.layers.Conv2DTranspose(16, kernel_size=3, strides=2, padding="SAME", activation="selu"),
keras.layers.Conv2DTranspose(1, kernel_size=3, strides=2, padding="SAME", activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
conv_ae = keras.models.Sequential([conv_encoder, conv_decoder])
conv_ae.compile(loss="binary_crossentropy", optimizer=keras.optimizers.SGD(lr=1.0),
metrics=[rounded_accuracy])
history = conv_ae.fit(X_train, X_train, epochs=20,
validation_data=(X_valid, X_valid))
8)순환 오토 인코더(recurrent auto encoder)
=>시계열 데이터의 오토 인코더를 만들고자 하는 경우에는 Conv2D 보다는 RNN 이 더 좋은 성능을 발휘
=>일반적으로 입력 시퀀스를 하나의 벡터로 압축하는 sequence-to-vector RNN이면 디코더는 vector - to - sequence RNN
9)잡음 제거 오토인코더
=>오토 인코더가 유용한 특성을 학습하도록 강제하는 다른 방법은 입력에 잡음 추가하는 것
=>잡음을 추가하면 주성분 분석을 하는게 성능이 좋았을 때가 많음
=>잡음이 없는 원본 입력을 복원하도록 하는 것인데 이를 이용해서 오토 인코더를 특성 추출기로 사용할 수 있음
=>잡음은 입력에 추가된 순수한 Gaussian 잡음이거나 드롭아웃처럼 무작위로 입력을 제거해서 발생시킬 수 있음
#가우시안 잡음 추가
tf.random.set_seed(42)
np.random.seed(42)
denoising_encoder = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.GaussianNoise(0.2),
keras.layers.Dense(100, activation="selu"),
keras.layers.Dense(30, activation="selu")
])
denoising_decoder = keras.models.Sequential([
keras.layers.Dense(100, activation="selu", input_shape=[30]),
keras.layers.Dense(28 * 28, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
denoising_ae = keras.models.Sequential([denoising_encoder, denoising_decoder])
denoising_ae.compile(loss="binary_crossentropy", optimizer=keras.optimizers.SGD(lr=1.0),
metrics=[rounded_accuracy])
history = denoising_ae.fit(X_train, X_train, epochs=10,
validation_data=(X_valid, X_valid))
#dropout 추가
tf.random.set_seed(42)
np.random.seed(42)
dropout_encoder = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dropout(0.5),
keras.layers.Dense(100, activation="selu"),
keras.layers.Dense(30, activation="selu")
])
dropout_decoder = keras.models.Sequential([
keras.layers.Dense(100, activation="selu", input_shape=[30]),
keras.layers.Dense(28 * 28, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
dropout_ae = keras.models.Sequential([dropout_encoder, dropout_decoder])
dropout_ae.compile(loss="binary_crossentropy", optimizer=keras.optimizers.SGD(lr=1.0),
metrics=[rounded_accuracy])
history = dropout_ae.fit(X_train, X_train, epochs=10,
validation_data=(X_valid, X_valid))

10)희소 오토 인코더
=>좋은 특성을 추출하도록 만드는 다른 제약의 방식은 희소(sparsity)
=>오토 인코더가 코딩 층에서 활성화되는 뉴런 수를 감소시키는 방법
인코더에서 출력할 때 활성화 함수는 sigmoid 로 변경
출력되는 값이 0 에서 1사이의 값으로 제한
=>L1 규제를 추가함
tf.random.set_seed(42)
np.random.seed(42)
simple_encoder = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(100, activation="selu"),
keras.layers.Dense(30, activation="sigmoid"),
])
simple_decoder = keras.models.Sequential([
keras.layers.Dense(100, activation="selu", input_shape=[30]),
keras.layers.Dense(28 * 28, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
simple_ae = keras.models.Sequential([simple_encoder, simple_decoder])
simple_ae.compile(loss="binary_crossentropy", optimizer=keras.optimizers.SGD(lr=1.),
metrics=[rounded_accuracy])
history = simple_ae.fit(X_train, X_train, epochs=10,
validation_data=(X_valid, X_valid))
11)VAE(Variational Auto Encoder - 변이형 오토 인코더)

=>확률적 오토 인코더 : 훈련이 끝난 후 출력도 우연에 의해 결정
Dropout을 쓰면 입력이 우연에 의해서 결정되었음
인코더는 출력으로 평균과 표준편차를 생성하고 실제 코딩은 평균 과 표준 편차를 이용해서 가우시안 분포에서 랜덤하게 샘플링 됨
2.GAN
1)개요
=>GAN(Generative Adverarial Network)은 생성적 적대 신경망이라고 번역
=>Generator(생성자)가 학습에 필요한 데이터를 만들어내고 이 데이터가 Discriminantor(판별자)를 속이기 위한 가짜이기 때문에 적대적 신경망이라고 합니다.
Generator(생성자)의 목적은 자신이 만든 데이터를 Discriminator 가 진짜라고 판단하도록 만드는 것
=>두번쨰 단계에서는 생성자 훈련하는데 생성자를 이용해서 가짜 이미지 배치를 만들고 다시 판별자를 이용해서 이미지가 진짜인지 가짜인지를 판별하는데 이번에는 진짜 이미지를 추가하지 않고 레이블을 모두 1로 세팅해서 생성자가 판별자가 진짜라고 믿는 이미지를 만들어 내는 것이 목표이며 판별자의 가중치를 동결하고 역전파는 생성자의 가중치에만 영향을 미침
3)발전 과정
=>Dense 층을 이용했다가 나중에는 Conv2D 계층을 이용한 심층 합성곱 GAN(DCGAN)으로 발전함
4)훈련 과정을 녹화할 수 있음
5)심층 합성곱을 이용해서 스타일 변환이가능
=>여러개의 이미지에서 특성을 추출해서 이미지를 합성하는 것
6)실습
#GAN 모델 생성
np.random.seed(42)
tf.random.set_seed(42)
codings_size = 30
generator = keras.models.Sequential([
keras.layers.Dense(100, activation="selu", input_shape=[codings_size]),
keras.layers.Dense(150, activation="selu"),
keras.layers.Dense(28 * 28, activation="sigmoid"),
keras.layers.Reshape([28, 28])
])
discriminator = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(150, activation="selu"),
keras.layers.Dense(100, activation="selu"),
keras.layers.Dense(1, activation="sigmoid")
])
gan = keras.models.Sequential([generator, discriminator])
=>모델 컴파일 (discriminator.trainable=False로 반드시 설정해야함)
#모델 컴파일
discriminator.compile(loss="binary_crossentropy", optimizer="rmsprop")
discriminator.trainable = False
gan.compile(loss="binary_crossentropy", optimizer="rmsprop")
=>모델 학습
#일반적인 훈련이 아니라서 fit 을 못씀
batch_size = 32
dataset = tf.data.Dataset.from_tensor_slices(X_train).shuffle(1000)
dataset = dataset.batch(batch_size, drop_remainder=True).prefetch(1)#모델 훈련
def train_gan(gan, dataset, batch_size, codings_size, n_epochs=50):
generator, discriminator = gan.layers
for epoch in range(n_epochs):
print("Epoch {}/{}".format(epoch + 1, n_epochs))
for X_batch in dataset:
# phase 1 - training the discriminator
noise = tf.random.normal(shape=[batch_size, codings_size])
generated_images = generator(noise)
X_fake_and_real = tf.concat([generated_images, X_batch], axis=0)
y1 = tf.constant([[0.]] * batch_size + [[1.]] * batch_size)
discriminator.trainable = True
discriminator.train_on_batch(X_fake_and_real, y1)
# phase 2 - training the generator
noise = tf.random.normal(shape=[batch_size, codings_size])
y2 = tf.constant([[1.]] * batch_size)
discriminator.trainable = False
gan.train_on_batch(noise, y2)
plot_multiple_images(generated_images, 8)
plt.show()잡음을 섞는 이미지를 discriminator 를 우선 학습 시키고 generator는 새로운 데이터셋을 만들어냄
근데 이를 하다 보면 모델 붕괴 현상이 발생 => 합성곱 GAN을 활용하기 시작함
=>DCGAN 모델 생성
#DCGAN 모델 생성
tf.random.set_seed(42)
np.random.seed(42)
codings_size = 100
generator = keras.models.Sequential([
keras.layers.Dense(7 * 7 * 128, input_shape=[codings_size]),
keras.layers.Reshape([7, 7, 128]),
keras.layers.BatchNormalization(),
keras.layers.Conv2DTranspose(64, kernel_size=5, strides=2, padding="SAME",
activation="selu"),
keras.layers.BatchNormalization(),
keras.layers.Conv2DTranspose(1, kernel_size=5, strides=2, padding="SAME",
activation="tanh"),
])
discriminator = keras.models.Sequential([
keras.layers.Conv2D(64, kernel_size=5, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2),
input_shape=[28, 28, 1]),
keras.layers.Dropout(0.4),
keras.layers.Conv2D(128, kernel_size=5, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2)),
keras.layers.Dropout(0.4),
keras.layers.Flatten(),
keras.layers.Dense(1, activation="sigmoid")
])
gan = keras.models.Sequential([generator, discriminator])
=>모델 컴파일
discriminator.compile(loss="binary_crossentropy", optimizer="rmsprop")
discriminator.trainable = False
gan.compile(loss="binary_crossentropy", optimizer="rmsprop")=>모델 훈련
batch_size = 32
dataset = tf.data.Dataset.from_tensor_slices(X_train_dcgan)
dataset = dataset.shuffle(1000)
dataset = dataset.batch(batch_size, drop_remainder=True).prefetch(1)
train_gan(gan, dataset, batch_size, codings_size)

생성형 AI 나 자연어 처리 및 Attention,Transformer 를 실습할 떄는 시간이 매우 오래 걸리기 때문에 GPU 탑재된 컴퓨터나 colab 을 유료로 결제해서 GPU나 TPU를 사용해야 하고 메모리를 늘려야 합니다.
'Study > Deep learning' 카테고리의 다른 글
| Deep learning(9)-LLM (0) | 2024.03.26 |
|---|---|
| Deep Learning(8)-Pytorch (0) | 2024.03.26 |
| Deep learning(6) - 자연어처리 (1) | 2024.03.25 |
| Deep Learning(5)-RNN (0) | 2024.03.22 |
| Deep learning(4) - CNN (0) | 2024.03.21 |



