**기본적인 그래프
1.주제에 적합한 시각화 방법
1)시간의 흐름에 따른 추세 확인
=>숫자가 전체적으로 올라가는 추세인지 또는 특정 기간에 이벤트의 효과가 실제로 있었는지 수치가 나빠지면 언제부터 그런 현상이 발생했는지를 시간 순서에 따라서 살펴보는 것
=>이 경우엥는 라인 이나 영역 또는 막대 차트등을 많이 이용
=>라인차트
태블로에서는 날짜 및 시간 유형의 필드를 활용하면 기본적으로 라인차트가 만들어집니다..
라인 차트를 만들 떄는 날짜관련 필드는 행 선반 다는 열 선반에 배치하는 것이 좋은데 시간 별 추세를 볼 때 사람의 시선은 왼쪽에서 출발해서 오른쪽으로 이동하는데 익숙해져 있기 때문
시트에서 날짜 유형의 필드를 더블 클릭하면 기본적으로 열 선반에 배치가 됩니다.
단순한 시간에 따른 추세 뿐만 아니라 다른 항목과의 상관관계를 살펴볼때도 도움이 됩니다.
이런 경우에는 하나의 영역에 2개잉상의 라인을 같이 그리기도하고 나누어서 그리기도 합니다.
=>영역 차트
영역 차트는 라인 그래프와 비슷하지만 값이 여러 개일 경우 영역이 누적되어서 나타나므로 누적해서 볼 것인지 아니면 개별적으로 볼 것인지 여부에 따라 달라집니다.
=>막대 차트
막대 차트는 추세를 반영하면서도 각각을 분리해서 화면을 개별적으로 구성하는데 적합
라인차트와 같이 그려서 추세를 별도로 볼 수 있도록 구성하는 경우가 많습니다.
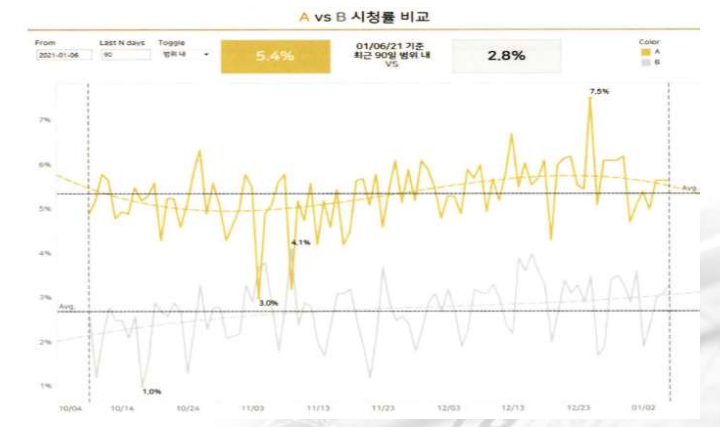
2)순위 기반 비교
=>정렬을 수행하는 것이 좋습니다
=>막대나 라인차트, 텍스트
3)상관관계 표현
=>측정값 2개를 비교해서 의미있는 분석을 할때 사용하는 기법으로 분산형 차트를 주로 이용
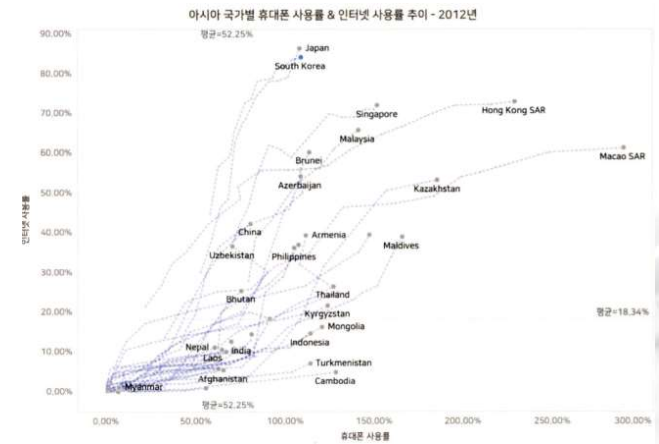
실제로 비교할때는 비슷한 그룹끼리 정리해야됨. 위의 그래프에서 인구수를 고려해야됨.
4)기여도-전체에서 차지하는 비율
=>파이차트 나 누적막대 차트, 트리맵등을 주로 이용
5)구간 차원
=>특정 구간에 어느정도의 데이터가 분포하는지 확인하기 위한 것으로 히스토그램이나 히스토그램의 변형등을 많이 이용

6)분포
7)지리적 데이터
=>태블로는 지도 기능을 제공하므로 지도 기능을 이용
2.데이터가져오기
=>데이터 불러오기
태블로안에도 조인역할 할 수 있음.
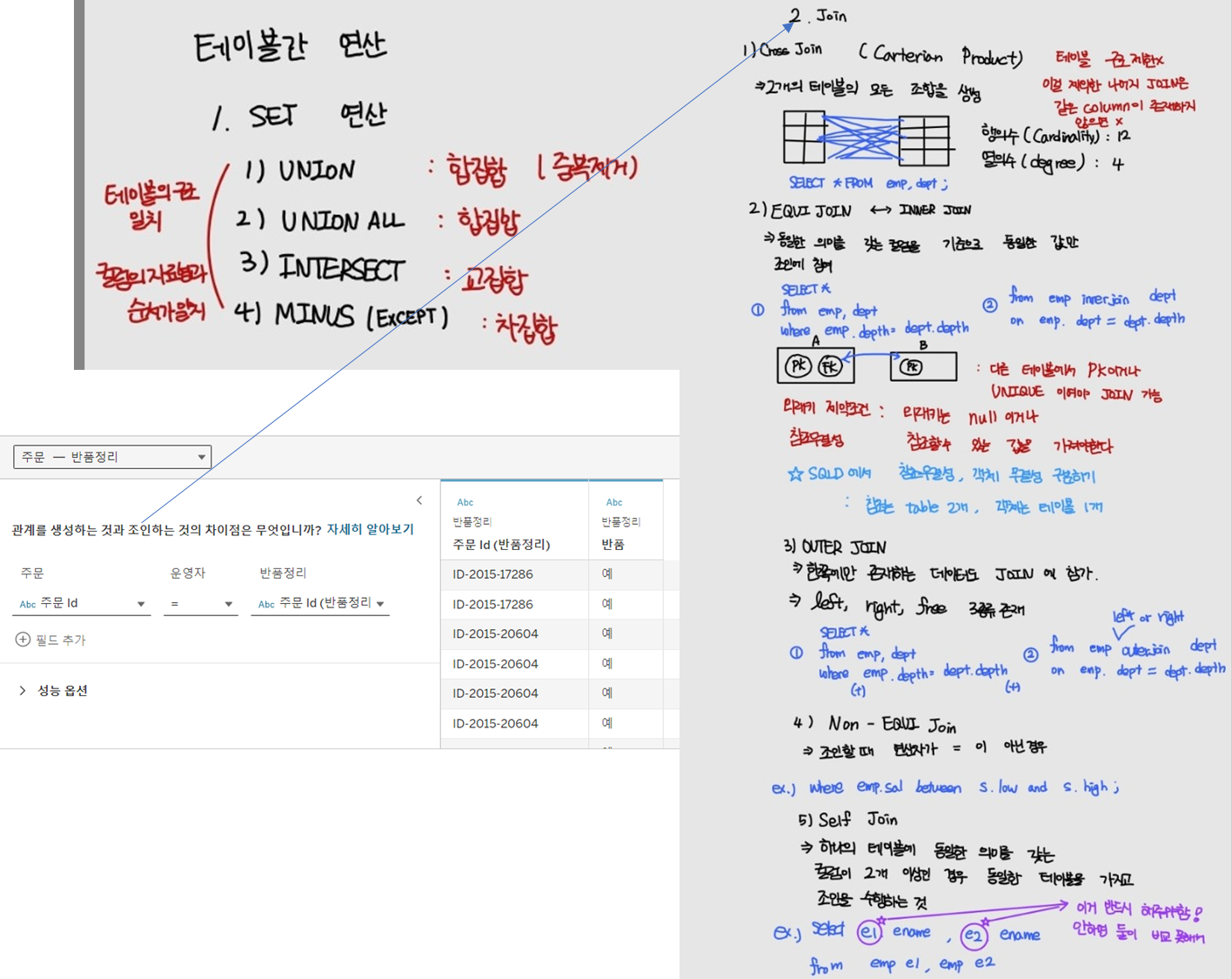
3.막대 그래프
1)개요
=>다양한 카테고리의 값을 쉽게 비교할 수 있는 방식으로 데이터 시각
2)그룹 막대 차트
=>기본 막대 차트에서 항목을 추가해서 여러 데이터를 함께 비교하기 위해서 사용
=>데이터의 컬럼이 여러 단계로 구분된 경우 많이 사용
=>대분류 안에 중분류를 추가해서 매출의 합계를 확인
[대분류]를 열 선반에 배치
[매출]을 행 선반에 배치
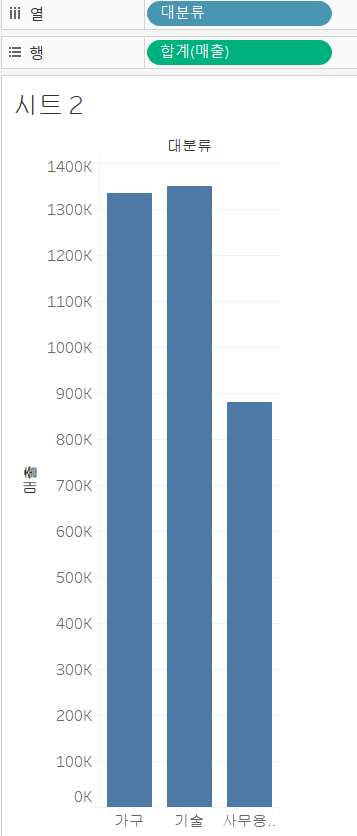
-[중분류]를 열 선반에 추가
대분류와 중분류를 가지고 그룹화해서 막대 그래프가 그려짐
서식을 활용해 맞춤에서 통화로 변경하게 되면 원화 표시가 나오게 됨.
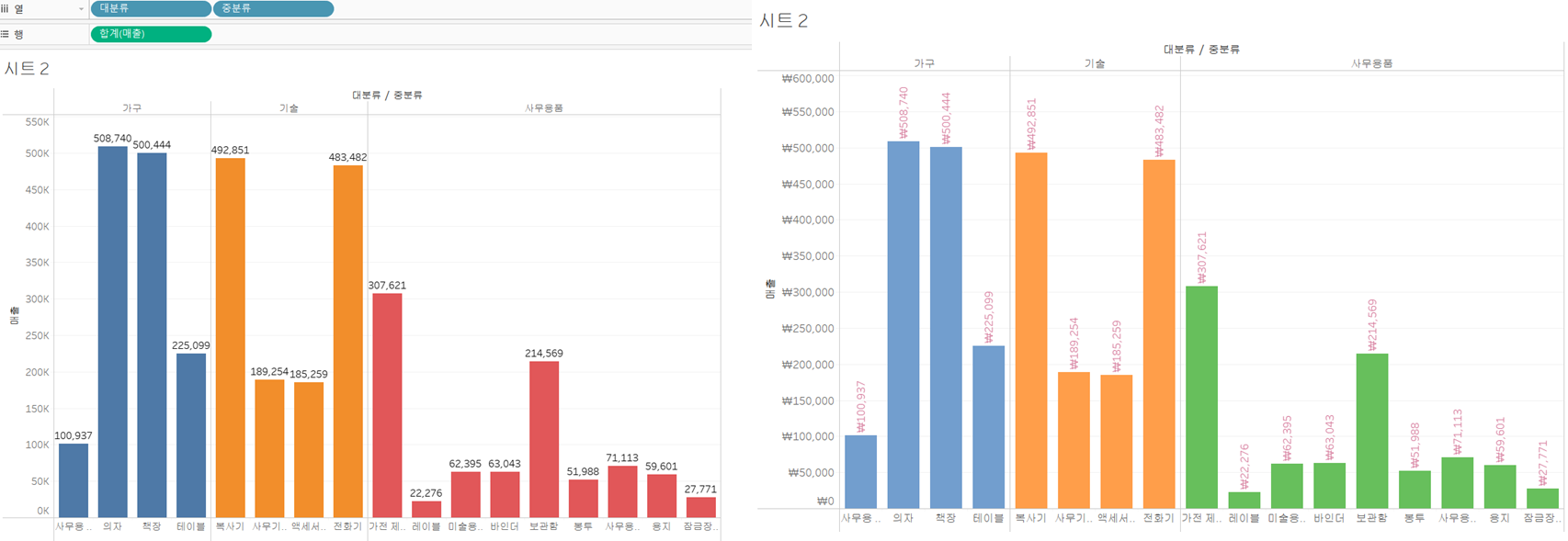
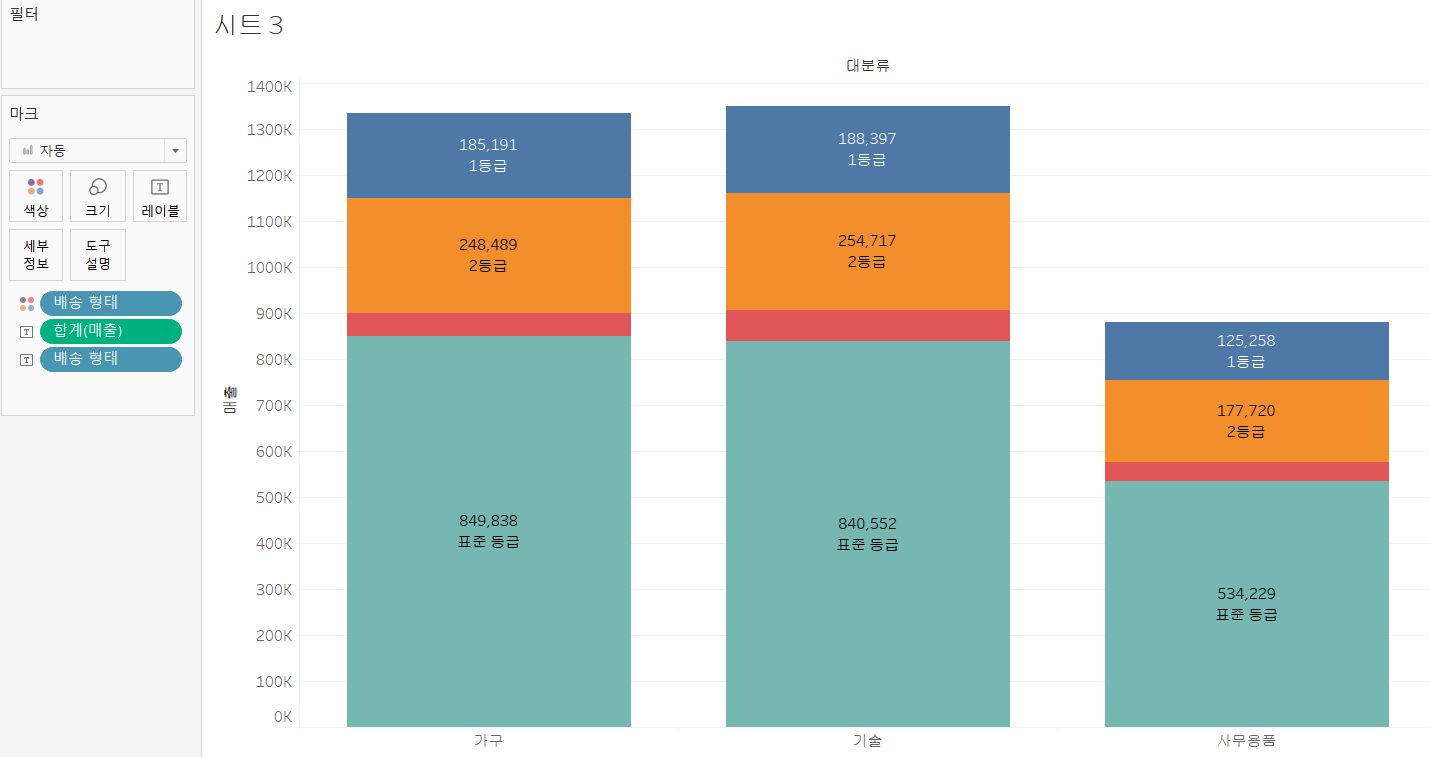
3) 누적 막대 차트
=>기본 막대 차트 구성 안에서 2가지 이상의 데이터의 기여도를 알고자 하는 경우 사용
=>그룹 막대 차트는 크기 비교는 가능한데 기여도를 한눈에 알아보기는 쉽지 않음
=>이같은 경우에는 레이블의 값을 출력해주는게 좋음,비슷한 애들이 있으면 한눈에 비교하기가 쉽지 않음
=>[대분류] 별 [배송형태]의 [매출]비율을 조회하기 위한 누적 막대 차트 생성
-[대분류]를 열 선반에 배치
-[매출]을 행 선반에 배치
-[매출]을 레이블에 배치해서 메츨값이 막대에 표시되도록 설정
-[배송형태]를 색상 카드에 배치해서 누적 막대를 생성
-누적 막대를 만들면 색상에 배치된 배송형태의 레이블이 출력되지 않으므로 [배송형테]를 레이블에 배치해서 배송형태의 레이블이 출력되도록 해주는 것이 좋습니다.
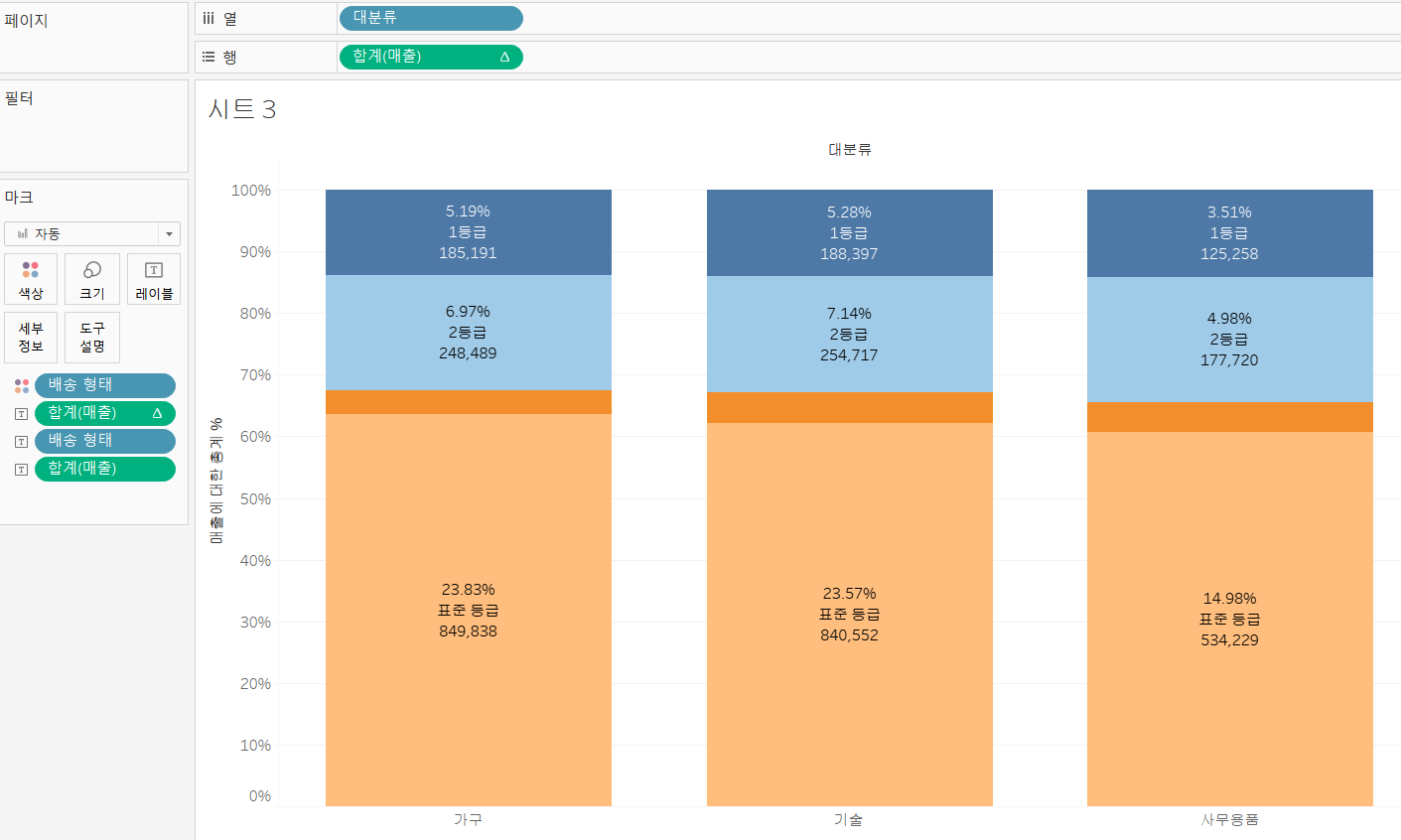
4)비율 막대 차트
=>누적 막대 차트를 만듦면 각 항목의 기여도를 확인할 때 값보다는 비율이 필요한 경우도 있습니다.
행 선반에 있는 [합계(매출)]의 추가 메뉴를 눌러서 [퀵 테이블 계산]-[구성 비율]을 선택하면 됩니다.
[합계(매출)]의 추가 메뉴를 눌러서 [다음을 사용하여 계산] -[테이블(아래로)]을 선택하면 됩니다.
행 선반에 존재하는 [합계(매출)]을 CTRL키를 누른채로 레이블로 배치해서 구성 비율이 화면에 출력되도록 합니다.
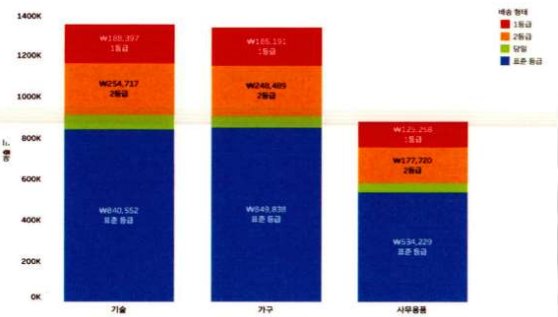
5)겹 막대 그래프
=>하나의 항목에 대한 값을 2개의 겹쳐지는 막대 그래프로 출력하는 것으로 하나의 항목에 대한 2개 데이터의 크기 비교를 하기 위해서인데 일반적으로 달성률 같은 것을 알아보고자 할때 사용합니다.
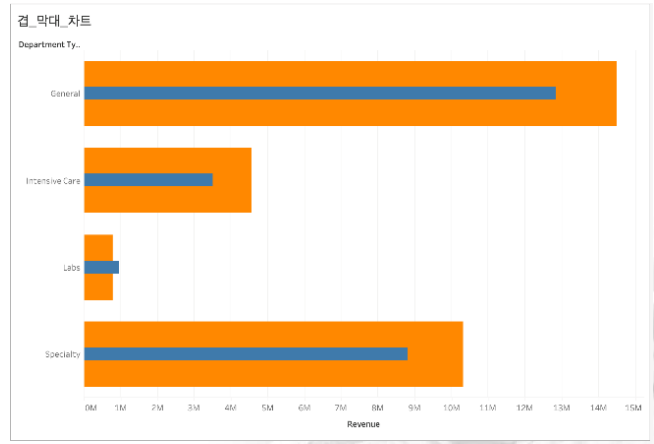
=>Hospital Visits.csv 파일의 데이터 새로 가져오기
[데이터]-[새 데이터 원본]
=>Department Type 별로 Revenue와 Date of Admit 데이터를 가지고 겹 막대 그래프 그리기
-Revenue를 열 선반에 배치
-Department Type을 행 선반에 배치
차원이 행에 위치하고 측정값이 열에 위치하면 기본적으로 가로 방향의 막대그래프가 그려집니다.
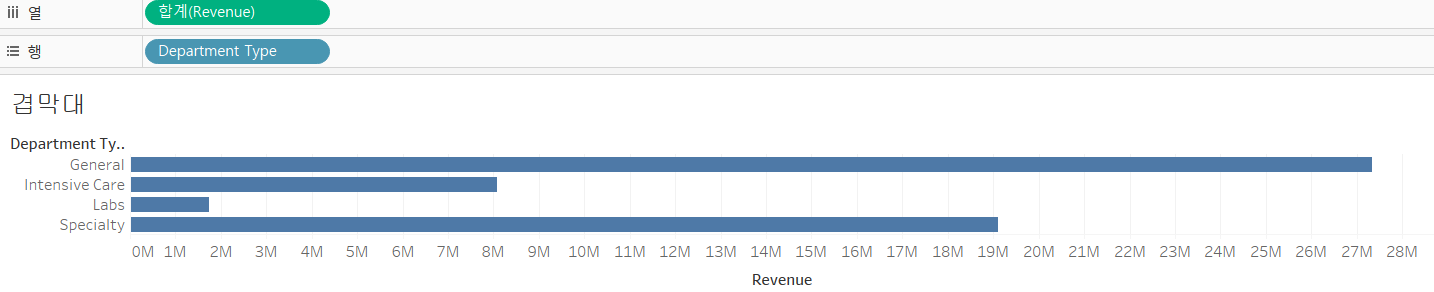
-Date Of Admit을 색상에 배치해서 누적 막대 그래프를 만듭니다.
-누적 막대 그래프에서 각 항목을 겹쳐서 표시하고자 하는 우 [분석] - [마크 누적] -[해제]를 선택하면 됩니다.
-앞에 색상에 배치한 Date of Admit 을 CTRL 키를 누른채 크기에 배치.
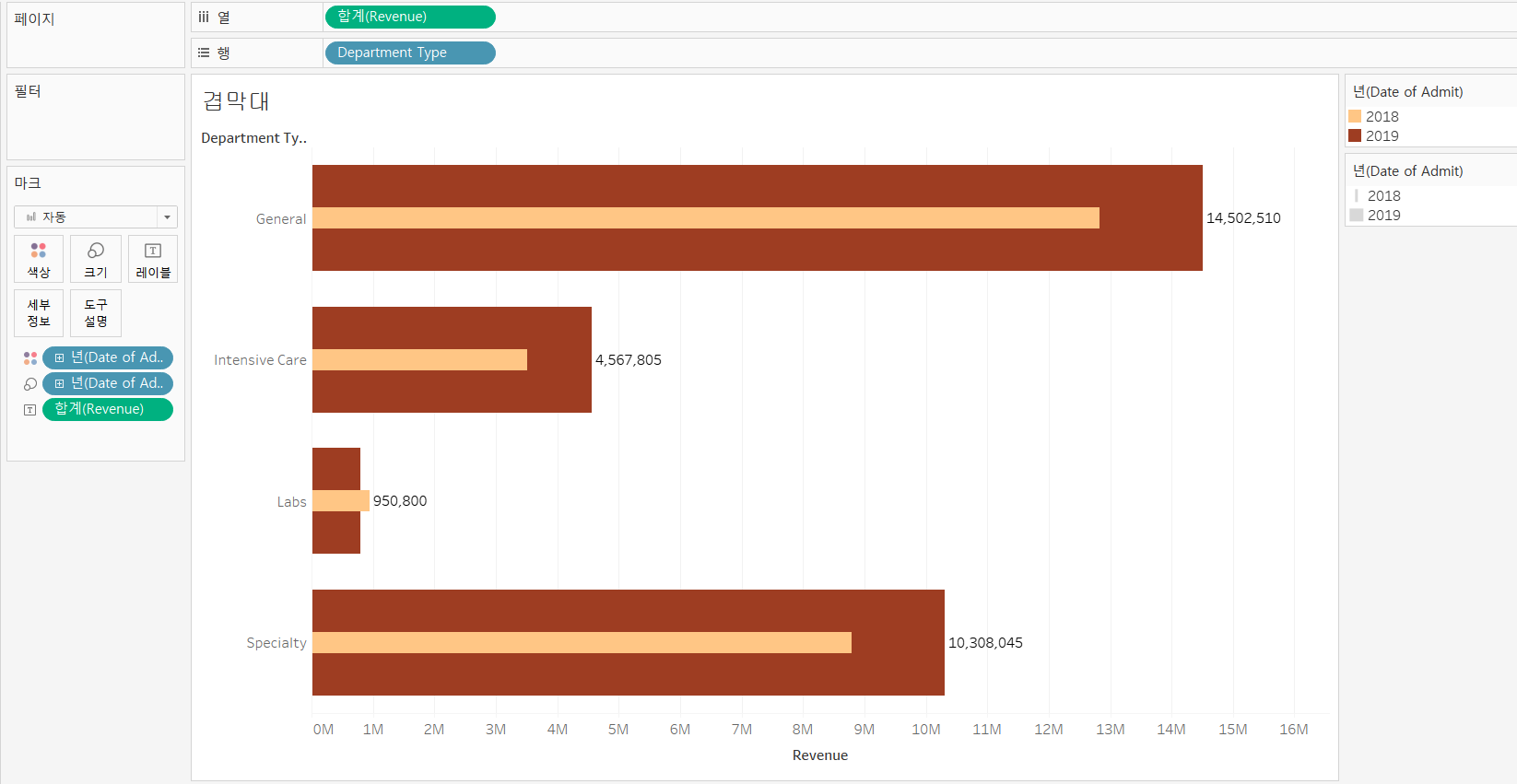
이러한 겹침 막대 그래프나 블릿 그래프는 달성률 같은 항목을 보고자 할 때 많이 사용
-막대 그래프에서 특정항목을 강조하고자 하는 경우에는 CTRL 키를 이용해서 항목들을 선택한 후 마우스 오른쪽을 눌러서 [그룹]을 선택하면 별도의 그룹이 만들어집니다.

4.라인 차트
1)개요
=>시계열 데이터를 시각화할때 많이 사용
=>라인 차트를 이용하면 데이터의 상승 또는 하락 같은 추세를 쉽게 파악할 수 있고 데이터의 특정 패턴을 발견할 수 있습니다.
패턴을 찾고자 하는 경우 날짜의 형식을 여러가지 형태로 변경해서 적용을 해봐야 합니다.
시계열 데이터 분석을 할 때 분석에 악영향을 미칠 수 있습니다.
=>시계열 데이터를 출력할 때는 모든 데이터를 기반으로 하지 않고 특정 범위에 한정되는 데이터만 사용하기도 합니다.
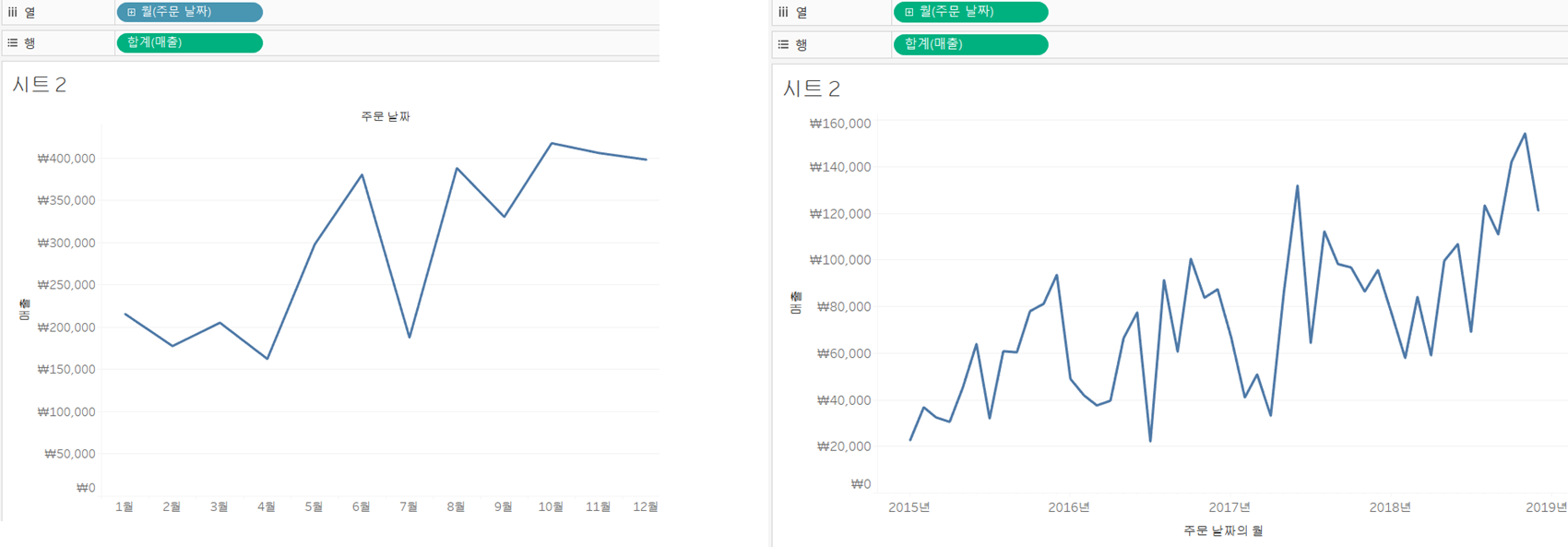
2)라인차트 그리기
=>Superstore_Sample 데이터를 이용
=>[주문 날짜]를 열 선반으로 드래그
=>[매출]을 행 선반으로 드래그
날짜 항목이 있으므로 기본적으로 라인차트를 만들어줍니다.
라인 차트가 아닌데 라인 차트로 변경하고자 한다면 표현 형식을 나타내는 콤보 박스를 눌러서 라인을 선택해주면 됩니다.
날짜의 경우 2023년 1월 부터 2024년 1월 까지의 데이터가 월 별로 있는 겨우 [불연속형]의 월을 선택하면 각 월을 하나의 범주로 간주하기 때문에 12개의 항목이 만들어지고, 2023년 1월과 2024년 1월의 데이터를 합산해서 하나의 데이터로 간주하고 [연속형]의 월을 선택하면 2개의 데이터는 다른 데이터가 됩니다.
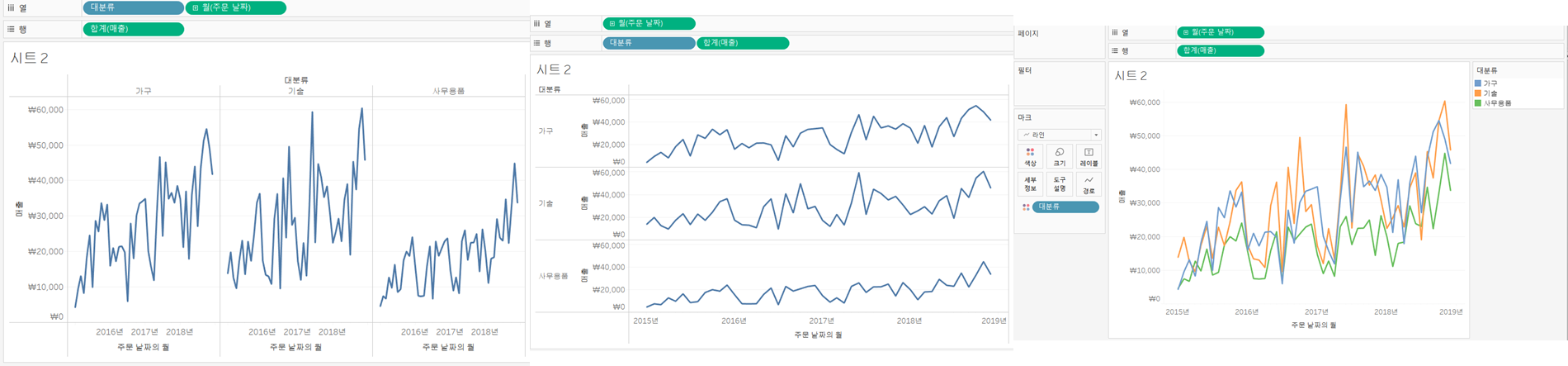
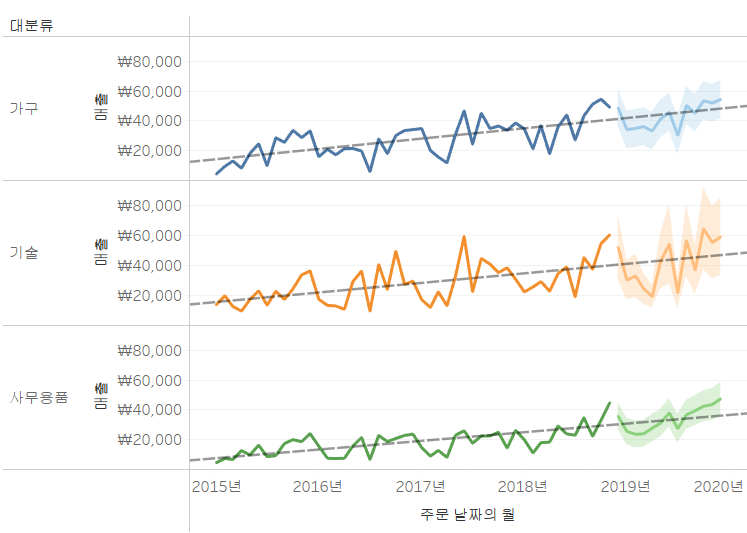
=>[매출]을 [대분류]별로 확인
[대분류]를 열 선반에 두면 가로 방향으로 분할되고 행선반에 두게 되면 세로방향으로 분할되고 색상에 배치하면 항목별로 겹쳐서 그리게 됩니다.
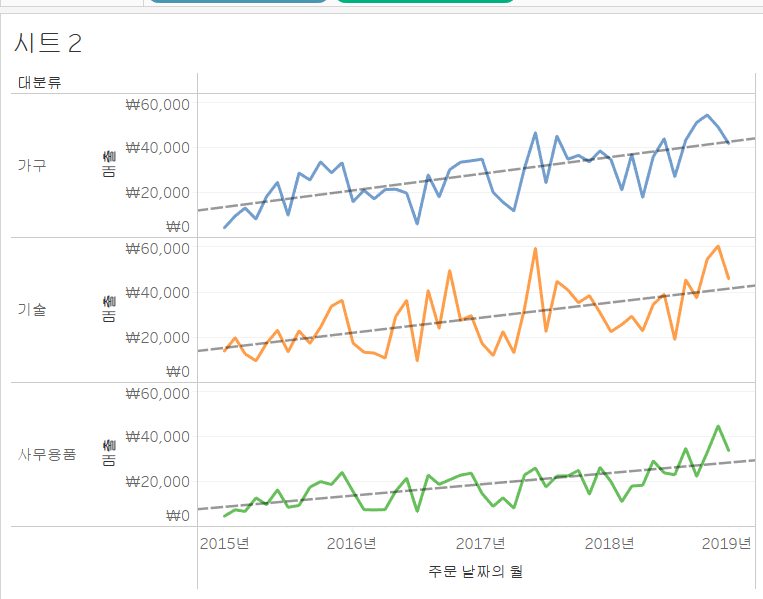
=>추세선 기능
회귀 분석을 이용해서 회귀 계수와 절편을 구해서 하나의 그래프를 별도로 만들어주는 기능입니다.
[분석]탭에서 [모델] 항목에 [추세선]을 뷰 영역으로 드래그하고 회귀 분석 모형을 선택해주면 됩니다.
=>예측 기능
회귀 분석을 통해서 나온 결과를 가지고 미래의 값을 예측하는 기능
[분석]탭에서 [모델] 항목에 [예측] 을 뷰 영역으로 드래그
3)라인/막대 이중 축 차트
=>막대 그래프와 라인그래프를 같이 그리면 서로 다른 2가지 정보를 하나의 축으로 확인할 수 있기 때문에 지표 비교나 연동 시 유용하게 활용
=>막대 그래프나 라인 그래프 만으로 서로 다른 2가지 정보를 확인하는 경우는 값의 범위가 유사한 경우만 가능합니다.
=>데이터 분석을 하기 전에 수행하는 전처리 과정에서 각 피쳐의 데이터 크기가 고르지 않을 떄 크기를 맞추기 위해서 0.0~1.0 또는 -1.0에서 1.0에 범위로 데이터를 조정하는 스케일링 작업도 같은 이유입니다.
일반적인 머신러닝은 Scaling은 필요하지만 딥러닝을 Scaling은 할 필요가 없습니다. 머신러닝은 데이터 자체를 바라보고 딥러닝은 데이터를 쪼개서 바라보는 편입니다.
=>이중 축 차트를 이용하면 서로 다른 항목의 데이터를 하나의 영역에 표시해서 새로운 인사이트를 습득하거나 올바른 의사결정을 내리는데 도움이 될 수 있습니다.
여러 항목들을 이런 차트나 상관계수를 구해서 비교한 후 머신러닝이나 딥러닝을 할 때 피처 제거나 여러 피쳐를 모아서 하나의 feature을 만드는 경우가 있습니다.
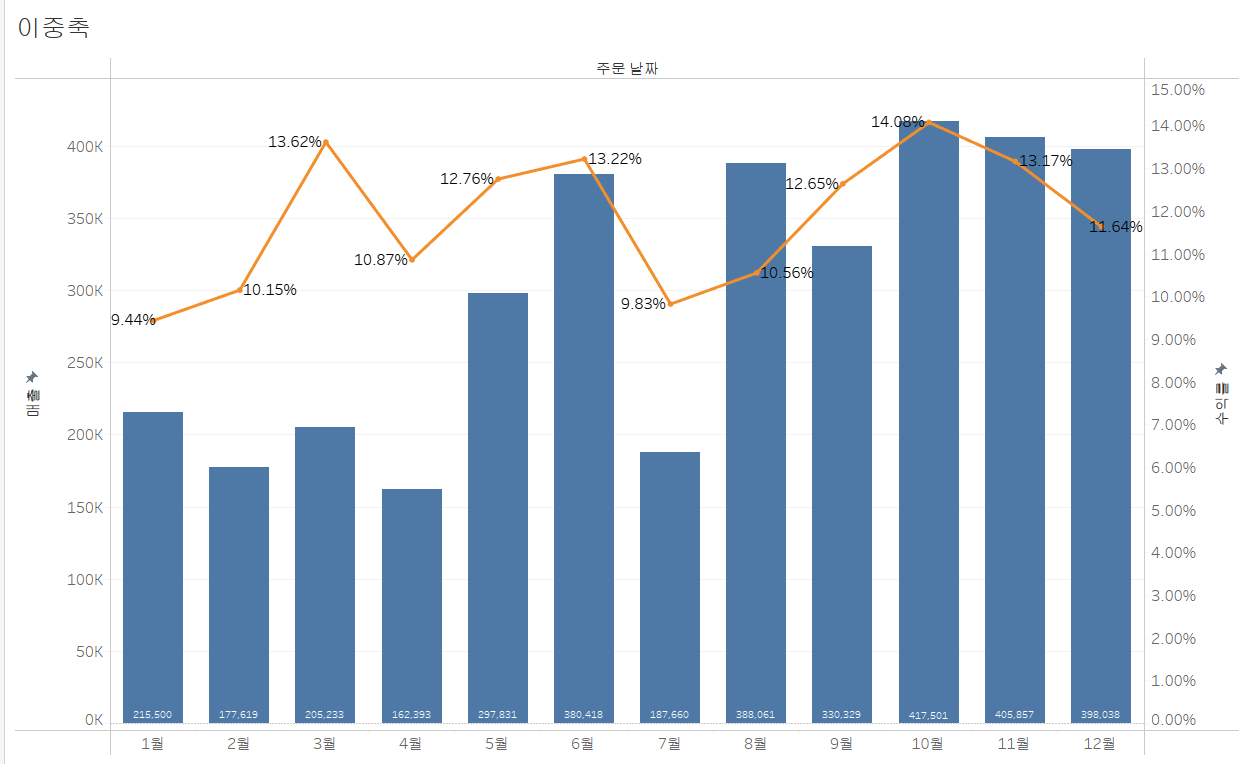
=>주문 날짜의 월 별 [매출]과 [수익률-수익/매출]을 이중 축 차트로 출력
-[주문 날짜]를 열 선반에 배치하고 불연속형의 월로 변경
-수익률 데이터 생성
데이터의 빈 영역에서 마우스 오른쪽을 눌러서 [계산된 필드 만들기] 항목을 선택해서 이름과 수식을 입력합니다.
이름 - 수익
수식 - sum([수익]) / sum ([매출])
-[매출] 과 [수익률] 필드를 행 선반에 배치
열 선반의 데이터가 날짜 형식이므로 라인 차트가 2개 만들어 집니다.
-이중 축을 만들고자 하는 필드를 선택하고 추가 메뉴를 눌러서 [이중 축]을 선택
오른쪽에 매출을 위한 축이 생성되고 차트는 하나의 영역 같이 그려집니다
-매출의 라인 그래프를 막대 그래프로 변환
행 선반에 있는 [매출]을 선택하고 유형을 자동에서 막대로 변경하면 됩니다.
5.Tree Map Chart
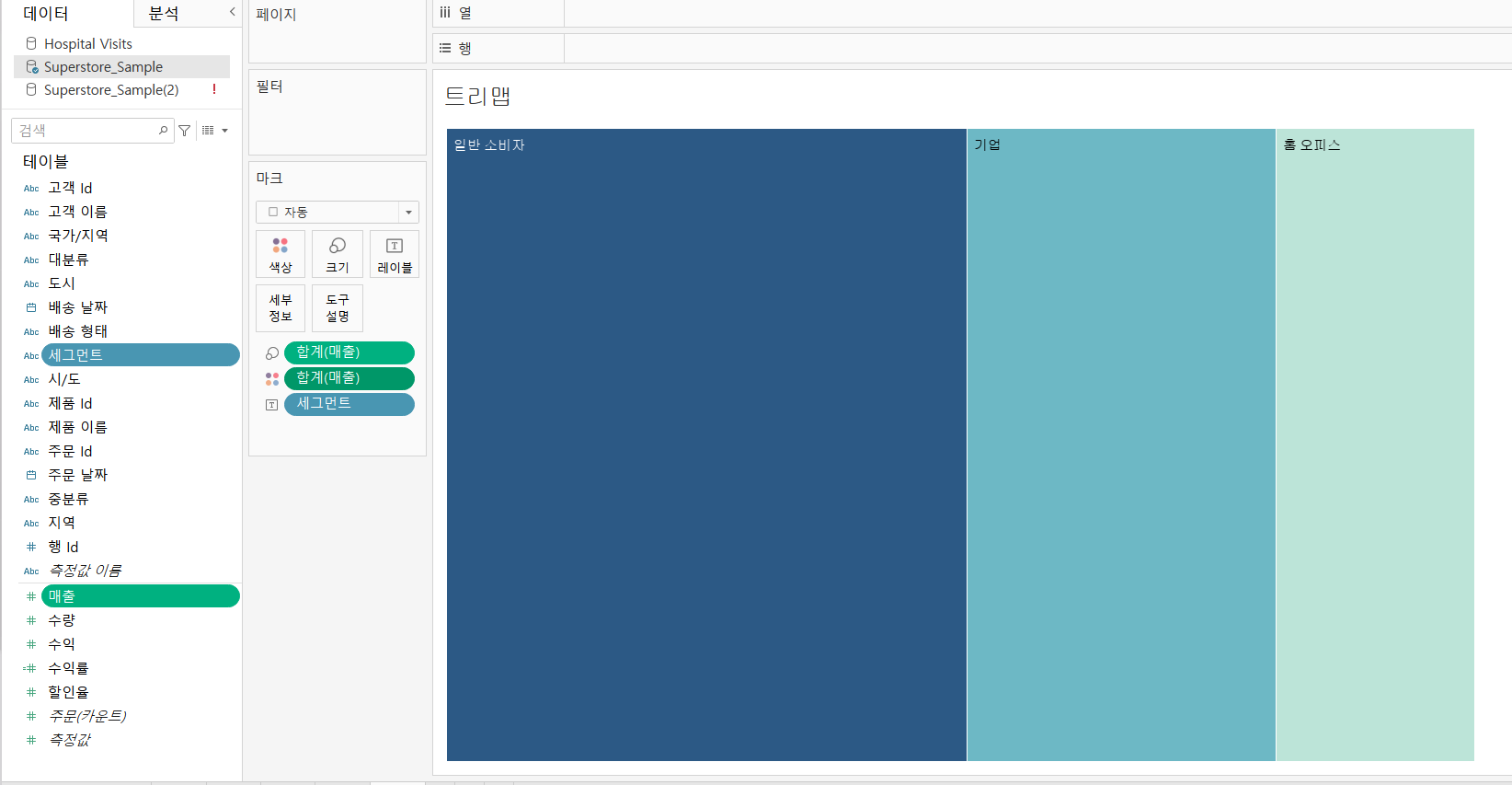
1)개요
=>하나의 차원과 측정값으로 만들 수 있는 차트
=>측정값의 크기에 따라서 사각형의 색상과 크기를 다르게해서 표현하는 차트로 구성 비율 또는 비중을 살펴볼 수 있습니다.
=>항목 별 데이터의 크기가 차이가 많이 나야 효과적
=>5개 이상의 항목이 존재하는 경우는 트리 맵 차트가 효과적이고 5개보다 적다면 누적 막대나 원형 또는 파이차트가 효과적
2)세그먼트 별 매출의 구성 비율을 트리 맵차트로 구현
=>[세그먼트] 와 [매출]을 선택한 상태에서 오른쪽의[표현 방식]에서 Tree Map Chart 를 선택하면 됩니다
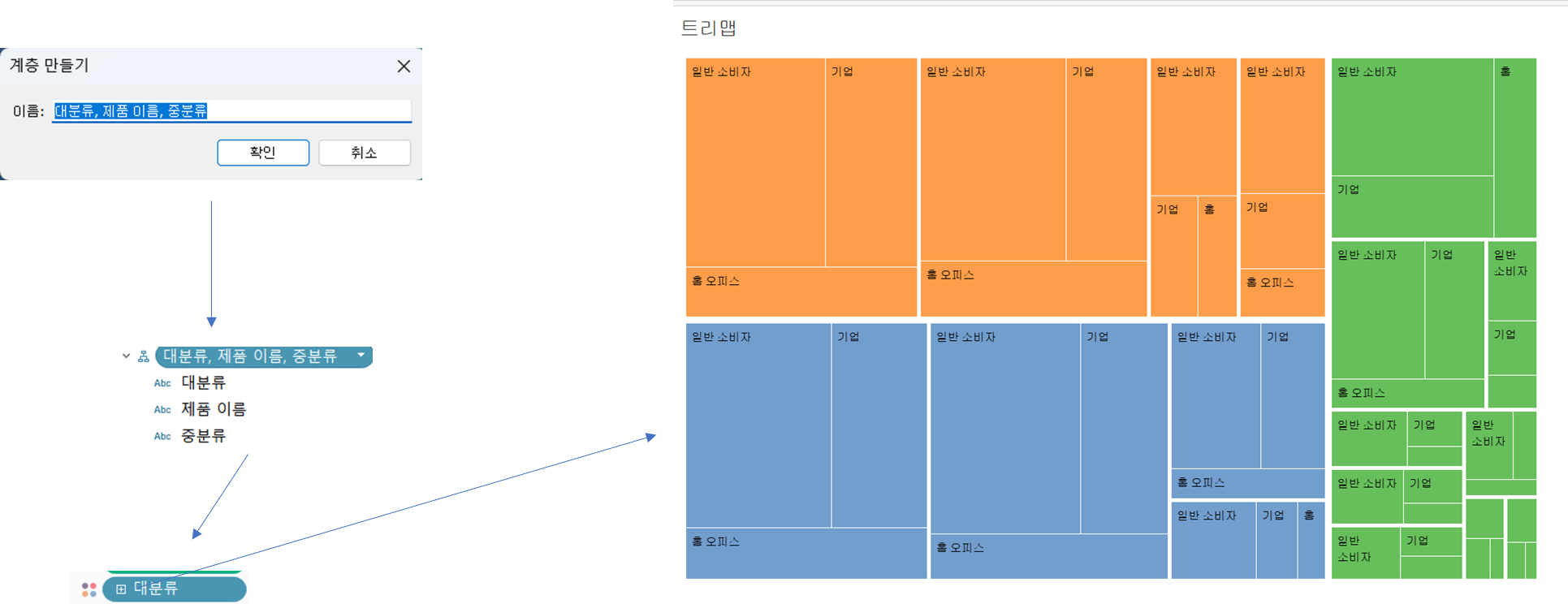
=>여러개의 차원을 하나의 계층으로 생성:python 의 pandas 에서는 멀티 인덱스라고 합니다.
대분류안에 중분류가 있고 중분류 안에 제품이름이 존재하는 경우라서 이 3개를 선택하고 마우스 오른쪽을 눌러서 [계층]을 선택해서 하나의 차원으로 묶을 수 있습니다.
=.>새로 만들어진 계층을 색상 선반에 배치
계층 내에서 가장 큰 분류인 대분류별로 색상이 적용됩니다.
6.Word Cloud
1)개요
=>Tag Cloud라고도 하는데 단어의 빈도수를 단어의 크기나 색상으로 표현하는 텍스트 데이터 시각화를 위한 방법 중 하나
=>최근에는 이미지 위에 표현하기도 합니다.

태블로는 이미지 위에 표현하지 못해서 주로 파이썬의 워드 클라우드, 태그 클라우드 라이브러리를 사용합니다.
워드 클라우드할떄는 특정 단어를 배제해야하는데 불용어(Stop Word)를 활용해서 배제해야합니다.
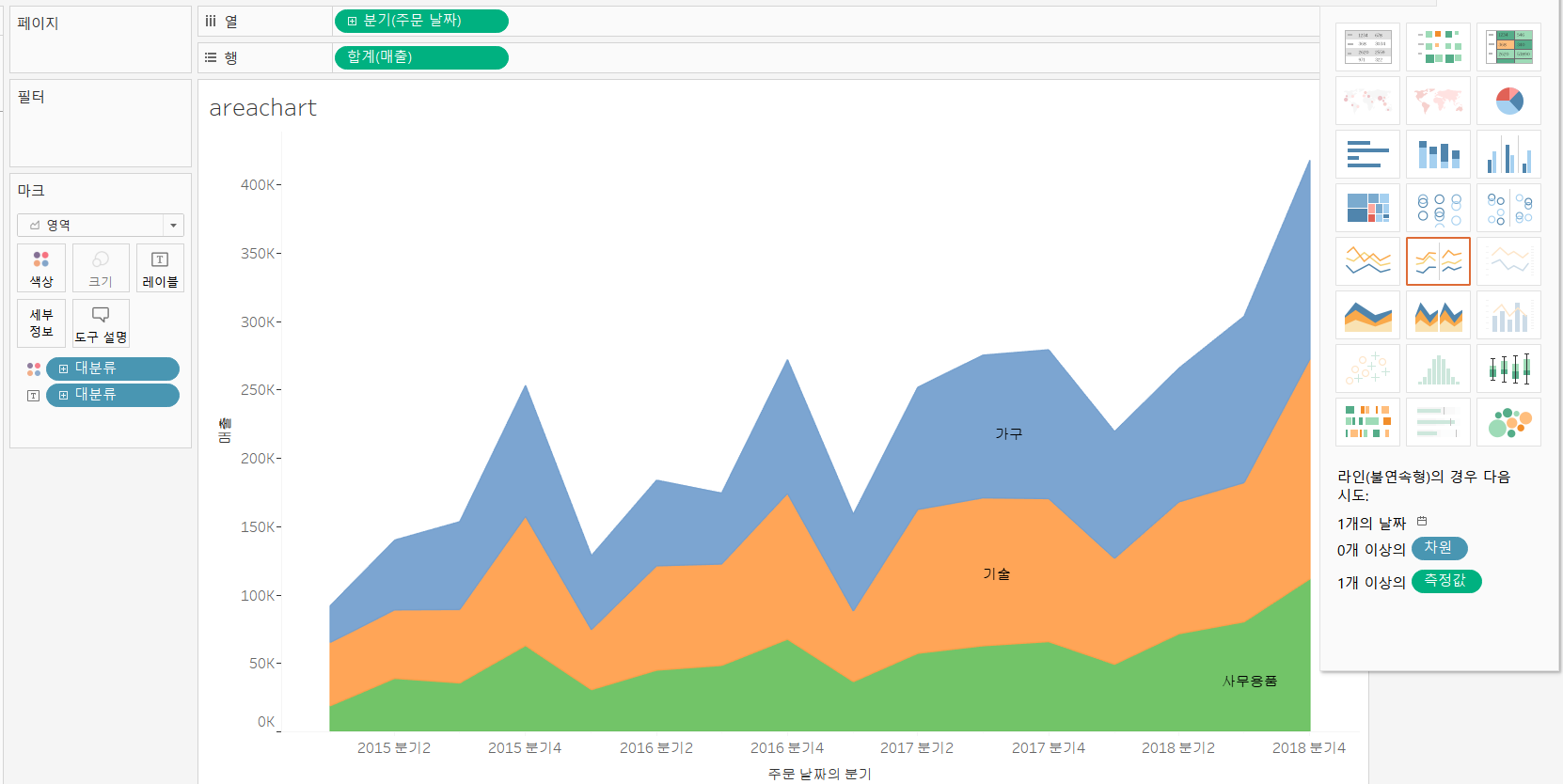
7.Area Chart
1)개요
=>시계열에 따른 누적 데이터가 어떻게 구성되고 있는지 보여줄때 많이 사용하는 차트
라인 차트와 다른 점은 라인 차트는 추세만을 표시하지만 영역차트는 누적데이터를 가지고 이를 표현
=>영역 차트를 만들기 위해서는 1개의 시계열 데이터와 1개의 차원 과 측정값 필드가 필요
=>시계열 데이터를 열 선반에 배치하고 측정값을 주로 행 선반에 배치하고 범주를 색상으로 배치합니다.
각 항목의 성질이 다르기 때문에 한꺼번에 선택하고 영역 차트를 선택하면 태블로가 알아서 배치를 합니다.
2)영역차트 생성
=>[주문날짜-시계열]와 [대분류-범주형] 그리고 [매출-측정값]를 선택한 후 표현 형식에서 영역차트를 선택
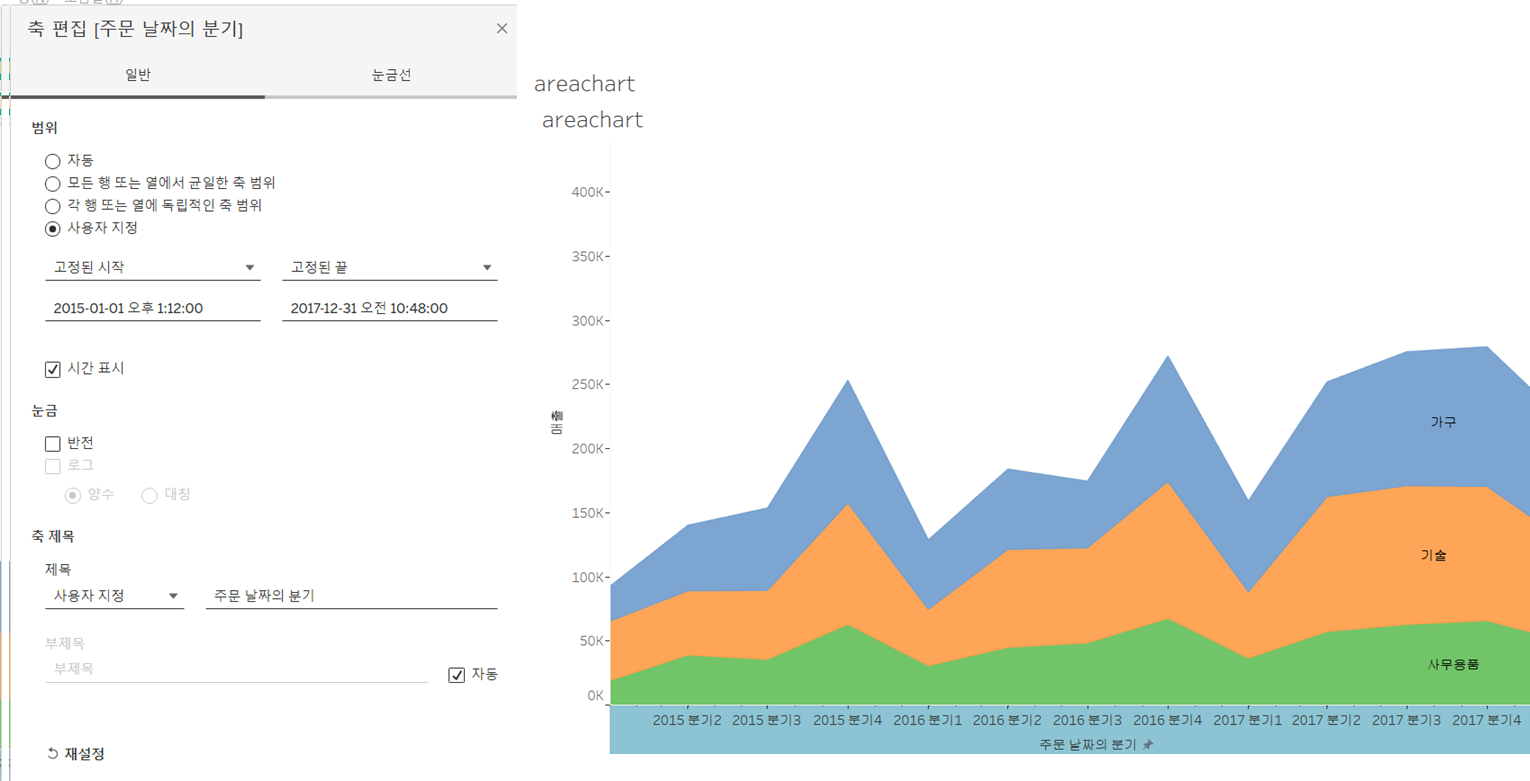
=>시계열 데이터를 표현하는 경우는 데이터 전체를 사용하지 않는 경우도 있습니다.
X축을 선택하고 마우스 오른쪽을 누른 후[축편집 ...]에서 범위에서 [사용자 지정]을 이용해서 직접 설정이 가능합니다.
8.Scatter chart
1)개요
=>분산형 차트는 행 과 열 선반에 각각 1개 이상의 측정값을 활용해서 해당 데이터가 어떻게 분포되는지를 파악할 수 있는 차트
=>색상과 크기를 이용해서 세부 정보를 표현
=>데이터의 분포나 상관 관계를 알고자 할때 유용
=>두개의 측정값을 나열할 때 서로 관련성이 높은 데이터를 배치
수익성 과 매출 또는 수익률과 반품률 같은 데이터를 같이 배치
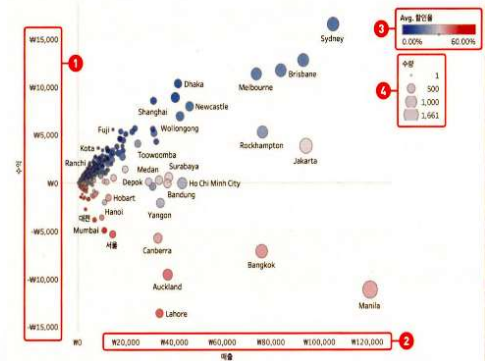
색상을 적용하면 색상표를 만들어냄
2)분산형 차트 생성
=>마크 선반 위의 유형을 원으로 변경
=>분산형 차트는 일반적으로 숫자 데이터만으로 구성
[매출]을 열 선반에 [수익]을 행 선반에 배치
=>봄주를 배치할 때는 세부정보에 배치
[도시]를 세부정보에 배치
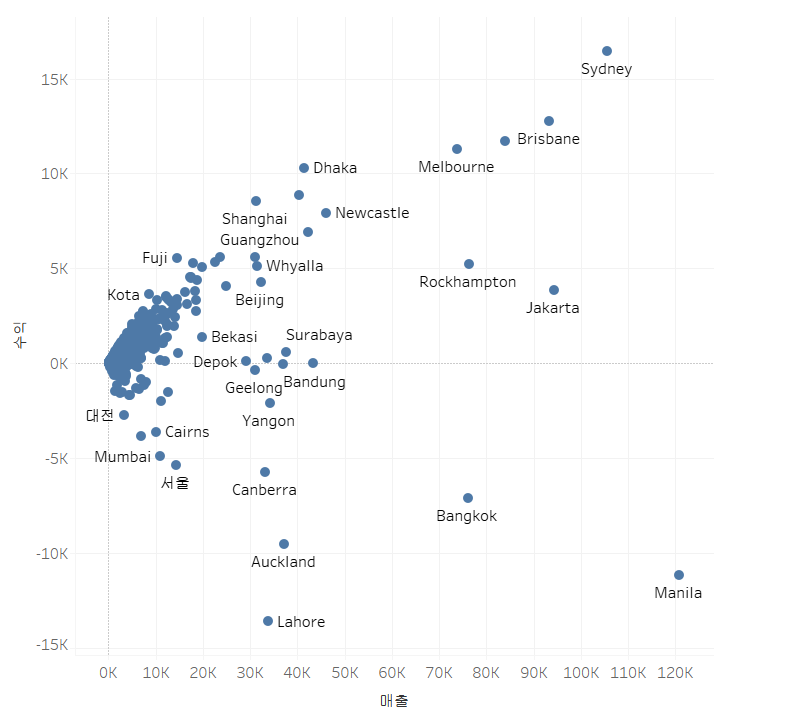
=>배치되는 모양을 확인해보고 대각선 모양에 가까우면 상관관계가 높다고 할 수 있고, 분포가 사각형이나 원형에 가까우면 상관관계가 거의 없다고 볼 수 있고 이런 경우는 대부분 클러스터링(군집)을 하는 경우가 많습니다.
=>3번쨰 특성을 적용하고자 하는 경우 일반적으로 크기에 배치
[할인률] 필드를 크기에 배치

=>4번째 특성을 적용하고자 하는 경우 일반적으로 색상에 배치
[수량]필드를 색상에 배치

=>분산형 차트를 볼때 데이터의 분포가 일정한 선의 모양이나 특정영역에 몰려있는 경우 이상치 탐색에도 사용할 수 있습니다.
'Study > tableau 및 데이터 시각화' 카테고리의 다른 글
| Tableau(4) (1) | 2024.02.06 |
|---|---|
| tableau(3) (0) | 2024.02.02 |
| Tableau(1)-기초 (0) | 2024.01.31 |


