1,분포시각화
1)Scatter chart (산점도, 산포도, 원 그래프)
2)BoxPlot Chart
=>개요
분포에 통계적 맥락을 추가한 차트
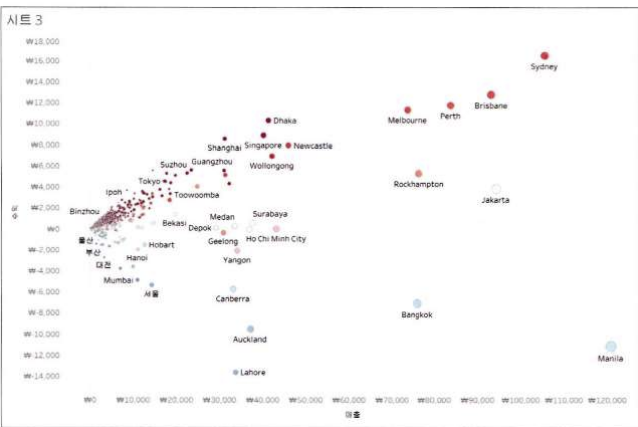
=>의사별 대기시간을 산포도로 만들고, 박스 플롯을 추가

데이터는 Hospital Visits.csv 파일 이용
마크 유형을 원(Scatter)을 선택
Department Type을 행 선반에 배치
산점도는 근본적으로 숫자 필드여야됩니다.
2개의 날짜 차이를 필드로 생성 :
Time_diff 계산식- DATEDIFF('day',[Date of Admit],[Date of Discharge])'
Time_diff 필드를 열 선반에 배치하고 세부 메뉴를 선택해서 평균으로 측정값을 변경

Doctor 필드를 세부 정보 카드에 배치
여기까지 수행하면 가로 방향으로 시간의 분포를 알아볼 수 있습니다.
[분석] 탭에서 박스 플롯을 뷰영역으로 드래그

=>IQR: 3/4 지점에서 1/4 지점의 값을 뺸 값으로 이상치를 판단하는 방법 중 하나로 IQR에 +-1.5 를 곱한 범위 외의 값을 이상치로 판단합니다.
2.Heatmap Chart
1)개요
=>테이블 형식으로 데이터 수치 상의 차이를 색상으로 구분하는 차트
=>열과 행에 날짜를 배치하는 경우가 많습니다
날짜 형식의 월 이나 일 또는 요일을 배치해서 다른 날짜와 비교하고 추세도 알아보고자 할 때 많이 사용합니다.
=>태블로는 사각형 차트입니다.
2)실습
=>Superstore_Sample.xlsx 파일의 데이터를 이용
=>주문 날짜를 열과 행 선반에 배치하고 열 선반의 데이터는 불연속형의 요일을 선택하고 행 선반의 데이터는 불연속형의 월을 선택
=>색상 카드에 [매출]필드를 표시

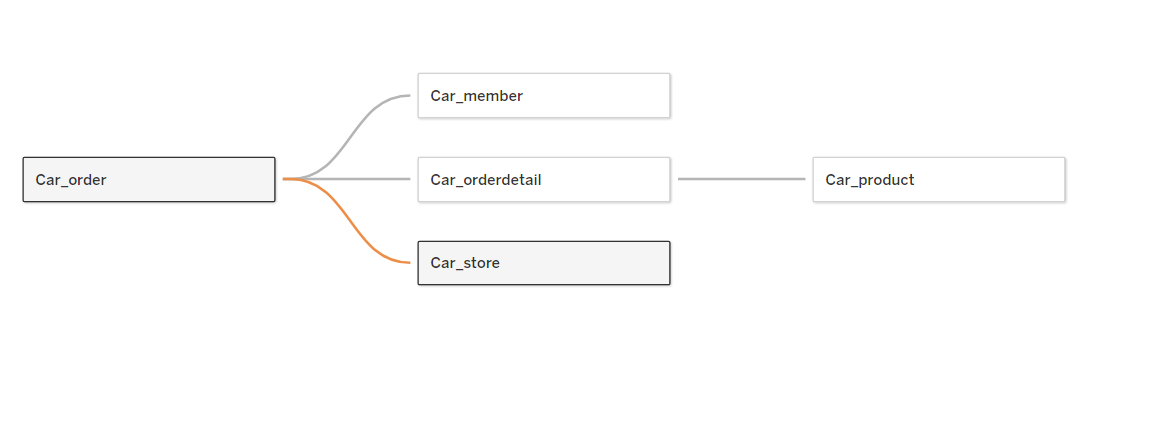
3JOIN
=>태블로에서는 여러개의 데이터를 조인해서 사용할 수 있습니다.
겹치는 컬럼이 있다면 계속 조인이 가능합니다.하지만 조인이 되지 않은 데이터는 쓸 수 없습니다.
=>실습
-Car for Table.xlsx 파일의 데이터 이용
모든시트를 사용할 수 있도록 조인
4.Filter
=>데이터의 일부분을 제거하고 조건에 맞는 데이터만 추출하는 기능
1)데이터 원본 필터
=>원본 데이터에 필터를 적용
=>데이터를 불러오는 단계에서 필터링 되기 떄문에 대용량 데이터를 불러올 때 유용
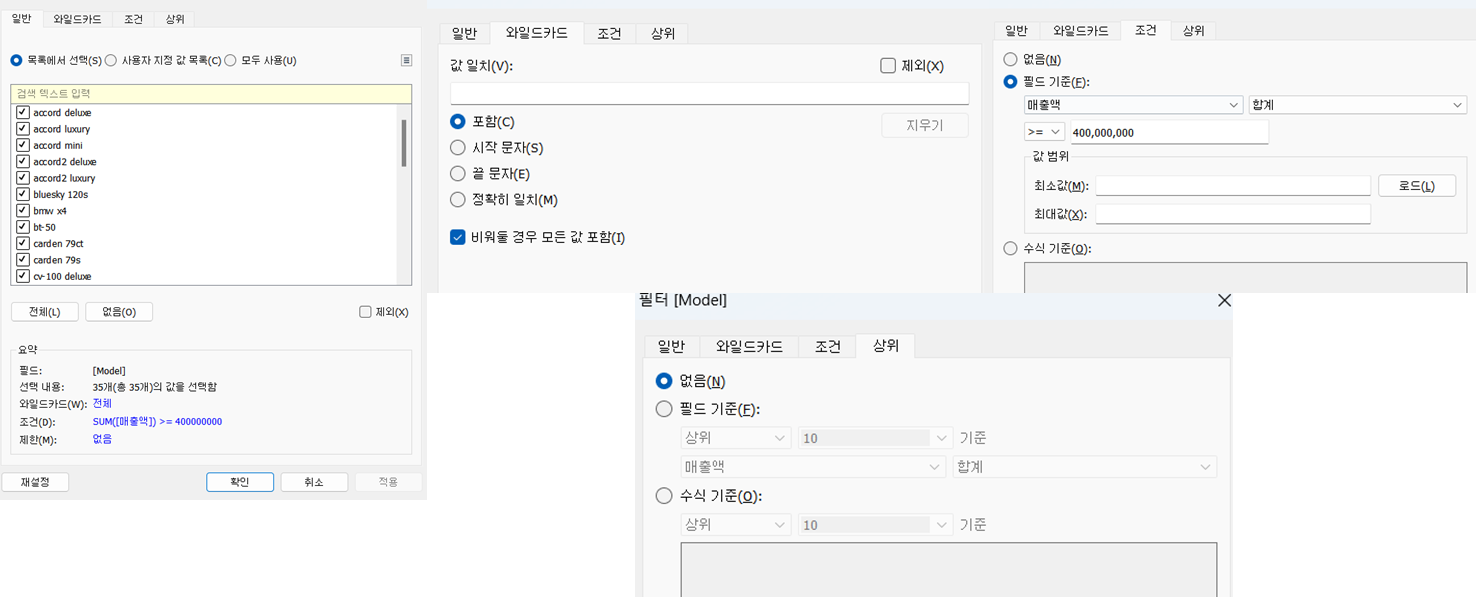
=>데이터 원본 창의 오른쪽 상단의 [필터]-[추가]를 눌러서 원하는 데이터만 선택하면 됩니다.
=type 에서 truck 을 제외

2)워크시트 페이지 필터
=> 필터 이동 및 재생을 통해 워크ㅣ트 뷰를 동적으로 보이게 하는 기능을 구현하고자 할 때 사용
=>Type별 매출액을 이용한 막대 그래프를 생성
-계산된 필드 기능을 이용해서 매출액 필드 생성
[Price]*[Quantity]
-행 선반에 Type필드를 배치
-열 선반에 매출액 필드를 배치
-Type을 색상으로 설정
-매출액을 레이블로 설정
-주문일자(Order Date)을 페이지에 배치하고 연속형의 월로 수정
-페이지에 배치하면 오른쪽에 애니메이션 관련 메뉴가 추가됩니다.

=>워크시트 필터 기능
-행 선반에 Model 배치
-열 선반에 매출액 배치
-색상과 레이블에 매출액 배치
-내림차순으로 데이터 정렬
-색상에 '빨간색' 10단계로 변경
5.필드와 뷰 기능
1)필드 변환
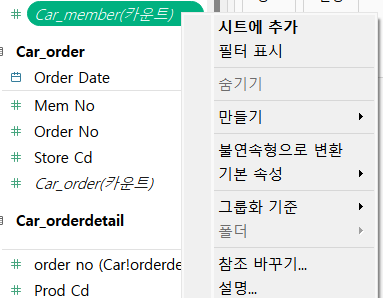
=>필드의 종류를 변경하는 것이 가능
=>범주형 데이터를 어떤 이유에서 숫자로 표현한 경우 이 데이터를 범주형으로 다시 되돌리고자 하는 경우 데이터를 선택하고 세부 메뉴를 눌러서 [불연속형으로 변환]을 선택해주면 됩니다.
2)별칭
=>범주형의 값을 화면에 출력할 때 다른 값으로 출력 가능
=>범주형의 데이터를 숫자로 표현하거나 다른 언어로 표현된 경우 별칭을 이용해서 화면에 출력할 때는 다른 이름으로 출력할 수 있습니다.
3)계산된 필드
=>기존의 데이터를 이용해서 새로운 데이터를 만들어내는 것
=>파생 필드라고도 합니다

=>IF 의 사용법과 CASE의 사용법 정도는 알아두는 것이 좋습니다
IF [조건] THEN 값
ELSEIF [조건] THEN 값
...
ELSE
END
CASE
WHEN 값1 THEN 값2
...
END
4)그룹
=>그룹은 차원이나 측정값 필드 값을 그룹화 할때 사용하는 기능
일반적으로는 차원을 그룹화하는ㄴ데 활용
측정값도 그룹화 할 수 있는데 측정값은 일반적으로 범위를 이용하기 떄문에 그룹화하고자 하면 계산된 필드를 이용합니다.
=>필드를 선택하고 세부 메뉴를 눌러서 [만들기]-[그룹]을 선택하고 항목을 CTRL 키를 이용해서 선택한 후 하단의 [그룹]을 선택하면 됩니다.

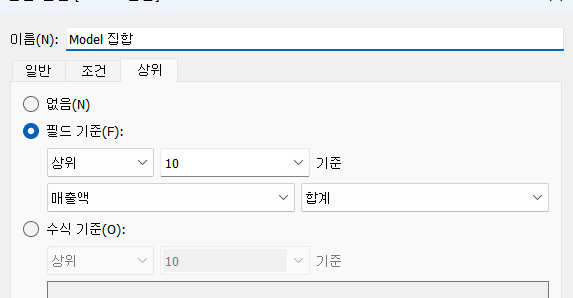
5)집합
=>고정 집합과 동적 집합으로 분류
=>동적 집합이란 데이터가 변경되면 집합의 데이터가 자동으로 변경되는 집합
=>상위 몇 개 이런식으로 만들어지는 것이 집합
동적 집합은 필터를 이용해서도 비슷하게 만들 수 있습니다.

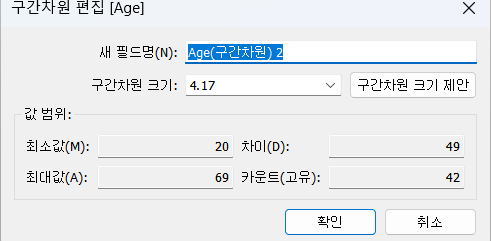
6)구간 차원
=>수치 데이터를 그룹화 할 때 사용하는 기능
=>수치 데이터를 가지고 히스토그램을 만들려고 할 때 주로 이용하는데 binning이라고도 합니다.
=>AGE 필드는 수치 데이터입니다.
AGE 필드의 값을 직접 이용하기도 하지만 연령대 같은 형태로 범주화해서 사용하기도 합니다.
계산된 필드를 이용해서 만들 수 있지만 여러 범주로 분할하는 경우 수식이 복잡해질 수 있습니다.
7)매개변수
=>사용자가 직접 변수를 활용해서 뷰를 필터링하는 기능
=>대부분의 경우 차원을 가지고 수행
=>생성 방법은 만들고자 하는 필드를 선택하고 마우스 오른쪽을 눌러서 [매개변수]을 선택해도 되고, 아니면 사이드 바의 상단을 클릭해서 만들어도 됩니다.
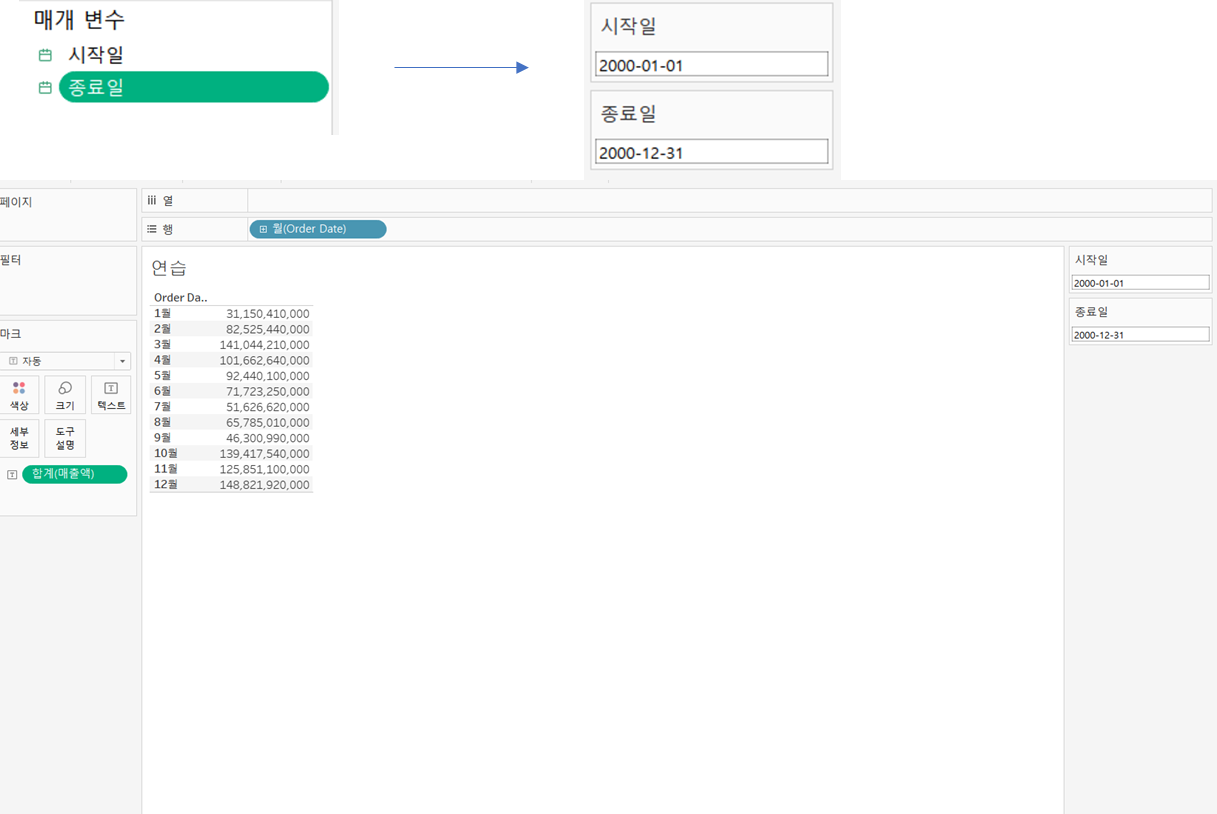
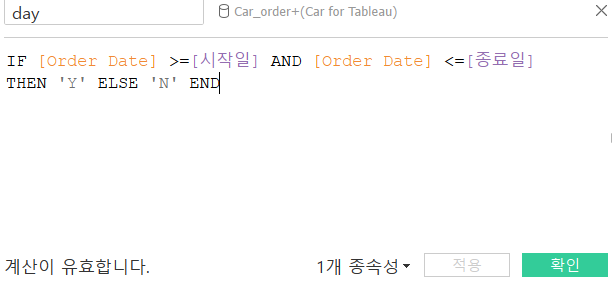
=>매개변수를 만들면 계산된 필드를 새로 만들어서 활용
IF [Order Date] >=[시작일] AND [Order Date] <=[종료일]
THEN 'Y' ELSE 'N' END
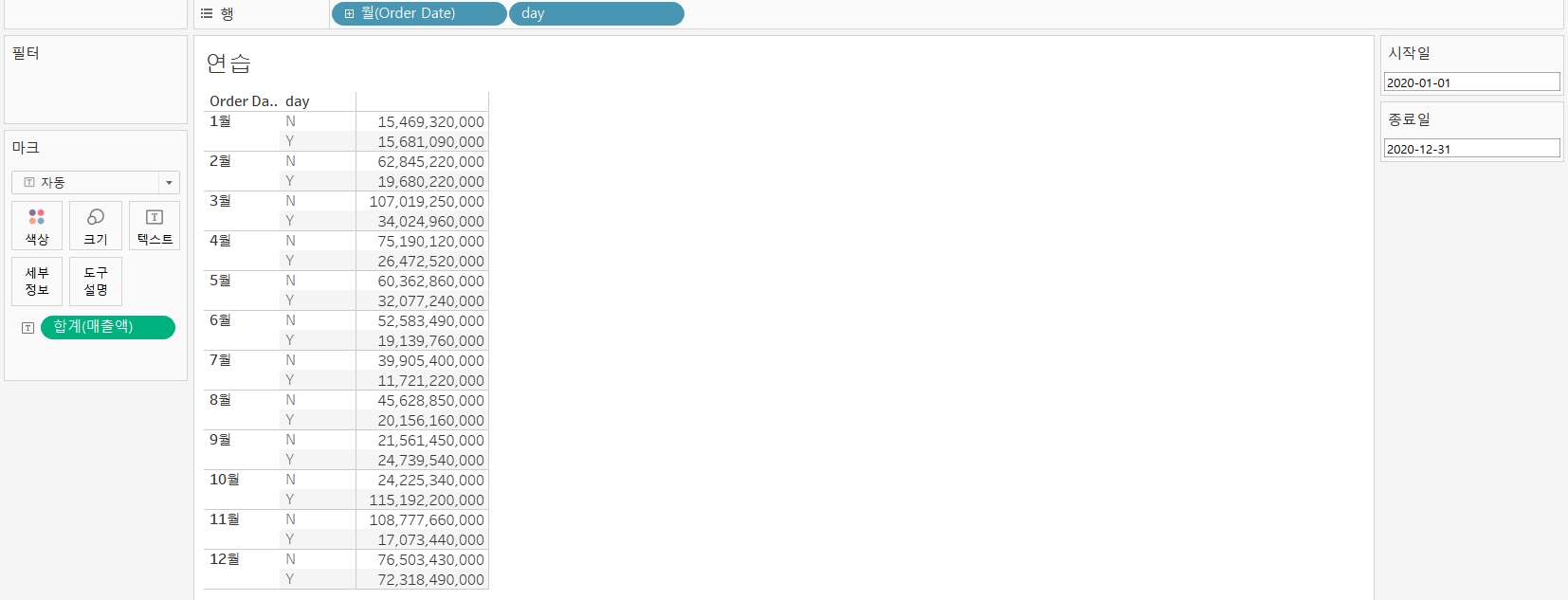
=>대시보드로 만들게 되면 원하는 매개변수를 선택하면 그에 따라 차트에 보여짐
8)분할 기능
=>하나의 필드가 2개이상의 데이터 조합인 경우 사용할 수 있는 기능
=>태블로에서는 분할과 사용자 지정 분할로 분할 기능이 나누어져 있습니다
분할은 태블로가 반복되는 패턴을 찾아서 분할해주는 것이고 사용자 지정 분할은 분할 기호를 사용자가 직접 지정하는 것입니다.

9)계층
=>여러 차원 필드의 값을 가지고 하나의 계층을 만들어주는 기능
10)데이터 유형 및 지리적 역할
=>데이터 유형 및 지리적 역할
데이터 유형:숫자/날자/문자열 변환
지리적 역할:문자열 중에서 국가/시도/카운티 등으로 지리적 역할로 변환하는 것
11)현재Store_ Addr 필드에 주소가 문자열로 만들어져 있는데 이를 가지고 지도를 출력
=>Store_addr 은 시&도 와 시가 합쳐져 있는 구조이므로 분할을 먼저 수행
Store_addr 을 선택하고 세부 메뉴를 누른 후 [변환] - [분할]을 선택
결과는 store_addr - 분할1 과 store_addr-분할2 라는 2개의 필드로 분할됩니다.
=> store_addr - 분할1 과 store_addr-분할2라는 필드를 하나의 필드로 만들고자 하는데 게층을 생성해서 생성
Shift 키를 이용해서 2개의 필드를 선택하고 [계층] - [계층 만들기]를 선택한 후 계층이름을 드래그(Store Addr 계층)
=>store_addr -분할1을 선택하고 세부 메뉴를 눌러서 지리적 역할을 시도로 선택
=>store_addr -분할2을 선택하고 세부 메뉴를 눌러서 지리적 역할을 시군구로 선택
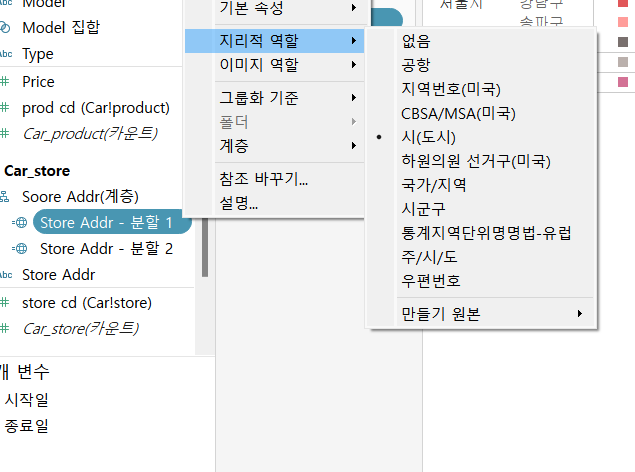
=>store_addr(계층)필드를 색상 및 세부 정보 카드에 배치

6.분석 탭
1)요약
=>상수 및 평균 라인
측정값 필드의 상수 및 평균 요약 정보가 뷰에 표시
상수라인은 중간에 선을 삽입하는 기능
- 행 선반에 매출액 그리고 선반에 Order Date필드를 드래그
-분석 탭에서 상수 라인을 뷰로 드래그 한 후 월을 선택하고 날짜를 선택하면 그 날짜에 선이 그어집니다
선을 이용해서 구분하고자 할 떄 사용
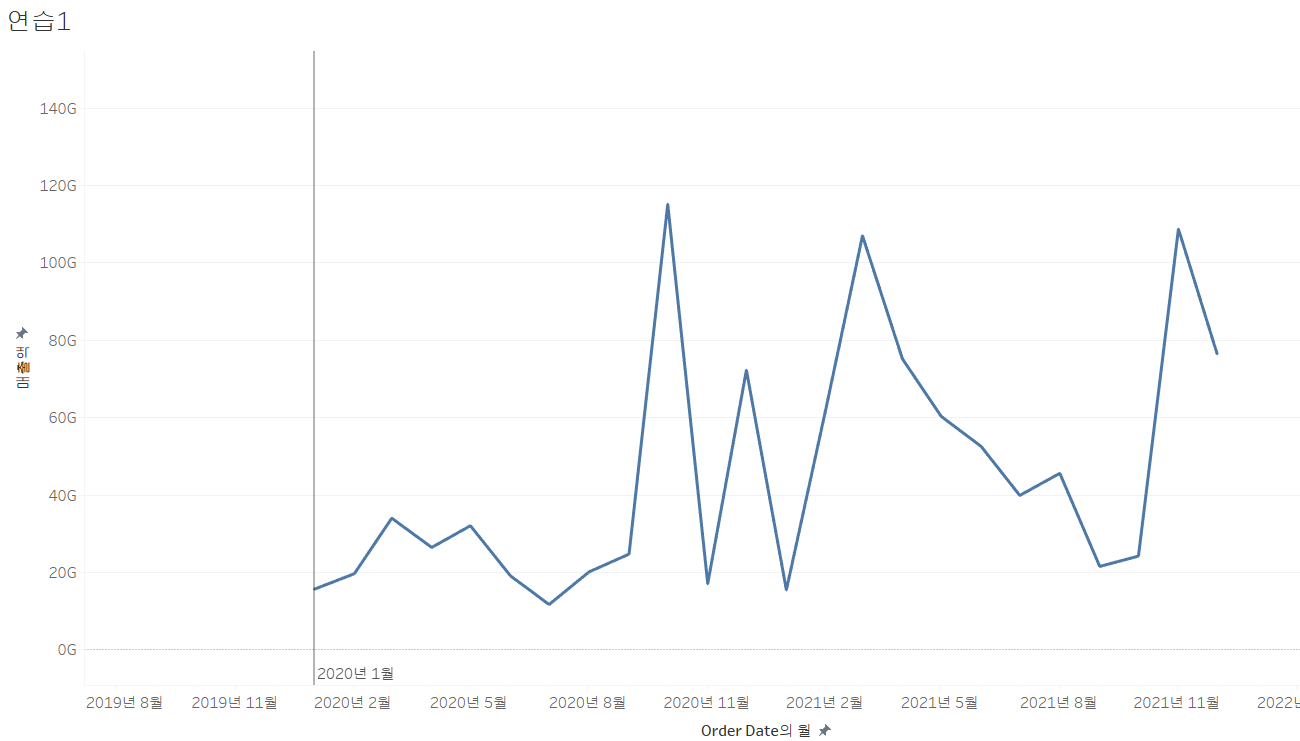
-- 분석 탭에서 평균 라인을 뷰로 드래그 하면 평균에 해당하는 값에 선을 그어 줍니다

=>총계
테이블 형태로 데이터를 출력할 때 분류별 합계를 알고자 할 때 사용
대시보드를 만들 때 데이터를 제공하기 위해서 사용
-Brand 와Model을 행에 배치 Gender을 열에 배치
-매출액을 텍스트 선반에 배치:테이블 형태로 데이터값이 출력
-분석 탭에 총계를 뷰로 드래그하면 부분합계를 출력할 수 있는 메뉴가 보이고 이를 선택하면 부분합계가 출력됩니다
-[분석] 멘유의 [총계]를 이용해서 총계의 위치나 계산값을 평균이나 최대/최소값으로 변경이 가능

2)모델
=>95% CI의 평균 및 중앙값: 95% CI(Confidence Interval-신뢰구간)로 평균과 중앙값을 뷰에 표시
=>추세선은 회귀 분석을 통해서 회귀 계수와 절편을 구한 후 선을 만들어주는 기능입니다
추세선은 선형,로그, 지수,다항식,거듭제곱으로 만들 수 있는데 일반적으로 R^2(결정계수)이 가장 높은 것을 선택합니다.
p-value는 유의확률이라고 번역하는데 이 값을 가지고 판단할 때는 작은 값을 선택합니다.
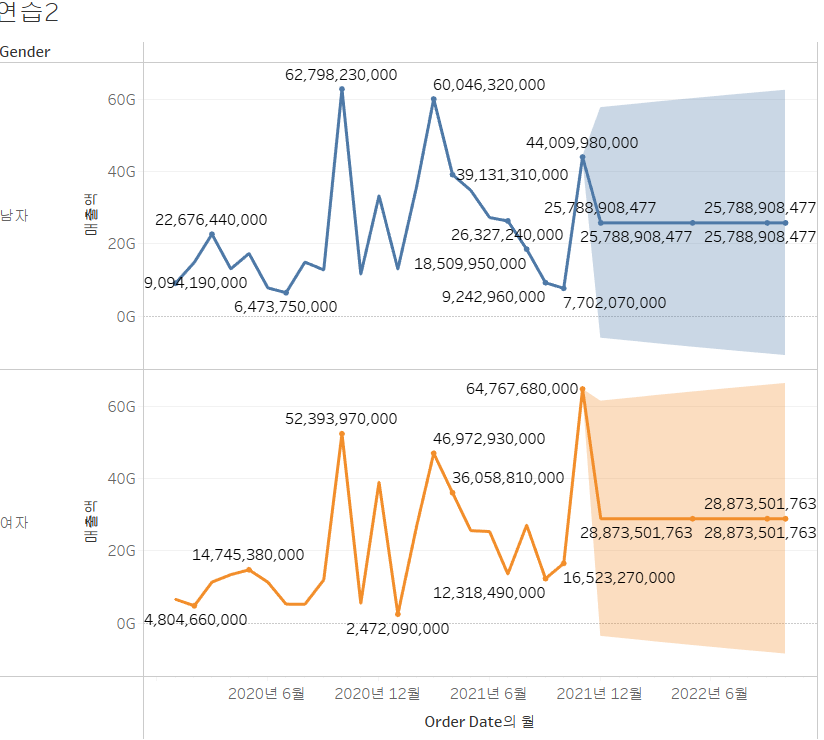
=>예측은 회귀 분석의 결과로 다음 데이터를 예측하는 기능입니다.
지수 평활법을 이용하는데 지수 평활법은 과거 관측치에 시간의 흐름에 따른 가중치를 계산하여 미래를 예측하는 것입니다.
=>클러스터는 그룹화 기능
일반적으로 2개의 숫자 데이터로 만들어진 산포도에서 거리를 기반으로 그룹화를 수행해주는 기능입니다
클러스터링의 개념은 비지도학습으로 레이블이 없는 데이터를 가지고 분류를 해내는 것입니다.

7.Gannt Chart
1)개요
=>시간의 경과 또는 어떤 활동에 대한 기간을 표시하는데 사용하는 차트
=>프로젝트 매니저가 프로젝트의 수행 기간을 표시하고자 하는 상황에 이용
=>대부분 프로젝트 계획 단계에서 일정관리을 위해 작성
=>태블로에서 사용하는 간트 차트의 개념은 프로젝트를 완료 한 후 작성하는 것
태블로에서 만드는 것은 간트 차트의 개념에는 맞지 않습니다.

'Study > tableau 및 데이터 시각화' 카테고리의 다른 글
| Tableau(4) (1) | 2024.02.06 |
|---|---|
| tableau(2) (0) | 2024.02.01 |
| Tableau(1)-기초 (0) | 2024.01.31 |


