0.데이터 분석 주요 패키지
numpy:선형대수, 배열 패키지
pandas: 데이터 프레임을 자료형을 패키지
matplotlib:기본적인 그래프 그리기 차트 패키지
seaborn:통계용 시각화 패키지
statsmodels:통계 및 회귀 분석 시계열 분석 패키지
scipy:미분 적분 패키지
sympy:미분 적분 패키지
pgmpy:확률 관련 패키지
scikit-learn:머신러닝용 모델 패키지
keras&tensorflow&pytorch:딥러닝 패키지
제품을 만들떄는 tensorflow 학습용은 pytorch
구글은 tensorflow로 안드로이드나 브라우저에서 만드는 패키지를 사용 가능
그냥 공부용은 pytorch가 더 효율적
**numpy
1.특징
=>Python 에서 고성능의 과학적 계산(선형대수)를 수행하기 위한 패키지
=>Python 머신러닝 스택의 기초가 되는 패키지
=>다차원 배열인 ndarray를 제공하고 벡터화 된 연산과 Broadcasting 연산을 지원
2.설치
=>pip install numpy
=>anaconda의 경우 자동으로 설치
=>다른 패키지를 설치할 때 종속적으로 설치되는 경우가 있음
=>numpy 가 다른 패키지에 종속적으로 설치되는 경우가 많아서 버전 문제가 발생할 수 있음
3.사용
=>import numpy:numpy 모듈을 현재 모듈에 numpt라는 이름을 가져와서 사용
=>import numpy as np: numpy 모듈을 현재 모듈에 np라는 이름으로 가져와서 사용
=>from numpy import *:모듈의 모든 내용을 현재 모듈에 가져와서 사용(왠만하면사용x)
=>from numpy import ndarray:numpy 모듈 중에서 ndarray만 가져와서 사용
4.ndarray
=>줄여서 array라고도 하고 배열로 번역
=>list 나 tuple 보다 생성 방법이 다양하고 할 수 있는 작업도 많음
=>id 의 모임이 아니고 값의 모임
list나 tuple은 id의 모임이기 떄문에 자료형이 달라도 생성이 가능
ndarray는 동일한 자료형의 grid
ndarray를 생성할 때 다른 자료형을 대입하면 추론을 통해서 하나의 자료형으로 변환해서 생성합니다.
python에서 ndarray가 빨라서 계산이 많은 경우, 고민해서 사용해봐야함
5.list와 ndarray의 산술 연산 비교
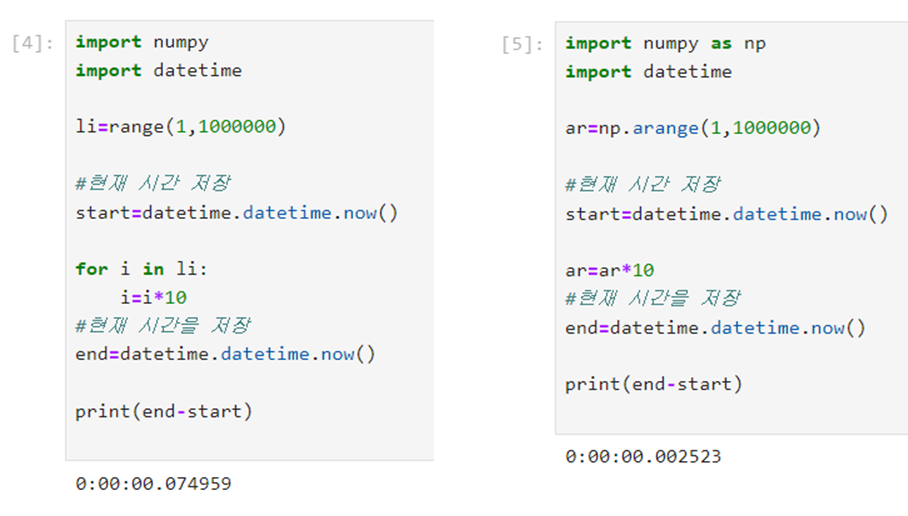
6.생성
=>numpy.array(object,dtype=None,copy=True)
object는 vector 자료형(데이터 모임-list,tuple.set등)의 데이터
dtype은 요소의 자료형인데 생략하면 numpy 가 추론
copy는 복제 여부로 기본값은 True
7.ndarray의 정보 확인 속성
=> dtype: 데이터 한 개의 자료형
=> ndim: 배열의 차원
=> shape: 각 차원의 크기를 튜플로 리턴
=> size: 데이터 개수
=> itemsize: 하나의 항목이 차지하는 메모리 크기
=> nbytes:전체가 차지하는 메모리 크기
8.배열을 생성하는 다른 방법
1)numpy.arange([start,],stop,[step,],dtype=None)
=>start 부터 stop까지 step을 가지고 생성
=>dtype은 데이터 1개의 하나의 자료형
=>[]은 생략 가능
=>1부터 10까지 홀수를 가진 배열을 생성
array=np.arange(1,10,2,dtype=int)
print(array)
2)numpy.linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None,axis=0)
=>start부터 stop까지 num의 개수를 배열로 만들어주는 것
=>endpoint 는 마지막 값 포함 여부
=>axis는 축입니다. 0는 column, 1은 row
3)numpy.zeros(),numpy.ones()
=>2개의 함수는 차원을 매개변수로 받아서 0 이나 1로 채워주는 함수
4)numpy.zeors_like()와 numpy.ones_like()
=>배열을 매개변수로 받아서 동일한 크기의 배열을 만들고 0 이나 1로 채워주는 함수
5)numpy.empty() 와 numpy.empty_like()
=>초기화 하지 않은 데이터(의미없는 값)의 배열을 생성
6)numpy.eye(N,M,k=0,dtype=None)
=>N은 데이터 개수이고 M은 열의 개수이고 k는 대각 위치로 0이면 주대각선 방향으로만 1로 채워주고 0이아닌 다른 숫자면 좌우로 대각 방향을 이동해서 1을 채워주는 단위행렬 생성
N과M중 둘 중 하나의 값만 입력하면 하나의 값을 복사해서 정방행렬을 생성해줍니다.
=>N과 M 2개의 숫자를 설정하면 앞의 숫자는 행의 개수가 되고 뒤의 숫자는 열의 개수가 됩니다.
7)numpy.diag(행렬)
=>행렬에서 주 대각선 방향의 데이터만 골라서 행렬을 만들어줍니다.
8)배열을 생성하는 방법 중 많이 사용되는 것
=>numpy.array(벡터 데이터)
=>numpy.arrange 나 numpy.linspace 는 샘플 데이터 만들 때 많이 사용
9.자료형
=>배열을 생성할 떄 dtype 옵션에 자료형을 설정하면 데이터를 자료형으로 형변환해서 생성
=>numpy의 ndarray는 모든 요소의 자료형이 동일해야 합니다.
데이터의 자료형이 다르면 하나의 자료형으로 변환해서 생성
숫자의 경우 int와 float 이 같이 있으면 실수로 숫자와 문자열이 같이 있으면 문자열로 만들어집니다.
=>요소의 자료형은 dtype 속성으로 확인 가능
=>자료형
정수:numpy.int8,int16,int32,int64,uint8,uint16,uint32,uint64 (uint은 부호를 포함하지않은 양의정수 unsigned int)
실수 자료형: float16, 32, 64, 128
복소수 자료형: complex64, 128, 256
boolean:bool
문자열:string
유니코드:unicode
객체:object
=>만들어진 배열의 자료형을 변경해서 다시 생성
ndarray.astype(자료형)
=>형 변환을 하는 이유
머신러닝에서는 숫자 데이터만 사용이 가능
서로 다른 배열끼리 연산을 하고자 하는 경우
메모리를 효율적으로 사용하기 위해서(RGB값인 0~255까지 숫자를 표현해야하는 경우: )

데이터 타입을 확인하는 작업을 제대로 하지않으면 어떤 자료형으로 구성되있는지 확인해봐야함.
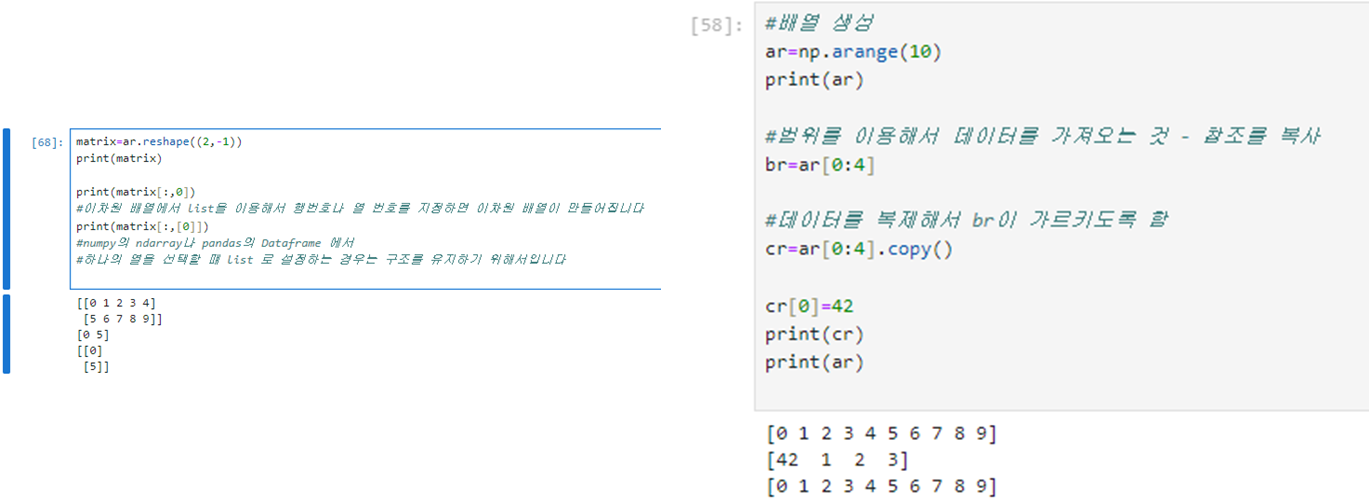
10.배열 차원 변환
=>머신러닝이나 딥러닝을 하다보면 특정한 차원의 데이터를 요구하는 경우가 있습니다.
현재가지고 있는 데이터가 요구하는 차원과 일치하지 않으면 차원을 변경해서 사용해야 합니다.
=>차원을 변경하는데 사용하는 함수는 reshape와 flattern
=>flattern 함수는 무조건 1차원 배열로 반환
=>reshape 함수는 차원을 튜플로 받아서 튜플에 해당하는 차원으로 변경
튜플을 대입하지 않고 -1을 대입하면 1차원으로 변경
튜플로 숫자를 설정할 때 마지막 값은 -1을 설정할 수 있는데 그렇게 하면 마지막 값은 numpy가 추론을 해서 설정합니다.
=>실습

11.배열의 부분 사용
1)하나의 요소 사용 - Indexing
=>일차원 배열의 경우는 배열명[인덱스]의 형태로 접근하는데 앞에서 부터 접근할 떄는 0부터 시작하고 맨뒤에서 접근할때는 -1,-2 이런식으로 접근
=>이차원 배열의 경우는 배열명 [행번호,열번호] 또는 배열명[행번호][열번호]f로도 접근이 가능
=>삼차원 배열 이상은 사용할 수 있는 번호만 늘리면 됩니다.

2)여러 개의 데이터 접근
=>슬라이싱:하나의 행 또는 열 단위로 접근
=>[시작위치:종료다음위치]를 이용하면 범위를 설정해서 접근하는 것이 가능
시작위치를 생략하면 0 종료 다음위치는 생략하면 마지막까지 선택
=>2차원 배열에서 열 번호를 생략하면 열 전체가 되고 행 번호는 생략하고자 할 때 :을 입력해야 합니다.
:은 시작과 종료를 모두 생략했으므로 전체를 의미합니다.

3)인덱싱이나 슬라이싱은 원본 데이터의 참조만 가져오는 것
=>인덱싱이나 슬라이싱으로 가져온 데이터를 변경하면 원본의 데이터를 수정합니다
=>
복사 방법
-참조 복사:데이터의 위치를 복사해주는 것으로 원본이나 사본의 변경이 원본이나 사본에 영향을 줌
프로그래밍에서 금기시 되어 있는 것중 하나입니다.
지역 변수의 참조를 전역 변수에 대입해서 사라지지 않도록 하기 위해서 사용합니다.
-weel copy(얕은 복사)
데이터를 참조를 한번만 찾아가서 데이터를 복사하는 것입니다.
데이터가 다른 데이터의 참조인 경우 원본에 영향을 줍니다
-deep copy(깊은 복사)
데이터의 참조를 재귀적으로 찾아가서 실제 데이터를 복사하는 것입니다.
어떠한 경우에도 다른 데이터에 영향을 줄 수 없습니다
데이터를 다른 변수로 참조하고자 할 때 권장하지만 메모리가 부족한 경우 얕은 복사나 참조를 복사해서 사용하기도 합니다.

4)Fancy Indexing
=>데이터를 선택할 때 list을 이용해서 선택
=>연속된 범위가 아니더라도 선택이 가능
=>Fancy Indexing은 데이터를 복제합니다
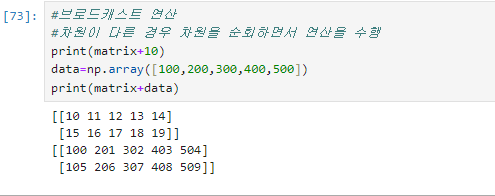
5)조건에 맞는 데이터 선택
=>배열과 하나의 데이터와 연산을 하면 배열의 모든 데이터를 순회하면서 데이터와 연산을 수행합니다
이를 브로드캐스트 연산이라고 합니다.
=>산술 연산을 수행하면 결과가 수치 데이터로 리턴되고 논리 연산을 수행하면 bool의 배열로 리턴됩니다.
=>인덱싱을 할 때 bool 배열을 대입하면 True인 데이터만 추출됩니다.

=>연산을 결합할 때 and,or 을 사용하지 않고 & 와 | 을 사용해야합니다.
=>파이썬에서는 None, 0, 데이터가 없는 벡터 데이터는 False로 간주합니다.
나머지 데이터는 True가 됩니다.

and 와 or은 좌측과 우측의 데이터를 무조건 하나의 데이터로 간주합니다.
& 와 |는 하나의 대이터끼리 연산을 하면 하나의 결과를 만들고 배열끼리 연산을 하면 배열을 만듭니다.




