1.연산
1)포함 여부를 판단하는 연산
=>in: 데이터가 포함되어 있으면 True 아니면 False
=>not in:데이터가 포함되어 있지 않으면 True 아니면 False
2)배열의 모든 요소에 함수를 적용
=>과정
numpy.vectorize(함수)을 이용해서 벡터화된 함수를 생성
벡터화된 함수에 numpy 의 배열을 대입하면 함수의 결과를 다시 배열로 만들어서 리턴합니다.
=>함수는 반드시 리턴해야합니다
=>list에서 사용하는 map 함수와 동일한 작업을 수행합니다

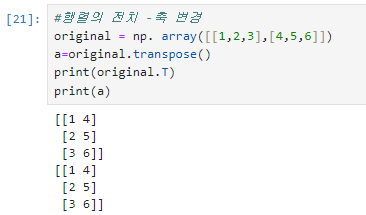
3)배열의 전치와 축변경
=>전치는 행과 열을 반전시키는 것
=>축 변경은 3차원 이상에서 데이터의 축의 순서를 바꾸는 것
=>머신러닝 등을 할 때 data augmentaion 이나 다양한 패턴을 찾고자 할 때 사용
=>행렬은 T라는 속성으로 전치 가능
=>numpy 배열에는 transpose 라는 메서드를 제공해서 메서드에 축의 순서를 설정하면 축의 순서를 변경해줍니다.
축의 순서는 기본적으로 행(0),열(1),면(2),...
=>실제적으로 3차원 이상의 데이터는 차원 변경을 잘 하지 않습니다.
3차원 이상의 차원 변경은 애니메이션에서 수행합니다.
4)랜덤관련
=>머신러닝이나 데이터분석에서 랜덤은 샘플 데이터 추출에 사용
=>프로그래밍 언어에서 랜덤은 seed라고 하는 정수를 설정해서 난수표를 만들고 그 난수표에서 순서대로 데이터를 가져오는 것
실제 랜텀을 만들고자 하면 seed값을 실시간으로 변경해야 합니다.
프로그래밍 언어 별로 seed 값이 기본적으로 실시간으로 변경되는 언어가 있고 고정된 언어가 있습니다.
=>메서드
numpy.random.seed(seed=시드번호):시드 설정
numpy.random(데이터개수):0.0~1.0 사이의 숫자를 개수만큼 추출
numpy.randint(최소,최대,데이터개수): 최소와 최대 사이에서 개수만큼 정수를 추출
numpy.randn(데이터 개수):표준 편차가 1이고 평균이 0인 정규분포에서 데이터 개수만큼 추출
numpy.bionomial(n,p,size):이항분포에서 추출하는데 n은 0부터 나올수 있는 숫자의 범위이고 p는 확률 size은 개수
permutation:정수를 설정해서 랜덤한 배열을 생성
shuffle:랜덤한 배열을 생성
choice():배열에서 복원 추출
=>복원 추출과 비복원 추출
복원 추출은 이번에 생서된 데이터를 그룹에 다시 포함시켜 추출하는 것이고 비복원 추출은 생성된 데이터를 그룹에 포함시키지 않고 추출
=>파이썬은 실행될 때 seed를 설정하지 않으면 seed을 실행 시간을 기준으로 설정합니다.

2.numpy의 메서드
1)메서드의 분류
=>Unary Function:매개변수가 1개인 경우
=>Binary Function:매개변수가 2개인 경우
2)기본 통계 함수
옵션에 axis가 있는데 이 옵션은 2차원 배열에서 행이나 열방향과 관련된 옵
=>sum:합계
=>prod:곱
=>nanprod:none을 1로 간주하고 곱
=>nansum:none을 0으로 간주하고 합

=>mean:평균
=>median:중앙값
=>max:최대
=>min:최소
=>std:표준편차
=>var:분산
=>percentile:백분위수
표준 편차와 분산은 ddof 옵션을 1로 설정해서 비편향 표준 편차와 분산을 구해줍니다.
자유도는 다른 데이터의 값이 결정되면 자동으로 값이 결정되는 데이터의 개수
표준편차와 분산은 ddof 옵션에 따라 값이 다르게 나오는데, 표준편차와 분산은 평균이라는 통계값을 가지고 구하게됩니다.
평균이 결정되면 전체 데이터 개수 -1 만큼의 값을 알게되면 나머지 1개의 값은 자동으로 결정됩니다.
자동으로 결정되는 값을 빼고 계산하거나 포함시켜 계산할 수 있습니다.
이옵션이 ddof 옵션입니다.


3)기술 통계
=>argmin,a rgmax:최소값과 최대값의 인덱스
=>cumsum:누적합
=>cumprod:누적곱
=>diff:차분은 이전 값을 뺸 값, n이라는 옵션으로 차수를 설정할 수 있습니다.

4)소수 관련 함수
=>소수를 버리거나 올림하거나 반올림해주는 함수를 제공
5)숫자 처리 관련 함수
=>절대값, 제곱,제곱근,부호 판별 함수를 제공
6)논리 함수
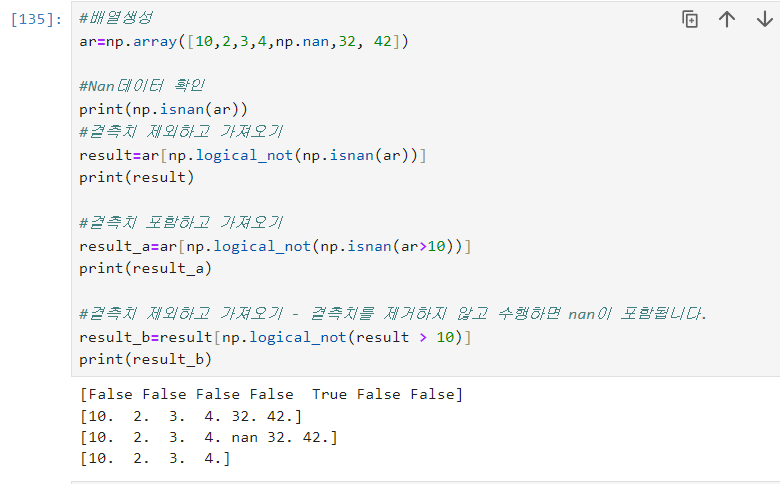
=>numpsy.isnan(배열):배열에None, Null등이 포함여부를 return
=>None을 numpy.nan 으로 표현
=>logical_not 함수는 조건에 맞는 데이터인지 여부를 리턴
7)2개의 배열 가지고 작업하는 함수
=>add,substract,multiply,floor_divide(몫만 가져오기),mod
=>power
=>maximum,fmax,minimum,fmin
f가 붙는 함수는 np.nan을 무시
=>greater,greater_equal,less,less_equal,equal,not_equal:결과가 bool 배열
=>logical_and, logical_or, logiclal_xor
eXclusive OR(배타적 논리합, 같으면 False 다르면 True, True 또는 False 와 False 이면 False 가 되고 True와 False로 데이터가 다르면 True가 되는 연산)
=>where (bool 배열, True 일때 선택할 배열, False일때 선택할 배열)
8)집합 관련 함수
=>unique():중복 제
=>union1d():합집합
=>in1d():데이터 존재 여부 bool배열로 리턴
=>setdiff1d():차집합
=>setxor1d():한쪽에만 존재하는 데이터집합
9)ndarray.sort()

10)배열 분할
=>numpy.split 함수를 이용하는데 배열 그리고 개수와 aixs 옵션을 설정
11)배열 결합
=>numpy.concatenate: 배열 2개와 axis 옵션을 이용해서 합치는 함수
=>hstack, vstack, dstack, stack,r_,c_,tile 함수들이 전부 배열을 연결해주는 함수
=>hstack 행의 개수가 같은 두 개이상의 배열을 옆으로 연결하는 함수
=>vstack 열의 개수가 같은 두 개이상의 배열을 상하로 연결하는 함수
=>dstack 차원을 결합하는 함수
=>stack dstack을 확장한 것으로 차원의 위치(axis)를 직접 설정
=>tile(배열,반복횟수):배열을 반복해서 하나의 배열을 만드는 것

3.배열의 저장과 불러오기
1)배열을 저장
numpy.save('파일경로', 배열)
=>파일의 확장자는 관습적으로 npy를 사용
2)배열의 데이터 불러오기
numpy.load('파일경로')
3)여러개의 배열 저장
numpy.savez('파일경로',이름=데이터,...)
이렇게 저장한 데이터를 불러올때 numpy.load('파일경로','이름')사용
4)머신 러닝 중 자주 사용하는 데이터가 있다면 npy로 저장한 후 호출하는 것이 효율적