Ensemble
1.개요
=>무작위로 선택된 수천 명의 사람에게 복잡한 질문을 하고 대답을 모은다고 가정하면 이렇게 모은 답이 전문가의 답보다 나을 가능성이 높은데 이를 대중의 지혜
=>하나의 좋은 예측기를 이용하는 것보다 일반적인 여러 예측기를 이용해서 예측을 하면 더 좋은 결과를 만들 수 있다는 것으로 이를 앙상블 기법이라고 합니다.
=>DecisionTree 는 전체 데이터를 이용해서 하나의 트리를 생성해서 결과를 예측하지만 RandomForest 은 훈련 세트로 부터 무작위로 각기 다른 서브 세트를 이용해서 여러 개의 트리 분류기를 만들고 예측을 할 때 가장 많은 선택을 받은 클래스나 평균을 이용합니다.
=>머신러닝에서 가장 좋은 모델은 앙상블을 이용하는 모델입니다.
2.투표기반 분류기
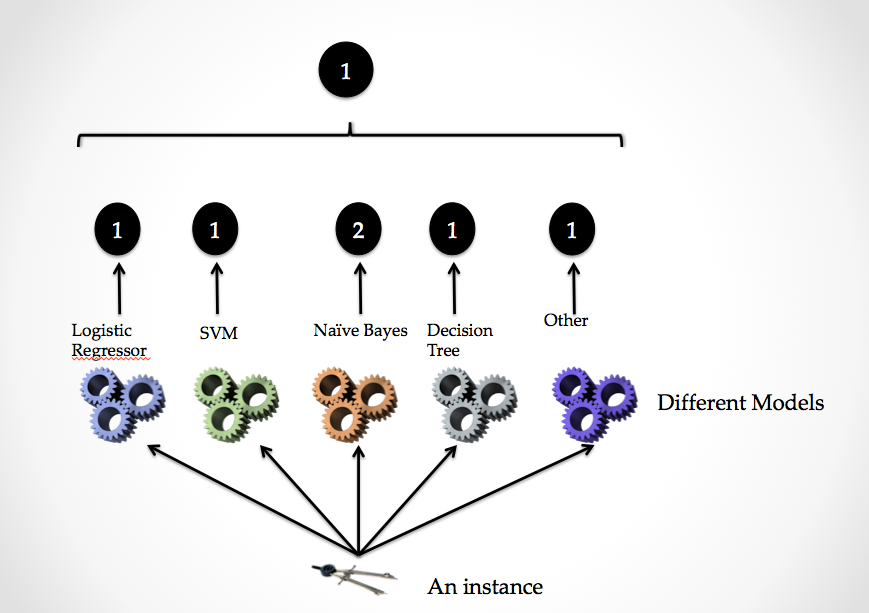
=>분류기 여러개를 가지고 훈련을 한 후 투표를 해서 다수결의 원칙으로 분류를 하는 방식
=>law of large numbers(큰수의 법칙)
동전을 던졌을 때 앞면이 나올 확률이 51%이고 뒷면이 나올 확률이 49%인 경우 일반적으로 1000번을 던진다면 앞면이 510번 뒷면이 490번 나올 것인데 이런 경우 앞면이 다수가 될 가능성은 확률적으로 75%정도되는데 이를 10000번으로 확장하면 확률은 97%가 됩니다.
=>앙상블 기법을 이용할 때 동일한 알고리즘을 사용하는 분류기를 여러 개 만들어도 되고 서로 다른 알고리즘의 분류기를 여러개 만들어도 됩니다.
동일한 알고리즘을 사용하는 분류기를 여러 개 만들어서 사용할 때는 사용하는 훈련데이터가 달라야 합니다.
1)직접 투표 방식
=>분류를 할 때 실제 분류된 클래스를 가지고 선정하는 방식
2)간접 투표 방식
=>분류를 할 때 클래스 별 확률을 가지고 선정
=>이 방식을 사용할 때는 모든 분류기가 predict_proba 함수를 사용할 수 있어야 합니다
=>이 방식의 성능이 직접 투표 방식보다 높음
3)API
=>sklearn.ensemblt.VotingClassifier 클래스
매개변수로는 estimators 가 있는데 여기에 list 로 이름과 분류기를 튜플의 형태로 묶어서 전달
voting 매개변수에 hard 와 soft 를 설정해서 직접 투표 방식인지 간접 투표 방식인지 설정
4)직접 투표 방식을 이용하는 투표 기반 분류기
#사용할 데이터 생성
from sklearn.model_selection import train_test_split #훈련 데이터와 테스트데이터 분할
from sklearn.datasets import make_moons #샘플 데이터 생성
X,y = make_moons(n_samples=500 , noise =0.30, random_state=42)
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=42)
#개별 분류기
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
log_clf = LogisticRegression(solver='lbfgs',random_state=42)
svm_clf = SVC(gamma='scale',random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=100,random_state=42)
#투표 분류기
from sklearn.ensemble import VotingClassifier
voting_clf =VotingClassifier(
estimators=[('lr',log_clf),('svc',svm_clf),('rf',rnd_clf)],
voting='hard'
)
#평가 지표 확인
from sklearn.metrics import accuracy_score
for clf in(log_clf,svm_clf,rnd_clf,voting_clf):
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))
#개별 분류기
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
log_clf = LogisticRegression(solver='lbfgs',random_state=42)
svm_clf = SVC(gamma='scale',random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=100,random_state=42)
#확률을 가지고 계산을 해서 분류
#확률을 가지고 분류를 할 때는 모든 예측기가 predict_proba()를 호출할 수 있어야 합니다
#hard ->soft 로 변경
from sklearn.ensemble import VotingClassifier
voting_clf =VotingClassifier(
estimators=[('lr',log_clf),('svc',svm_clf),('rf',rnd_clf)],
voting='soft'
)
#평가 지표 확인
from sklearn.metrics import accuracy_score
for clf in(log_clf,svm_clf,rnd_clf,voting_clf):
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))
soft 로 바꾸니 오류가 뜸. 확률을 가지고 분류를 할 때는 모든 예측기가 predict_proba()를 호출 할 수 있어서 저 오류 뜨면 dir 를 통해 predict_proba가 있는지 확인해야함.
위에서는 SVM은 기본적으로 predict_proba 를 가지고 있지만 사용을 못합니다. 왜냐면 인스턴스를 만들 때 probability=True 를 추가를 해줘야 확률을 계산합니다.

hard 와 soft 차이
log_clf 2 (0.49 0.51)
svm_clf 2 (0.49 0.51)
rnd_clf 1 (0.60 0.40)
-hard는 앞에 다중투표를 선택하지만 soft 은 확률의 평균을 비교해서 결과를 냄
6)Bagging 과 Pasting
=>개요

-동일한 알고리즘을 사용하고 훈련 세트의 서브 세트를 무작위로 구성해서 예측기 각기 다르게 학습 시키는 것
-bagging (bootstrap aggregating)
-pasting:훈련 세트에서 중복을 허용하지 않고 샘플링 하는 방식
-하나의 샘플링 데이터는 여러개의 예측기에 사용 가능한데 배깅은 하나의 예측기에 동일한 샘플이 포함될 수 있고 페이스팅은 하나의 예측기 안에는 동일한 샘플이 포함 될 수 없음
-모든 예측기가 훈련을 마치면 모든 예측기의 예측을 모아서 새로운 샘플에 대한 예측을 생성하는데 이때 수집 함수는 분류일 때는 최빈값이고 회귀에 대해서는 평균을 계산
-개별 예측기는 원본 데이터 전체로 훈련한 것보다 편향이 심하지만 수집 함수를 통과하면 편향과 분산이 모두 감소
- 예측기들은 동시에 다른 CPU 코어나 컴퓨터에서 병렬로 학습이 가능
=>API
-Bagging Classifier
-기본적으로 bagging 을 사용하는데 bootstrap이라는 매개변수에 False 로 설정하면 Pasting을 수행
샘플이 많으면 페이스팅을 사용하고 샘플의 개수가 적으면 bagging 을 사용
-n_jobs 매개변수를 sklearn이 훈련과 예측에 사용할 CPU 코어 수를 설정(-1을 설정하면 모든 코어를 사용)
-클래스 확률을 계산할 수 있는 predict_proba 함수를 가진 경우에는 분류에서 간접 투표 방식을 사용할 수 있음
- n_estimators 매개변수에 예측기의 개수를 설정
- max_sample 매개변수에 샘플의 최대 개수를 지정
=>DecisionTree 와 DecisionTree의 Bagging 의 정확도를 확인
#결정 트리의 모델의 정확도
from sklearn.tree import DecisionTreeClassifier
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train,y_train)
y_pred = tree_clf.predict(X_test)
print(accuracy_score(y_test,y_pred))0.856의 정확도
from sklearn.ensemble import BaggingClassifier
#bootstrap이 True면 배깅 False면 Pasting
#각 트리 샘플 데이터 개수는 최대 100개이고 복원 추출을 수
bag_clf = BaggingClassifier(DecisionTreeClassifier(),random_state=42,
n_estimators=500,max_samples=100,bootstrap=True)
bag_clf.fit(X_train,y_train)
y_pred = bag_clf.predict(X_test)
print(accuracy_score(y_test,y_pred))0.904 의 정확도
일반적으로 앙상블의 예측이 결정 트리 하나의 예측보다 일반화가 잘 됨
앙상블은 비슷한 편향을 가지지만 더 작은 분산을 만듬
=>부트스트래핑은 각 예측기가 학습하는 서브 세트에 다양성을 증가시키므로 배깅이 페이스팅보다 편향이 조금 더 높지만 다양성을 추가하게 되면 예측기 들의 상관관계를 줄이므로 앙상블의 분산을 감소시킴
일반적으로 배깅이 페이스팅 보다 더 좋은 성능을 나타내지만 되도록이면 교차 검증으로 모두 평가
=>oob 평가
- 배깅은 어떤 샘플은 한 예측기를 위해서 여러 번 샘플링 되고 어떤 데이터는 전혀 선택되지 않을 수 있는데 확률적으로 보면 전체 데이터에서 63%정도만 사용
-선택되지 않은 37%를 oob(out-of-bag)샘플이라고 부르며 예측기마다 데이터가 다름
-예측기가 훈련 하는 동안에는 37%의 데이터를 사용하지 않기 때문에 이 데이터를 이용해서 검증 작업을 수행할 수 있음
-앙상블의 평가는 각 예측기의 oob 평가를 평균해서 얻음
-BaggingClassifier 를 만들 때 oob_score=True 로 설정하면 훈련이 끝난 후 자동으로 oob 평가를 수행하고 그 결과를 oob_score_ 에 저장
# 테스트 데이터를 별도로 생성하지 않고 훈련에 사용하지 않은 데이터를 이용해서 검증
bag_clf = BaggingClassifier(DecisionTreeClassifier(),random_state=42,
n_estimators=500,max_samples=100,bootstrap=True,oob_score=True)
bag_clf.fit(X_train,y_train)
print(bag_clf.oob_score_)
=>BaggingClassifier 는 특성 샘플링도 지원
-max_features, bootstrap_features라는 매개변수를 이용해서 특성 샘플링을 지원
최대 사용하는 feature의 개수와 feature의 중복 허용 여부를 설정
-각 예측기는 무작위로 선택한 입력 특성의 일부분으로 훈련
일반적인 데이터에서는 잘 사용되지 않고 이미지 와 같은 고차원의 데이터세트에서 이용
-훈련 특성과 샘플을 모두 샘플링 하는 것을 Random Patches Method 라고 합니다.
-샘플은 모두 사용하고 특성만 샘플링하는 것은 Random Subspaces Method 라고 합니다.
-특성 샘플링을 하게 되면 더 다양한 예측기가 만들어지므로 편향을 늘리는 대신 분산을 낮춤
3.RandomForest
1)개요
=>같은 알고리즘으로 여러 개의 분류기를 만들어서 보팅으로 최종 결정하는 배깅의 대표적인 알고리즘
=>알고리즘은 DecisionTree를 이용
=>Bootstrap Sample를 생성해서 샘플 데이터 각각에 결정 트리를 적용한뒤 학습 결과를 취합하는 방식으로 작동
=>각각의 DecisionTree 들은 전체 특성중 일부만 학습
=>random_state 값에 따라 예측이 서로 다른 모델이 만들어지는 경우가 있는데 트리의 개수를 늘리면 변동이 적어지게 됩니다.
=>각 트리가 별개로 학습이 되므로 n_jobs를 이용해서 동시에 학습하도록 할 수 있습니다.
2)장점
=>단일 트리의 단점을 보완
=>매개변수 튜닝을 하지 않아도 잘 작동하고 데이터의 스케일을 맞출 필요가 없음
=>매우 큰 데이터 세트에도 잘 작동
=>여러 개의 CPU 코어를 사용하는 것이 가능
3)단점
=>대량의 데이터에서 수행하면 시간이 많이 걸림
=>차원이 매우 높고(특성의 개수가 많고) 희소한 데이터(유사한 데이터가 별로 없는) 에는 잘 작동하지 않은데 이런 경우에는 선형 모델을 사용하는 것이 적합
희소한 데이터는 리프 노드에 있는 샘플의 개수가 적은 경우
4)배깅과 랜덤 포레스트 비교
=>랜덤 포레스트는 Decision Tree의 배깅입니다.
배깅에서 부트스트래핑을 사용하고 특성 샘플링을 이용하는 것이 Random Forest
부트스트래핑은 하나의 훈련 세트에서 일부분의 데이터를 추출하는 복원 추출을 이용해서 수행해서 하는 방식이고 특성 샘플링은 샘플링 비율을 설정해서 특성을 전부 이용하지 않고 일부분만을 이용해서 학습하는 방식입니다.
랜덤 포레스트에서는 특성의 비율을 기본적으로 제곱근 만큼 사용합니다.
bag_clf = BaggingClassifier(DecisionTreeClassifier(max_features='sqrt',
max_leaf_nodes=16),
n_estimators=500,random_state=42)
#500개의 트리가 생성해서 예측
bag_clf.fit(X_train,y_train)
y_pred =bag_clf.predict(X_test)
from sklearn.ensemble import RandomForestClassifier
rnd_clf =RandomForestClassifier(n_estimators=500, max_leaf_nodes=16,
n_jobs=-1, random_state=42)
#500개의
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
print(np.sum(y_pred == y_pred_rf)/len(y_pred))
#2개의 결과가 모두 일치하면 1.0인데 1.0이 나옴
=>RandomForest 알고리즘은 트리의 노드를 분할할 때 전체 특성 중에서 최선의 특성을 찾는 것이 아니고 무작위로 선택한 특성 후보중에서 최적의 특성을 찾는 식으로 무작위성을 주입하는데 이러한 방식은 트리의 다양성을 높여서 편향을 손해보는 대신에 분산을 낮추는 방식으로 더 좋은 모델을 만들어 갑니다.
5)특성 중요도
=>트리 모델은 특성의 상대적 중요도를 측정하기 쉬움
=>sklearn은 어떤 특성을 사용한 노드가 평균적으로 불순도를 얼마나 감소시켰는지 확인해서 특성의 중요도를 판단
가중치의 평균이며 노드의 가중치는 연관된 훈련 샘플의 수와 같음
훈련 샘플의 수를 전체 합이 1이 되도록 결과값을 정규화한 후 feature_importances_에 저장
from sklearn.datasets import load_iris
iris = load_iris()
#iris데이터는 data라는 속성에 feature를 가지고 있는데 4가지
#target 이라는 속성의 꽃의 종류에 해당하는 범주형 데이터를 가지고 있음 - 3가지
#feature_names 속성에 feature이름이 저장되어 있고 class_names 에 클래스 이름이 저장
rnd_clf = RandomForestClassifier(n_estimators=500, random_state=42)
rnd_clf.fit(iris.data, iris.target)
for score, name in zip(rnd_clf.feature_importances_, iris['feature_names']):
print(round(score, 2), name)
어떻게 계산되었는지는 모르지만 petal width 와 petal length가 중요한 특징임을 알 수 있습니다.
=>이미지에서 특성의 중요도를 확인해보면 이미지의 어느 부분이 다르게 보이는지 확인이 가능
MNIST 데이터에서 분류를 할 떄 가장 크게 다른 부분은 가운데 부분
특성의 중요도를 파악한 후 전체 feature를 전부 사용하지 않고 일부분만 사용해도 거의 동일한 정확도를 만들어 낼 수 있습니다.
# extra code – this cell generates and saves Figure 7–6
from sklearn.datasets import fetch_openml
X_mnist, y_mnist = fetch_openml('mnist_784', parser='auto', return_X_y=True, as_frame=False)
rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42)
rnd_clf.fit(X_mnist, y_mnist)
heatmap_image = rnd_clf.feature_importances_.reshape(28, 28)
plt.imshow(heatmap_image, cmap="hot")
cbar = plt.colorbar(ticks=[rnd_clf.feature_importances_.min(),
rnd_clf.feature_importances_.max()])
cbar.ax.set_yticklabels(['Not important', 'Very important'], fontsize=14)
plt.axis("off")
save_fig("mnist_feature_importance_plot")
plt.show()
보다시피 이미지의 외곽부분은 분류에 미치는 효과가 거의 없고 중앙 부분의 데이터가 이미지 분류에 영향을 많이 주므로 이 이미지는 가운데 부분만 잘라서 학습을 해도 무방합니다.
이런경우 이미지를 자르면 feature의 개수가 줄어들어서 나중에 학습 할때 학습 시간이 줄어들고 예측을 할 때 일반화 가능성이 높아집니다.
6)하이퍼 파라미터 튜닝
=>Random Forest는 Decision Tree 처럼 하이퍼 파라미터가 다양
=>GridSearchCV 나 RandomSearchCV 를 이용해서 최적의 파라미터를 찾는 작업이 중요합니다
=>샘플의 개수가 많거나 피처의 개수가 많으면 시간이 오래 걸립니다
따라서 n_jobs 을 -1 로 설정을 해주는 것이 좋습니다.
RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None,
min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0, max_features='sqrt',
max_leaf_nodes=None, min_impurity_decrease=0.0,
bootstrap=True, oob_score=False, n_jobs=None,
random_state=None, verbose=0, warm_start=False,
class_weight=None, ccp_alpha=0.0, max_samples=None)
|
RandomForest 는 많은 하이퍼파라미터를 가지고 있어서 하이퍼파라미터 튜닝은 GridSearch 로 진행하는게 좋음
from sklearn.datasets import load_iris
iris = load_iris()
#하이퍼파라미터 튜닝을 위한 파라미터 생성
#기본은 dictionary(문자열- 하이퍼 파라미터 이름과 리스트- 값들로 구성)
#dictionary 내부의 list 들은 전부 곱한만큼의 조정
params ={
'n_estimators':[100,200,300],
'max_depth':[4,6,8,10],
'min_samples_leaf':[4,6,10]
}
from sklearn.model_selection import GridSearchCV
#모델 생성
rf_clf = RandomForestClassifier(random_state=42,n_jobs=-1)
#GridSearchCV 인스턴스 생성
grid_cv = GridSearchCV(rf_clf,param_grid=params,cv=3,n_jobs=-1)
#훈련
grid_cv.fit(iris.data, iris.target)
#최적의 파라미터
print("최적의 파라미터:",grid_cv.best_params_)
max_depth와 min_samples_leaf 의 경우, 최소값이 젤 성능이 좋게 나왔기 떄문에 더 좋은 값이 있는지 다른 변수들을 추가해서 수행해봐야 합니다. 최적의 분류기를 새로 학습 시키는게 아니라 grid_cv.best_estimator_ 을 활용해서 바로 도출 가능
#최적의 분류기
print("최적의 분류기:",grid_cv.best_estimator_)
7)Extra Tree
=>RandomForest 에서는 트리를 만들 때 무작위로 특성의 서브 세트를 만들어서 분할에 이용하는데 이 때 분할을 하기 위해서 어떤 특성을 이용해서 분할 하는 것이 효과적인 판단하는 작업을 거치게 됩니다.
최적의 특성을 찾는게 아닌 일단 아무 특성이나 선택을 해서 분할 하고 그 중에서 최상의 분할을 선택하는 방식의 트리
무작위성을 추가하는 방식
=>RandomForest 에 비해서 훈련 속도가 빠름
성능은 어떤 것이 좋을지 알 수 없기 떄문에 모델을 만들어서 비교를 해봐야 합니다.
=>API는 sklearn의 ExtraTreesClassifier
=>사용법은 RandomForest 와 동일
from sklearn.ensemble import ExtraTreesClassifier
iris = load_iris()
ET_clf = ExtraTreesClassifier(n_estimators=500, random_state=42)
ET_clf.fit(iris.data, iris.target)
for score, name in zip(ET_clf.feature_importances_, iris['feature_names']):
print(round(score, 2), name)
4.Boosting
=>boosting (원래 이름은 hypothesis boosting)은 약한 학습기 를 여러 개 연결해서 강한 학습기를 만드는 앙상블 방법
Bagging 이나 Pasting은 여러 개의 학습기를 가지고 예측을 한 후 그 결과를 합산해서 예측
=> 앞의 모델을 보완해 나가면서 예측기를 학습시키는 것
=>종류는 여러가지
1.Ada-Boost

1)개요
=>이전 모델이 과소적합했던 훈련 샘플의 가중치를 더 높이는 것으로 이방식을 이용하면 새로 만들어진 예측기는 학습하기 어려운 샘플에 점점 더 맞춰지게 됨
=>먼저 알고리즘의 기반이 되는 첫번째 분류기를 훈련 세트를 가지고 훈련시키고 예측을 만들고 그 다음에 알고리즘이 잘못 부류한 훈련 샘플의 가중치를 상대적으로 높이고 두번째 분류기는 업데이트 된 가중치를 사용해서 훈련세트에서 다시 훈련하고 다시 예측을 만들고 그 다음에 가중치를 업데이트 하는 방식
2)sklearn에서는 AdaBoostClassifier 를 제공
=>기반 알고리즘이 predict_proba 함수를 제공한다면 클래스 확률을 기반으로 분류가 가능
이 때는 algorithm이라는 매개변수에 SAMME.R이라는 값을 설정하면 됩니다.
확률을 이용하는 방식이 예측 값을 이용하는 방식보다 성능이 우수할 가능성이 높음
#잘못 예측된 샘플에 가중치를 부여해서 학습하는 방식
#사용할 데이터 생성
from sklearn.model_selection import train_test_split #훈련 데이터와 테스트데이터 분할
from sklearn.datasets import make_moons #샘플 데이터 생성
X,y = make_moons(n_samples=500 , noise =0.30, random_state=42)
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=42)
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1),
n_estimators=200,algorithm='SAMME.R',
learning_rate=0.5,random_state=42)
ada_clf.fit(X_train,y_train)
learning_rate(학습률)은 훈련을 할 때 step의 크기로 이 값이 크면 최적화에 실패할 가능성이 높아지고 낮으면 최적화에는 성공할 가능성이 높지만 훈련 속도가 느려지고 과대적합할 가능성이 있음
2.Gradient Boosting
1)개요
=>여러 개의 결정트리를 묶어서 강력한 모델을 만드는 앙상블 기법
=>회귀와 분류 모두 가능
=>RandomForest 도 여러개의 결정 트리를 이용하는 것 같지만 Gradient Boosting은 이전 트리의 오차를 보완하는 방식으로 순차적으로 트리를 생성
=>무작위성이 없는 대신(이전에 오분류한 샘플에 가중치를 부여) 강력한 사전 가지 치기를 사용
=>보통 1~5 정도 깊이의 트리를 사용하기 때문에 메모리를 적게 사용하고 예측도 빠름
=>RandomForest 보다 매개변수 설정에 조금 더 민감하지만 잘 조정하면 더 높은 정확도를 제공
=>Ada Boost와 다른 점은 가중치 업데이트를 경사 하강법을 이용
=>수행 시간이 오래 걸리고 하이퍼 파라미터 튜닝도 조금 어려움
수행 시간의 문제가 GBM의 단점
2)API
=>sklearn에서는 GradientBoostingClassifier 클래스를 제공
from sklearn.ensemble import GradientBoostingClassifier
import time
#수행시간
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=42)
gb_clf.fit(X_train,y_train)
gb_pred = gb_clf.predict(X_test)
print("GBM수행시간:",(time.time()-start_time))
print("GBM 정확도:",accuracy_score(y_test,y_pred))
from sklearn.ensemble import RandomForestClassifier
start_time = time.time()
rnd_clf =RandomForestClassifier(n_estimators=500, max_leaf_nodes=16,
n_jobs=-1, random_state=42)
rnd_clf.fit(X_train,y_train)
rnd_pred = rnd_clf.predict(X_test)
print("RF수행시간:",(time.time()-start_time))
print("RF 정확도:",accuracy_score(y_test,rnd_pred))
3)하이퍼 파라미터
=>max_depth:트리의 깊이
=>max_features:사용하는 feature의 비율
=>n_estimators: 학습기의 개수로 기본은 100
=>learning_rate: 학습률로 기본은 0.1 이며 0에서 1사이로 설정 가능
=>subsample: 샘플링 비율로 기본값은 1인데 과대적합 가능성이 보이면 0.5 정도로 숫자를 낮춤
기본은 모든 데이터를 가지고 학습
#하이퍼 파라미터 튜닝
from sklearn.model_selection import GridSearchCV
#사용할 hyperparameter 설정
params ={
'n_estimators':[100,200,300,400,500],
'learning_rate':[0.05,0.1]
}
#cv의 숫자는 교차 검증에 사용할 fold 개수로 실제 사용할 때는 조금 더 큰 값을 사용
#verbose는 훈련과정의 로그 출력 여부
grid_cv = GridSearchCV(gb_clf, param_grid=params , cv=2,verbose=1)
grid_cv.fit(X_train,y_train)
print("최적의 파라미터:",grid_cv.best_params_)
print('최적의 정확도:',grid_cv.best_score_)
4)titanic 데이터 적용
import seaborn as sns
df =sns.load_dataset('titanic')
df.info()
위긔 결과로 deck 열에는 결측치가 많고 embarked 와 embark_town은 동일한 의미를 갖는 컬럼
#deck열에는 결측치가 많고 embarked 와 embark_town은 동일한 의미를 갖는 컬럼
#2개의 열 제거
rdf = df.drop(['embark_town','deck'],axis=1)
rdf.info()
#age 열에는 결측치가 170여개 정도 존재 - 결측치가 있는 행을 제거
rdf = rdf.dropna(subset=['age'],how='any',axis=0)
rdf.info()
#embark 에는 2개의 결측치가 존재 - 범주형이므로 최빈값으로 치환
#치환할때 KNN을 이용해서 하는 것도 좋은 방법
#embark 열에서 각 범주의 개수를 구한 후 가장 큰 값의 인덱스를 가져오기
most_freq = rdf['embarked'].value_counts(dropna=True).idxmax()
rdf['embarked'].fillna(most_freq,inplace=True)
rdf.info()
=>분석에 사용할 열을 선택
#분석에 사용할 열 선택
#타겟은 survived 라서 반드시 선택
ndf = rdf[['survived','pclass','sex','age','sibsp','parch','embarked']]
ndf.info()
=>sex 와 embarked 는 자료형이 object
ndf['sex'].value_counts()
ndf['embarked'].value_counts()
=>원 핫 인코딩을 수행( 라벨 인코딩도 가능)
# sex one-hot encoding
onehot_sex = pd.get_dummies(ndf['sex'])
ndf = pd.concat([ndf,onehot_sex],axis=1)
ndf.drop(['sex'],axis=1,inplace=True)
#embarked one-hot encoding
#town_어쩌구저꾸로 변환 가능
onehot_embarked = pd.get_dummies(ndf['embarked'],prefix='town')
ndf = pd.concat([ndf,onehot_embarked],axis=1)
ndf.drop(['embarked'],axis=1,inplace=True)
=>학습 준비를 위해 Scaling 및 split
#feature 와 target 생성
X=ndf.drop(['survived'],axis=1)
y=ndf['survived']
#feature의 scale확인
X.describe() #숫자 컬럼 기술통계량
#숫자 컬럼의 값들의 범위가 차이가 많이 나면 scaling을 수행하는 것이 좋습니다.
from sklearn import preprocessing
X=preprocessing.StandardScaler().fit_transform(X)
#X.describe()는 numpy 라 못함
X
#훈련과 test 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train,y_test = train_test_split(X,y,test_size=0.3,
random_state=42)
=>모델을 생성하고 훈련한 후 평가 지표를 출력
#모델 생성하고 훈련하고 평가지표 출력
from sklearn.ensemble import GradientBoostingClassifier
gbrt = GradientBoostingClassifier(random_state=42)
gbrt.fit(X_train,y_train)
print("훈련 데이터의 정확도:",gbrt.score(X_train,y_train))
print("훈련 데이터의 정확도:",gbrt.score(X_test,y_test))
=>feature importance 확인
columns = ['pclass','sex','age','sibsp','parch','embarked']
for score, name in zip(gbrt.feature_importances_, columns[:]):
print(round(score, 2), name)
5)특징
=>일반적으로 성능이 우수하지만 처음부터 이모델을 사용하는 것을 권장하지는 않는데 이유는 훈련식나이 길기 때문
=>RandomForest 나 linear model을 이용해서 훈련하고 평가한후 성능이 나쁘거나 경진대회에서 마지막 성능까리 뽑아내고자 할 때 이용
=>트리모델이므로 희소한 고차원 데이터에는 잘 작동하지 않음
=>가장 중요한 파라미터는 n_estimators 와 learning_rate, max_depth
6)회귀에 적용
=>분류에서는 잘못 분류된 데이터를 다음 학습기에서 다시 예측하는 형태로 구현
=>회귀에서는 첫번쨰 결정 트리 모델을 가지고 학습 한 후 잔차(residual)을 구한 후 다음 결정 트리 모델일 잔차를 타겟으로 해서 다시 학습을 수행하고 잔차를 구한 후 이 결과를 가지고 다음 결정 트리 모델이 훈련을 하는 방식으로 구현
예측값은 모든 결정 트리 모델의 예측을 더하면 됩니다.
=>GradientBoostingRegressor 을 제공
#샘플 데이터 생성
np.random.seed(42)
X=np.random.rand(100,1)-0.5
y=3* X[:,0]**2 +0.05*np.random.randn(100)
#첫번쨰 트리를 가지고 훈련
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2,random_state=42)
tree_reg1.fit(X,y)
print(X[0])
print(y[0])
print(tree_reg1.predict(X[[0]]))
#첫번째 모델의 잔차
y2= y-tree_reg1.predict(X)
#잔차를 타겟으로 훈련
tree_reg2=DecisionTreeRegressor(max_depth=2,random_state=42)
tree_reg2.fit(X,y2)
print(tree_reg2.predict(X[[0]]))
#두번째 모델의 잔차
y3= y2-tree_reg2.predict(X)
#잔차를 타겟으로 훈련
tree_reg3=DecisionTreeRegressor(max_depth=2,random_state=42)
tree_reg3.fit(X,y3)
print(tree_reg3.predict(X[[0]]))
7)확률적 그라디언트 부스팅
=>훈련 샘플의 비율을 설정하는 것
=>subsample 이라는 매개변수에 훈련 샘플의 비율을 설정
=>편향이 높아지는 대신 분산이 낮아지고 훈련속도가 빨라집니다.
3.Histogram -based Gradient Boosting
1)개요
=>sklearn에서 제공하는 다른 형태의 Gradient Boosting
=>입력 특성을 구간으로 나누어서 정수로 대체하는 방식
=>구간의 개수는 max_bins 속성으로 설정이 가능한데 기본값은 255 이고 그 이상의 값은 안됨
=>구간 분할을 사용하면 학습 알고리즘이 평가해야 하는 임계값의 개수가 줄어들게 되고 정수로 작업을 수행하기 떄문에 속도가 빠름
=>대규모 데이터셋에서 빠르게 훈련을 하고자 할 때 사용
2)API
=>HistGradientBoostingRegressor 와 HistGradientBoostingClassifier
=>사용방법은 거의 동일
3)일반 그라디언트 부스팅과의 차이점
=>샘플의 개수는 10000개가 넘으면 자동 조기 종료 기능이 활성화
조기 종료 기능은 훈련을 하다가 현재 점수보다 그다지 좋아지지 않으면 훈련을 종료
=>n_estimators 매개변수 대신에 max_iter 로 변경
=>조정할 수 있는 파라미터도 줄어듬
from sklearn.ensemble import HistGradientBoostingClassifier
hgbrt = HistGradientBoostingClassifier(max_iter=100,
max_depth=3,random_state=42)
hgbrt.fit(X_train,y_train)
print("훈련 데이터의 정확도:",hgbrt.score(X_train,y_train))
print("테스트 데이터의 정확도:",hgbrt.score(X_test,y_test))
4.XGBoost(eXtra Gradient Boosting)
1)개요
=>https://github.com/dmlc/xgboost
=>트리 기반의 앙상블 학습
=>캐글 경연대회에서 상위를 차지한 경우에 이 모델을 많이 사용
=>분류에 있어서 다른 머신러닝 알고리즘 보다 뛰어나 예측 성능을 보임
=>Gradient Boosting 에 기반하고 있는데 느린 훈련 속도와 과적합 규제에 대한 부분을 보완
=>병렬 학습이 가능
=>자체 내장된 교차 검증을 수행
=>결측치도 자체적으로 처리
=>하이퍼 파라미터의 종류가 매우 많습니다.
2)하이퍼 파라미터
=>일반 파라미터: 일반적으로 실행 시 스레드의 개수나 silent 모드 등 선택을 위한 파라미터로 기본값을 거의 변경하지 않음
booster:gbtree(tree모델) .gblinear(선형 모델)
silent:메세지 출력하고싶으면 0 , 아니면 1
nthread:CPU의 실행 스레드 개수 조정. 일부 CPU만 사용 가능함
=>부스터 파라미터:트리 최적화, 규제등의 파라미터
learning_rate,max_depth,sub_sample:아는 의미
num_boost_rounds:n_estimators와 같은 파라미터
min_child_weight:분할 문제. 값이 크면 prunning을 많이 진행
gamma:손실값. 값을 크게 하면 과적합 X
lambda:L2
alpha:L1
등등
=>학습 태스크 파라미터:학습 수행 시의 객체 함수나 평가를 위한 지표등을 설정
objective: 어떤 모델을 할지 선택가능
binary:logistic, multi:softmax,multi:softprob
eval_metric:검증에 사용하는 함수 정의
rmse, mae,mogloss,error,auc
3)설치
pip install xgboost
4)훈련과 검증에 사용하는 데이터
=>다른 모델들과 달리 DMatrix 라는 API를 이용해서 행렬의 형태를 변환해서 사용
data라는 매개변수에 feature를 label이라는 매개변수에 타겟을 설정해주어야 합니다.
5)위스콘 신 유방암 데이터 세트에 XGBoost 적용
=>데이터는 x-ray 촬영한 사진을 수치화한 데이터
사진을 직접 이용하지 않고 사진에서 필요한 데이터를 추출해서 수치화해서 사용하는 경우가 많음
이러한 라벨링 작업에 OpenCV를 많이 활용합니다
타겟이 0 이면 악성(malignant)이고 1이면 양성(benign)
=>데이터 가져오기
from sklearn.datasets import load_breast_cancer
dataset = load_breast_cancer()
X_features = dataset.data
y_label = dataset.target
cancer_df = pd.DataFrame(data=X_features, columns = dataset.feature_names)
cancer_df['target']=y_label
#cancer_df.info()
cancer_df.head()
=>레이블 값의 분포를 확인 - 층화 추출이나 오버&언더 샘플링 여부를 판단하기 위해서
#레이블 분포 확인
print(cancer_df['target'].value_counts())
# 1 357 0 212
X_train,X_test,y_train,y_test= train_test_split(X_features,y_label,test_size=0.2,
random_state=42)
print(X_train.shape,X_test.shape)
=>xgboost 가 사용할 수 있는 형태로 데이터 변경
#xgboost 가 사용할 수 있는 형태로 데이터 변경
import xgboost as xgb
from xgboost import plot_importance
dtrain = xgb.DMatrix(data=X_train,label=y_train)
dtest = xgb.DMatrix(data=X_test,label=y_test)
=>하이퍼 파라미터 생성
#하이퍼 파라미터 생성
#objective에 이진 분류인지 멀티 클래스 분류인지 설정
params ={'max_depth':3,
'eta':0.1,
'objective':'binary:logistic',
'eval_matric':'logloss'}
#예측 횟수
num_rounds = 500
#모델 생성
#내부적으로 검증할 때 사용할 데이터 명시
#train이 훈련 데이터, eval이 검증 데이터가 됩니다
#조기 종료 기능을 설정
#일반 gradient boosting은 예측기의 개수를 설정하면 무조건 예측기의 개수만큼 훈련
#중간에 조기 종료를 하려면 매 학습시 마다 점수를 가져와서 점수가 더 이상 좋아지지 않으면
#종료되도록 알고리즘을 구현해야하는데 xgboost 는 hyperparameter에 자체적으로 존재
wlist = [(dtrain,'train'),(dtest,'eval')]
xgb_model =xgb.train(params=params,dtrain=dtrain,num_boost_round= num_rounds,
evals=wlist,early_stopping_rounds=100)
=>예측을 수행하면 1로 판정할 확률을 리턴
예측값을 출력할 떄는 클래스로 변환해서 출력을 해야합니다.
#예측
pred_probs = xgb_model.predict(dtest)
print(np.round(pred_probs[:10],3))
#확률을 범주형으로 변환
preds = [1 if x>0.5 else 0 for x in pred_probs]
print(preds[:10])
=>범주형의 평가 지표를 출력: 정확도,정밀도, 재현율, F1 score ,roc_auc_score
#평가 지표 출력
from sklearn.metrics import confusion_matrix,accuracy_score
from sklearn.metrics import precision_score,recall_score
from sklearn.metrics import f1_score,roc_auc_score
#오차 행렬 출력
confusion = confusion_matrix(y_test,preds)
print("오차행렬")
print(confusion)
print("\n")
#정확도: 전체 데이터에서 맞게 분류한 것의 비율
accuracy = accuracy_score(y_test,preds)
print("정확도:",accuracy)
#정밀도:검색된 문서들중에 관련있는 문서들의 비율
#True로 판정한 것중 실제 True 인 것의 비율
precision = precision_score(y_test,preds)
print("정밀도:",precision)
#재현율:관련되 문서들 중 검색된 비율
#실제 True인 것중 True로 판정한 것의 비율
recall = recall_score(y_test,preds)
print("재현율",recall)
#F1score -recall과 precision의 조화평균
f1_score = f1_score(y_test,preds)
print("f1_score:",f1_score)
#roc_auc_score
#area under curve 의 약자로 그래프의 곡선 아래 면적
#1에 가까울 수록 좋은 성능
roc_auc = roc_auc_score(y_test,preds)
print("roc_auc:",roc_auc)
=>feature의 중요도 출력
#feature 의 중요도 출력
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10,10))
plot_importance(xgb_model,ax=ax)
비율이 아닌 점수 형태로 나옴
5.Light GBM

1)개요
=>XGBoost 는 매우 뛰어난 부스팅 알고리즘이지만 여전히 학습시간이 김
=>GridSearchCV를 이용해서 hyperparameter 튜닝을 하다보면 수행시간이 너무 오래 걸려서 많은 파라미터를 튜닝하기에 어려움을 겪게 됩니다.
=>XGBoost 보다 학습에 걸리는 시간이 훨씬 적고 메모리 사용량도 상대적으로 적으면서도 비슷한 성능을 발휘
=>10000건 이하의 데이터 세트에 적용하면 과대적합이 발생할 가능성이 높음
=>다른 Boosting 알고리즘은 균형 트리를 만들려고 하는 경향이 있는데 이유는 과대적합을 방지하기 위해서인데 이것 때문에 훈련 시간이 오래 걸림
=>LightGBM은 균형 잡힌 트리를 만들려고 하지 않고 리프 중심 트리 분할을 수행합니다.
불균형 트리를 만들어서 사용을 합니다
데이터가 아주 많다면 리프에 배치되는 샘플의 개수도 많아질 가능성이 높기 때문에 과대적합이 잘 발생하지 않음
2)설치
pip install lightgbm
pip install lightfbm ==3.3.2
=>pip install lightgbm 로 설치하면 4.0 버전 설치가 됩니다.
이 버전과 3.x 대 버전이 매개변수가 다릅니다.
조기 종료가 이전에는 파라미터 형태 였는데 지금은 콜백의 형태로 변경되었습니다.
로그 출력 옵션이 없어졌습니다.
=>현재 인터넷을 검색하거나 동영상 강의에서는 전부 3.x 버전을 사용합니다.
=>되도록이면 최신 버전을 설치(학습을 할 때는 최신 버전을 사용하는 것이 좋고 개발을 할 때는 최신버전 보다는 하나정도 아래 버전이 좋습니다.)
3)hyperparamter는 xgboost와 거의 유사
=>다른 점은 파이썬 래퍼를 사용하면 데이터를 이전처럼 numpy의 ndarray 로 지정할 수 있습니다.
4)위스콘 신 유방암 데이터에 lightgbm을 적용
from lightgbm import LGBMClassifier
from sklearn.datasets import load_breast_cancer
dataset = load_breast_cancer()
X_features = dataset.data
y_label = dataset.target
X_train,X_test,y_train,y_test= train_test_split(X_features,y_label,test_size=0.2,
random_state=42)
#검증에 사용할 데이터 생성
evals= [(X_test,y_test)]
#모델을 생성해서 훈련
lgbm_wrapper = LGBMClassifier(n_estimators=1000)
'''
4점대 버전은 이걸 사용해야함
lgbm_wrapper.fit(X_train,y_train,early_stopping_rounds=100,
callbacks=[lightgbm.early_stopping(stopping_rounds=100)],
eval_metric='logloss',eval_set=evals)
'''
lgbm_wrapper.fit(X_train,y_train,early_stopping_rounds=100,
eval_metric='logloss',eval_set=evals)
=>성능 평가
#예측
pred_probs = lgbm_wrapper.predict(X_test)
print(np.round(pred_probs[:10],3))
#평가 지표 출력
from sklearn.metrics import confusion_matrix,accuracy_score
from sklearn.metrics import precision_score,recall_score
from sklearn.metrics import f1_score,roc_auc_score
#오차 행렬 출력
confusion = confusion_matrix(y_test,preds)
print("오차행렬")
print(confusion)
print("\n")
#정확도: 전체 데이터에서 맞게 분류한 것의 비율
accuracy = accuracy_score(y_test,preds)
print("정확도:",accuracy)
#정밀도:검색된 문서들중에 관련있는 문서들의 비율
#True로 판정한 것중 실제 True 인 것의 비율
precision = precision_score(y_test,preds)
print("정밀도:",precision)
#재현율:관련되 문서들 중 검색된 비율
#실제 True인 것중 True로 판정한 것의 비율
recall = recall_score(y_test,preds)
print("재현율",recall)
#F1score -recall과 precision의 조화평균
f1_score = f1_score(y_test,preds)
print("f1_score:",f1_score)
#roc_auc_score
#area under curve 의 약자로 그래프의 곡선 아래 면적
#1에 가까울 수록 좋은 성능
roc_auc = roc_auc_score(y_test,preds)
print("roc_auc:",roc_auc)=>feature 중요도 시각화
#feature의 중요도 시각화
from lightgbm import plot_importance
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10,10))
plot_importance(lgbm_wrapper,ax=ax)
6.Stacking

1)개요
=>부스팅이나 랜덤 포레스트를 예측기의 예측을 취합해서 무언가 동작(투표,확률,평균 등)을 수행하는데 예측을 취합하는 모델을 훈련시킬려고 하는 방식
=>개별 알고리즘의 예측 결과 데이터 셋을 이용해서 최종적인 메타데이터를 만들고 이 데이터를 가지고 별도의 ML 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 다시 최종 예측을 수행하는 방식
=>개별 알고리즘의 예측 결과를 가지고 훈련을 해서 최종 결과를 만들어내는 예측기(Blender)를 생성하는 방식
=>블랜더는 홀드 아웃 세트를 이용해서 학습
=>스태킹에서는 두 종류의 모델이 필요한데 하나는 개별적인 기반 모델이고 다른 하나는 기반 모델의 예측 데이터를 학습데이터로 만들어서 학습하는 최종 메타 모델
=>sklearn에서는 스태킹을 지원하지 않아서 직접 구현하거나 오픈 소스를 이용
2)스태킹 구현
=>개별 학습기:KNN, RandomForest,AdaBoost,DecisionTree
=>최종 학습기:Logistic 회귀
#윈스콘 신 유방암 데이터를 이용한 Stacking 구현
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
from lightgbm import LGBMClassifier
from sklearn.datasets import load_breast_cancer
dataset = load_breast_cancer()
X_features = dataset.data
y_label = dataset.target
X_train,X_test,y_train,y_test= train_test_split(X_features,y_label,test_size=0.2,
random_state=42)
#학습에 사용할 예측기 생성
knn_clf =KNeighborsClassifier(n_neighbors=4)
rf_clf =RandomForestClassifier(n_estimators=100,random_state=42)
dt_clf =DecisionTreeClassifier()
ada_clf =AdaBoostClassifier(n_estimators=100)
lr_final =LogisticRegression(C=10)
#개별 모델이 학습
knn_clf.fit(X_train,y_train)
rf_clf.fit(X_train,y_train)
dt_clf.fit(X_train,y_train)
ada_clf.fit(X_train,y_train)
knn_pred = knn_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
dt_pred = dt_clf.predict(X_test)
ada_pred = ada_clf.predict(X_test)
print('KNN정확도',accuracy_score(y_test,knn_pred))
print('RandomForest정확도',accuracy_score(y_test,rf_pred))
print('DecisionTree정확도',accuracy_score(y_test,dt_pred))
print('ADA정확도',accuracy_score(y_test,ada_pred))#최종 분류기가 사용할 데이터 생서
#각 분류기가 예측한 데이터를 하나의 배열로 만들어서 전치
pred = np.array([knn_pred,rf_pred,dt_pred,ada_pred])
pred = np.transpose(pred) #same as np.T
#최종 분류기 훈련
lr_final.fit(pred,y_test)
final = lr_final.predict(pred)
print("최종 분류기 정확도:",accuracy_score(y_test,final))
'Study > Machine learning,NLP' 카테고리의 다른 글
| 머신러닝(8)-실습(2) (0) | 2024.03.07 |
|---|---|
| 머신러닝(7)-실습1 (1) | 2024.03.06 |
| 머신러닝(5) - Regression(2) (0) | 2024.03.05 |
| 머신러닝(4)-Regression(1) (0) | 2024.03.04 |
| 머신러닝(3)-Classification(2) (0) | 2024.02.29 |



