1.NLP(National Language Processing)
1)개요
=> 컴퓨터가 인간의 언어를 이해하고 해석하는 것
텍스트 마이닝은 컴퓨터를 이용해서 자연어에서 의미 있는 정보를 추출하는 것
2)텍스트 분석
=>비정형 데이터 인 텍스트를 분석
=>텍스트를 단어 기반의 다수의 feature 로 추출하고 이 feature 에 단어의 빈도수와 같은 숫자를 부여해서 단어의 조합인 벡터로 표현해서 수행
3)기술 영역
=>텍스트 분류:카테고리 분류
=>감성 분석
=>텍스트 요약
=>텍스트 군집 -> 유사도 측정
4)수행 프로세스
=>텍스트 전처리
- 클렌징
- 대소문자 변경
- 특수문자 삭제
- 토큰화 작업: 단어 단위로 쪼개는 것
- 불용어 제거: 분석에서 무의미한 단어를 제거
- 어근 추출: 한글의 경우는 조사 등을 제거해서 동일한 의미를 갖는 단어를 추출
=>피처 벡터화: 숫자 피처로 변경하는 것
=>머신러닝 모델을 생성해서 학습/예측/평가
5)한글 형태소 분석(한글 어근 단위로 잘라서 품사와 함께 하나의 데이터로 만들어 주는 것)을 위한 준비
=>JDK 를 설치하고, JAVA_HOME에 jdk 설치 디렉토리 경로를 추가해주고 , PATH 라는 환경변수에 jdk의 bin이라는 디렉토리 경로를 설정
=>Windows 은 Visual C++ 재배포 패키지를 설치
=>JPype1 이라는 패키지 설치
pip install JPype1-py3
pip install JPype1
=>kolnpy 라는 패키지 설치
pip install konlpy
2.텍스트 전처리
1)텍스트 정규화
=>텍스트는 자체를 바로 피처로 만들 수 없기 때문에 사전에 텍스트를 가공하는 준비 작업이 필요
=>텍스트는 정규화 작업이 매우 중요
2)토큰화
=>문서에서 문장을 분리하는 문장 토큰화 와 문장에서 단어를 토큰으로 분리하는 단어 토큰화로 구분
- 마침표 나 개행문자(\n)등 문장의 마지막을 뜻하는 기호에 따라 분리하는 것이 일반적
-정규 표현식에 따른 문장 토큰화도 중요
-결과는 문장의 list
- nltk.sent_tokenize 함수를 이용해서 수행하는 것이 가능
=>nltk 패키지를 설치
import nltk
nltk.download('punkt')
from nltk import sent_tokenize
test_sample = '안녕하세요. 반갑습니다. 어서오세요! 환영합니다. 어서\n 오세여!'
#.이나 !,? 처럼 문장의 끝을 나타내는 기호나 \n 단위로 분할해서 list 리
sentences = sent_tokenize(text = test_sample)
print(sentences)
print(type(sentences))
=>단어 토큰화
- 문장을 단어 단위로 토큰화하는 것
- 공백 그리고 , 또는 문장의 마지막 부호를 이용해서 단어 단위로 분할
- nltk 패키지의 word_tokenize 함수를 이용해서 수행하는 것이 가능
from nltk import word_tokenize
sentence = '아름답게 아름다운 그 시절에 내가'
#.이나 !,? 처럼 문장의 끝을 나타내는 기호나 \n 단위로 분할해서 list 리
words = word_tokenize(text = sentence)
print(words)
print(type(words))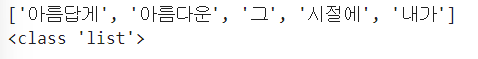
- 하나의 문장만 가지고 단어 토큰화를 하는 경우는 드물기 때문에 함수를 만들어서 문서를 문장 별로 단어 토큰화를 수행해서 토큰화를 수행해서 사용하는 경우가 많습니다.
#문서를 받아서 문장 단위로 단어 토큰화를 수행해서 리턴하는 함수
def tokenize_text(text):
sentences = sent_tokenize(text)
word_tokens = [ word_tokenize(sentence) for sentence in sentences]
return word_tokens
word_tokens = tokenize_text(test_sample)
print(word_tokens)
3)stopword(불용어) 제거
=>불용어
-분석에 큰 의미가 없는 단어
-한글의 경우는 조사가 대부분 불용어
-크롤링을 하다보면 검색어 같은 경우도 불용어에 해당하는 경우가 있음
야구와 관련 있는 기사를 가지고 워드클라우드를 그릴 경우 야구로 기사를 검색했을텐데 가장 많이 등장하는 단어는 야구일 가능성이 높습니다. 이경우 야구는 실제로는 분석의 대상이 아님
-불용어의 기준은 정해진 것이 아니고 자연어를 처리하는 개발자가 설정
-영어의 경우는 자주 등장하지만 큰 의미가 없는 단어를 nltk(179개)와 sklearn이 소유하고 있음
-한국어는 파이썬에서 제공하지 않기 때문에 직접 단어장을 만들거나 웹에서 검색해서 사용합니다.
-불용어를 제거할때는 영문의 경우는 전부 소문자로 제공되기 떄문에 소문자로 변경해서 수행
#불용어 제거 - 영문사용할때는 대소문자에 대한 부분을 고려
stop_words =nltk.corpus.stopwords.words('english')
temp = word_tokenize(sample)
result = [word for word in temp if word.lower() not in stop_words]
print(result)
4)어근 찾기
=>많은 언어에서 문법적인 요소에 따라 단어가 다양하게 변하는데 영어의 경우는 시제나 단수와 복수 등 매우 많은 조건에 따라 원래 단어가 변경됨
=>어근 찾기는 원래의 단어를 찾는 작업
=>영문에서는 Stemming 과 Lemmatization을 이용하고 한글은 형태소 분석을 이용
=>영문의 경우 nltk 패키지에서 2가지 기능을 제공
-Stemming: 원래 단어에서 일부 철자가 훼손된 어근 단어를 추출
-Lemmatization: 문법적인 요소와 의미적인 부분을 감안해서 정확한 철자로 된 어근단어를 추출, 시간은 더 걸리지만 정확
=>한글은 konlpy.tag 패키지의 Kkma, Hannanum,Okt 패키지를 이용
from konlpy.tag import Kkma
kkma = Kkma()
#문장 토큰화 - sentences
print(kkma.sentences('안녕하세요! 반갑습니다.'))
#단어 토큰화 - nouns
print(kkma.nouns('한국어의 단어별 분석'))
#품사와 함께 추출 -pos
print(kkma.pos('한국어의 단어별 분석'))
단어 토큰화는 명사만 추출합니다. 따라서 nouns만 가지고 자연어 처리를 하는 경우가 많습니다.
5)BoW(Bag of Words)
=>문서가 가지는 모든 단어를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여해서 피처값을 추출하는 방식
=>문장들에 나타난 단어들을 중복을 제거한 후 일련번호를 부여하고 그런 다음 횟수를 단어별로 기재
ex.)
문장1: 나는 야구를 좋아합니다
문장2: 나는 축구를 좋아합니다
문장3: 야구를 야구를 야구를
-- 위에서 단어 중복제거 한 후 일련번호를 부여
나는:0
야구를:1
좋아합니다:2
축구를:3
문장1:1 1 1 0
문장2:1 0 1 1
문장3:0 3 0 0
=>장점
-쉽고 빠르게 구축
-문서의 특징을 잘 나타낼 수 있습니다
=>단점
-단어의 순서를 무시하기 떄문에 문맥적인 의미가 무시됨
-단어의 개수가 많아지면 희소 행렬이 만들어질 가능성이 높아지고, 희소 행렬은 일반적으로 머신러닝 알고리즘의 수행 시간과 예측 성능을 떨어뜨리므로 희소 행렬을 위한 특별한 작업이 필요
=>희소 행렬 표현 방식
-COO 방식: 0이 아닌 데이터만 별도의 데이터 배열에 저장하고 그 데이터가 가르키는 행과 열의 위치를 사용하는 방식
# COO 방식 - 0 이 아닌 데이터의 좌표를 기록하는 방식
import numpy as np
dense = np.array([[3,0,1],[0,2,0]])
#0이 아닌 데이터의 가중치와 행과 열 번호를 기록
from scipy import sparse
sparse_coo = sparse.coo_matrix(([3,1,2],(np.array([0,0,1]),np.array([0,2,1]))))
print(sparse_coo)
#복원
print(sparse_coo.toarray())단점) 데이터가 많아지면 중복되는 위치가 발생
-CSR 방식: 반복적으로 등장하는 위치를 한 번만 표현하기 위해서 시작위치를 가리키는 방식
ex.)
[
[0,0,1,0,0,5],
[1,4,0,3,2,5],
[0,6,0,3,0,0],
[2,0,0,0,0,0],
[0,0,0,7,0,8],
[1,0,0,0,0,0]
]
데이터 배열 : [1,5,1,4,3,2,5,6,3,2,7,8,1]
행 인덱스:[0,0,1,1,1,1,1,2,2,3,4,4,5] =>각 행의 시작 위치만 기억 =>[0,2,7,9,10,12,13(총개수)]
열 인덱스:[2,5,0,1,3,4,51,3,0,3,5,0]
from scipy import sparse
dense2 = np.array([[0,0,1,0,0,5],
[1,4,0,3,2,5],
[0,6,0,3,0,0],
[2,0,0,0,0,0],
[0,0,0,7,0,8],
[1,0,0,0,0,0]])
# 0 이 아닌 데이터 추출
data2 = np.array([1, 5, 1, 4, 3, 2, 5, 6, 3, 2, 7, 8, 1])
# 행 위치와 열 위치를 각각 array로 생성
row_pos = np.array([0, 0, 1, 1, 1, 1, 1, 2, 2, 3, 4, 4, 5])
col_pos = np.array([2, 5, 0, 1, 3, 4, 5, 1, 3, 0, 3, 5, 0])
# COO 형식으로 변환
sparse_coo = sparse.coo_matrix((data2, (row_pos,col_pos)))
# 행 위치 배열의 고유한 값들의 시작 위치 인덱스를 배열로 생성
row_pos_ind = np.array([0, 2, 7, 9, 10, 12, 13])
# CSR 형식으로 변환
sparse_csr = sparse.csr_matrix((data2, col_pos, row_pos_ind))
print('COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_coo.toarray())
print('CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_csr.toarray())
- 카운트 기반의 벡터화 : 단어의 등장 횟수에 따른 벡터화
-TD-IDF (Term Frequency - Inverse Document Frequency0
카운트 벡터화에서 단순하게 카운트 만을 가지고 벡터화를 수행하면 자주 등장하는 단어가 중요한 단어가 되는데 이럴 경우 영문에서 a 나 an처럼 특별한 의미는 없는 자주 사용하는 단어가 중요한 단어가 되버립니다.
이를 보완하기 위해서 하나의 문장에서 자주 사용하는 단어에 가중치를 두고 여러 문장에서 등장하는 단어는 패널티를 부여하는 방식이 TD-IDF 방식입니다.
가중치 계산 방식
개별문서에서 등장하는 빈도 * log(전체문서개수/단어가등장하는문서개수)
sklearn 패키지의 CounterVectorize 클래스가 count 기반의 벡터화를 구현한 클래스
파라미터
max_df:최대 등장 횟수
min_df: 최소 등장 횟수
max_features: 추출하고자 하는 단어의 개
stop_words:불용어
n_gram_range: 범위 설정 - 2개 이상의 단어를 묶어서 하나의 단어로 처리하기 위해서
analyzer: 피처 추출 단위로 word나 character
token_pattern:토큰화를 수행하는 정규 표현식 패턴을 지정
tokenizer:토큰화를 수행할 함수를 지정
corpus(corpora):자연어 처리를 위해서 특정한 목적을 가지고 언어의 표본을 추출한 집합
=>sklearn API 를 이용한 단어 벡터화(CountVerctorizer)
corpus =["코로나 거리두기와 코로나 상생 지원금 문의입니다.",
"지하철 운행 시간과 지하철 요금 문의입니다",
"지하철 승강장 문의입니다",
"택시 승강장 문의입니다"]
#print(corpus)
#CountVectorizer: 등장 횟수만으로 가중치를 표현
from sklearn.feature_extraction.text import CountVectorizer
cvect = CountVectorizer()
#기존 문자열을 가지고 훈련
#문서에 등장한 모든 단어를 indexing만 수행
cvect.fit(corpus)
#corpus 의 문장을 벡터화
#앞에 숫자 0은 행번호이고, 뒤의 숫자는 단어의 인덱스이고 세번째 숫자가 등장 횟수
dtm = cvect.transform(corpus)
print(dtm)
#각 단어 확인
print(cvect.vocabulary_)
#단어를 인덱스 순으로 확인
vocab = cvect.get_feature_names_out()
print(vocab)
#원핫인코딩과 다른 점은 하나의 행에 0이 아닌 값이 여러 개 있고 0 이나 1아닌 값이 존재
#문장들을 피처화
import pandas as pd
df_dtm = pd.DataFrame(dtm.toarray(),columns=vocab)
print(df_dtm)
=>TfidfVectorizer 이용 :문장 내에서 여러 번 등장하면 가중치를 부여하고 여러 문장에서 등장하면 패널티 부과
#TfidfVectorizer:문장 내에서 여러 번 등장하면 가중치를 부여하고 여러 문장에서 등장하면 패널티 부과
corpus =["코로나 거리두기와 코로나 상생 지원금 문의입니다.",
"지하철 운행 시간과 지하철 요금 문의입니다",
"지하철 승강장 문의입니다",
"택시 승강장 문의입니다"]
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfv = TfidfVectorizer()
tfidfv.fit(corpus)
print(tfidfv.vocabulary_)
print("="*100)
print(tfidfv.transform(corpus).toarray())
print("="*100)
print(tfidfv.fit_transform(corpus).toarray())
#문장들을 피처화
vocab = tfidfv.get_feature_names_out()
df_dtm =pd.DataFrame(tfidfv.transform(corpus).toarray(),columns=vocab)
print(df_dtm)
[Pros]
1. CountVectorizer가 갖는 단점 보완(자주 등장하는 단어의 가중치 축소)
2. 0과 1사이의 수치로 크면 자주, 작으면 덜 자주 등장한다는 것을 직관적으로 알 수 있음
[Cons]
1. 데이터 양이 크고 많은 경우, BoW의 length가 커 sparse한 벡터 표현이 만들어질 가능성이 큼
-> 전처리, stop_words, max_features 등을 이용해 잘 처리해야함
2. 차원이 너무 큰 벡터가 만들어질 가능성 존재
3.WordCloud
1)개요
=>TagCloud 라고도 하는데 메타 데이터에서 얻어진 태그들을 분석해서 중요도 나 인기도 등을 고려해서 시각적으로 늘어 놓아 표시한 것
=>각 태그들은 등장 횟수(중요도) 등에 따라 글자의 크기나 색상을 달리해서 표현
=>여러가지 패키지가 존재
tagcloud 나 wordcloud 패키지를 이용해서 만들 수 가 있습니다.
2)TagCloud 을 이용한 워드 클라우드 생성
=>사용 준비
-패키지 설치: pip install pytagcloud,pygame,simplejson
-한글 폰트를 사용하고자 하면 pytagcloud 가 설치된 디렉토리의 fonts 디렉토리에 한글 폰트 파일을 복사하고 Fonts.json파일에 등록
=>작업 순서
- 단어들의 list 생성
-Collections 모듈의 Counter ( 딕셔너리 형태로 각 데이터의 개수를 저장할 수 있는 클래스)를 이용해서 각 단어의 개수를 가지는 Counter 객체를 생성
-필요한 경우에는 most_common 메서드를 이용해서 단어와 단어별 개수를 갖는 list 객체 생성
-pytagcloud.make_tags(튜플의 list, maxsize= 글자크기의 최대 사이즈)를 호출하면 워드클라우드를 그릴 수 있는 dict의 list 가 생성됩니다
-pytagcloud.create_tag_image(dict의 list, 그림 파일 경로,size = (너비, 높이), fontname='폰트이름',rectangular=사각형 출력여부)
=>작업
#그리고자 하는 단어의 list 를 생성
import pytagcloud
import collections
nouns = list()
nouns.extend(['불고기' for t in range(8)])
nouns.extend(['비빔밥' for t in range(7)])
nouns.extend(['김치찌개' for t in range(7)])
nouns.extend(['돈까스' for t in range(6)])
nouns.extend(['순두부백반' for t in range(6)])
nouns.extend(['짬뽕' for t in range(6)])
nouns.extend(['짜장면' for t in range(6)])
nouns.extend(['삼겹살' for t in range(5)])
nouns.extend(['초밥' for t in range(5)])
nouns.extend(['우동' for t in range(5)])
#데이터 개수 세기
count = collections.Counter(nouns)
print(count)
#필요한 개수만큼 추출
tag2 = count.most_common(100)
#태그 목록 만들기
taglist = pytagcloud.make_tags(tag2, maxsize=50)
print(taglist)
#태그 클라우드 생성
pytagcloud.create_tag_image(taglist, 'wordcloud.png', size=(900, 600), fontname='Korean', rectangular=False)

import matplotlib.pyplot
import matplotlib.image
img = matplotlib.image.imread('wordcloud.png')
imgplot = matplotlib.pyplot.imshow(img)
matplotlib.pyplot.show()
3)wordcloud 패키지를 이용해서 이미지 워드클라우드 그리기
=>패키지:wordcloud
# 워드클라우드를 만들 텍스트 생성
text =''
text = ''
for t in range(8):
text = text + 'Python '
for t in range(7):
text = text + 'Java '
for t in range(7):
text = text + 'C '
for t in range(8):
text = text + 'JavaScript '
for t in range(5):
text = text + 'C# '
for t in range(3):
text = text + 'Ruby '
for t in range(2):
text = text + 'scala '
for t in range(6):
text = text + 'PHP '
for t in range(3):
text = text + 'Swift '
for t in range(3):
text = text + 'Kotlin '
for t in range(3):
text = text + '자바'
#제거할 단어 설정
stopwords = set(STOPWORDS)
stopwords.add("Kotlin")
#워드 클라우드 만들기
#한글을 출려갛고자 하는 경우는 font_path 에 한글폰트 파일 경로를 설정
wordcloud = WordCloud(background_color='white', max_words=2000, mask=mask,font_path="C:\\Users\\User\\anaconda3\\Lib\\site-packages\\pytagcloud\\fonts\\NanumBarunGothic.ttf",
stopwords = stopwords)
wordcloud = wordcloud.generate(text)
print(wordcloud.words_)
#워드클라우드에 화면에 출력
plt.figure(figsize=(12,12))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
4)동아일보 기사를 검색해서 텍스트를 크롤링해서 워들 클라우드로 그리기
=>동아일보 기사 검색 URL
https://www.donga.com/news/search?query=%ED%96%84%EB%B2%84%EA%B1%B0&check_news=91&more=1
뉴스|검색결과|동아일보
... 식품취급업소에서 조리·제공되는 김밥, 핫바, 떡볶이, 햄버거 등 국민이 많이 섭취하는 조리식품 30여개를 수거해 식중독균 오염 여부도 검사할 예정이다.이소라 시민건강국장은 ... 2024-03-10
www.donga.com
url = https://www.donga.com/news/search
파라미터 -p: 시작하는 기사번호(한페이지에 10개의 기사가 보여짐)
query:검색어
check_news
sorting
search_date
?query=%ED%96%84%EB%B2%84%EA%B1%B0&check_news=91&more=1
=>기사를 검색한 후 맨 처음 할 작업은 전체 기사의 개수를 파악하는 것
#정적 HTML 가져오기
from bs4 import BeautifulSoup
import requests
from urllib.parse import quote
keyword = input('검색어')
#url 생성
#?뒤 파라미터들은 반드시 UTF-8로 인코딩 되어야합니
target_url="http://www.donga.com/news/search?query="+quote(keyword)+"&check_news=91&more=1"
#정적 HTML 가져오기
source_code_from_URL =requests.get(target_url)
print(source_code_from_URL.text)bs=BeautifulSoup(source_code_from_URL.text,"html.parser")
cnt = bs.select("button > a > span")
print(cnt)
#전체 기사 개수를 찾아옴
#화면에서도 보이고 html 내에서도 getText 를 하면 데이터를 가져오지 못하는 경우
#이 경우는 대부분은 ajax
count = int(cnt[1].getText())
print(count)#읽어올 데이터의 개수 입력받기
#입력받은 숫자를 가지고 읽어올 페이지의 개수 생성
#한 페이지에 기사는 10개
page_num =int(int(input( "읽어올 데이터의 개수:"))/10 + 1)
print(page_num)
#파싱한 내용을 저장할 텍스트 파일 생성
output_file = open(keyword + ".txt", 'w', encoding = 'utf8')
#기사 링크를 한 곳에 저장하기
for i in range(page_num):
current_page_num = 1 + i * 10
target_URL = "https://www.donga.com/news/search?p=" + str(current_page_num)+"&query=" + quote(keyword) + "&check_news=91&sorting=1&search_date=1&v1=&v2=&more=1"
#print(target_URL)
source_code_from_URL = requests.get(target_URL)
bs = BeautifulSoup(source_code_from_URL.text, 'html.parser')
texts = bs.select('article > div > p')
for text in texts:
output_file.write(text.getText())
output_file.close() #항상 파일은 열면 닫아야 함.까지 하면 메모장 파일 에 keyword.txt 파일 생성
=>이걸 형태소 분석
from konlpy.tag import Kkma
kkma = Kkma()
open_text_file = open(keyword+'.txt','r',encoding='utf8')
text = open_text_file.read()
#명사만 추출
nouns = kkma.nouns(text)
open_text_file.close()명사만 추출 할때 영문의 경우는 대부분은 공백을 기준으로 Tokenizer를 하고 불용어를 제거
한글의 경우는 형태소 분석을 해서 명사만 추출하고 불용어을 제
#wordcloud 그리기
data = ko.vocab().most_common(150)
wordcloud = WordCloud(font_path = "C:\\Users\\User\\anaconda3\\Lib\\site-packages\\pytagcloud\\fonts\\NanumBarunGothic.ttf",
background_color='white').generate_from_frequencies(dict(data))
plt.imshow(wordcloud)
plt.show()
4.감성 분석
1)개요
=>문서의 주관적인 감성/의견/감정/기분 등을 파악하기 위한 방법
=>소셜 미디어, 여론 조사 온라인 리뷰 피드백 등 다양한 분야에서 활용 이를 크롤링을 통해서 얻어낼수 있음
=>문서 내 텍스트가 나타내는 여러가지 주관적인 단어와 문맥을 기반으로 감성 수치를 계산
=>긍정 감성 지수와 부정 감성 지수를 같이 구해서 합산한 후 긍정인지 부정인지를 판별
=>지도 학습과 비지도학습 모두 가능
2)나이브 베이즈 분류기
=>훈련을 하지 않고 통계적 확률에 근거한 여러 알고리즘을 이용하는 분류기
=>모든 특성 값은 서로 독립이라는 가정하에서 출발
=>장점
- 지도학습 환경에서 매우 효율적으로 훈련
- 분류에 필요한 파라미터를 추정하기 위한 트레이닝 데이터의 양이 적어도 가능
=>API 는 nltk.NaiveBayesClassifier
이 분류기를 이용해서 훈련을 하면 각 단어가 긍정 과 부정에 어떤 확률을 가지고 있는지 훈련
=>영문 감성 분석
from nltk.tokenize import word_tokenize
import nltk
### 훈련 데이터 만들기
train = [('i like you', 'pos'),
('i do not like you', 'neg'),
('i hate you', 'neg'),
('i do not hate you', 'pos'),
('i love you', 'pos'),
('I do not love you', 'neg')]
#train 데이터의 모든 것을 순차적으로 sentence에 대입한 후
#sentence 의 첫번째 데이터를 공백을 기준으로 분할해서 word 에 순차적으로 할당 한 후
all_words = set(word.lower() for sentence in train
for word in word_tokenize(sentence[0]))
all_words=>단어 토큰화 후 나이브 베이즈 분류기로 훈련
#단어 토큰화
#train의 모든 데이터를 x에 대입한 후
#튜플을 생성하는데 뒤는 감성을 그대로 저장하고
#앞은 all_words 모든 단어와 존재 여부를 딕셔너리로 가지고 있습니
t = [({word: (word in word_tokenize(x[0])) for word in all_words}, x[1])
for x in train]
print(t)
#나이브 베이즈 분류기를 이용해서 감성분석을 하기 위해서는 각 문장이 단어의 존재 여부를 가진 dict
#와 감성을 나타내는 텍스트나 숫자의 튜플로 변환 되어야 합니다.
classifier = nltk.NaiveBayesClassifier.train(t)
classifier.show_most_informative_features()
#예측 - 예측할 때 문장을 바로 대입하는 것이 아닌 문장을 feature 로 변환해서 대입
test_sentence ='I do not like Jessica'
test_sent_features = {word.lower():(word in word_tokenize(test_sentence.lower()))
for word in all_words}
#테스트 문장을 피처화
print(test_sent_features)
print(classifier.classify(test_sent_features))데이터를 계속 쌓아나가야만 올바른 판단을 할 수 있음
만약 위의 test_sentence가 올바르게 판단했다 싶으면 train 데이터에 추가를 해서 다시 학습시킴
3)한글 감성 분석
#샘플 데이터 생성
train = [('나는 당신을 사랑합니다.','pos'),
('나는 당신을 사랑하지 않습니다.','neg'),
('나는 당신을 만나는 것이 지루합니다.','neg'),
('나는 노는 것이 좋습니다.','neg')]#한글을 공백을 기준으로 토큰화
all_words = set(word.lower() for sentence in train
for word in word_tokenize(sentence[0]))
#동일한 어근을 갖는 사랑하지 와 사랑합니다 가 다른 단어로 구
print(all_words)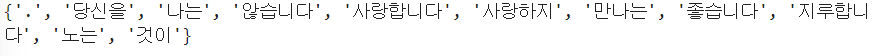
동일한 어근인 사랑합니다, 사랑하지가 다른 단어로 구분 되서 한글은 영문에서 사용하는 토큰나이저를 사용하면 안됩니다. 한글은 형태소 분석을 수행해야 합니다.
#한글 형태소 분석 - 단어 단위로 분할하고 품사까지 묶기
from konlpy.tag import Twitter
twitter = Twitter()
#형태소 분석을 해서 단어 와 품사 사이에 /를 추가해서 구분해주는 함수
def tokenize(doc):
return ["/".join(t) for t in twitter.pos(doc,norm=True,stem=True)]
#훈련 데이터의 문장을 하나씩 함수에 대입후 결과를 list 묶기
train_docs = [(tokenize(row[0]),row[1]) for row in train]
print(train_docs)
다른 형태소 분석기를 사용해도 되는데 품사를 같이 리턴하는 함수를 이용하는 것이 좋습니다. 품사를 제외하고 만든 분석기 보다 품사를 포함시키는 것이 성능이 우수하다고 알려져 있습니다.
#감성을 제외하고 단어만 추출해서 list 만들기
tokens = [ t for d in train_docs for t in d[0]]
print(tokens)
=>나이브베이즈 감성 분류기 생성: 단어의 존재 여부에 따라 pos 와 neg의 확률을 구해줍니다
#예측 - 한글은 형태소 분석을 해서 대입
#예측
test_sentence = [('나는 당신을 만나는 것이 싫습니다.')]
#형태소 분석
test_docs = twitter.pos(test_sentence[0])
print(test_docs)
#단어 사전에 있는 단어의 존재 여부를 생성
test_sent_features = {word :(word in tokens) for word in test_docs}
print(test_sent_features)
print()
#예측
print(classifier.classify(test_sent_features))
불용어는 사전을 만들기 전에 제거해야합니다. '.' 나 '을'같은 경우는 감정에 영향을 안주기 때문에 지우는게 맞습니다.
조사나 punctuation 의 포함 여부를 결정
'Study > Machine learning,NLP' 카테고리의 다른 글
| NLP(3)-문서 군집화,연관분석,추천시스템 (0) | 2024.03.14 |
|---|---|
| NLP(2) - 실습 (0) | 2024.03.14 |
| 머신러닝(10)-군집 (0) | 2024.03.11 |
| 머신 러닝(9)-차원 축소 (0) | 2024.03.07 |
| 머신러닝(8)-실습(2) (0) | 2024.03.07 |



